
STL简介
C++ STL(Standard Template Library),即C++标准模板库,又称C++泛型库,它在std命名空间中定义了常用的数据结构和算法,使用起来十分方便。
STL提供三种类型的组件:容器、迭代器和算法,它们都支持泛型程序设计标准。
容器主要有两类:顺序容器和关联容器。
顺序容器(vector、list、queue和string等)是一系列元素的有序集合。
关联容器(set、multiset、map和multimap)包含查找元素的键值。
迭代器的作用是遍历容器。
STL算法库包含四类算法:排序算法、不可变序算法、变序性算法和数值算法。
vector向量容器
介绍:
1.vectro向量容器不但能像数组一样对元素进行随机访问,还能在尾部插入元素,是一种简单、高效的容器,完全可以代替数组。
2.值得注意的是,vector是具有内存自动管理的功能,对于元素的插入和删除,可动态调整所占的内存空间。
内容
1.头文件及先决知识
#include<vector>
vector容器的下标是从0开始计数
vector容器有两个重要的方法,begin()和end()。(两者都为指针类型)
begin()返回的是首元素位置的迭代器;
end()返回的是最后一个元素的下一元素位置的迭代器。
2.创建vector对象
创建vector对象常用的有三种形式。
(1)不指定容器的元素个数,如定义一个用来存储整型的容器:
vector<int>v;
(2)创建时,指定容器的大小,如定义一个用来存储10个double类型元素的向量容器:
vector<double>v(10);
(3)创建一个具有n个元素的向量对象,每个元素具有指定的初始值:
vector<double>v(10,8.6);
上述语句定义了v向量容器,共有10个元素,每个元素的值时8.6。
3.尾部元素扩张
通常使用push_back()对vector容器在尾部追加新元素。尾部追加元素,vector容器会自动分配新内存空间。课对空的vector对象扩张,也可对已有元素的vector对象扩张。
下列代码将2,7,9三个元素从尾部添加到v容器中,这样,v容器中就有三个元素,其值依次是2,7,9。
1 |
|
4.下标方式访问vector元素
类似数组的访问方式:
1 |
|
5.用迭代器访问vector元素
迭代器的类型一定要与它要遍历的vector对象的元素类型一致。
1 |
|
6.元素的插入
insert()方法可以在vector对象的任意位置前插入一个新的元素,同时,vector自动扩张一个元素空间,插入位置后的所有元素依次向后挪动一个位置。
要注意的是,insert()要求插入的位置,是元素的迭代器位置,而不是元素的下标。
1 |
|
7.元素的删除
erase()方法可以删除vector中迭代器所指的一个元素或一段区间中的所有元素。
clear()方法则一次性删除vector中的所有元素。
1 |
|
运行结果:
0 1 3 4 5 6 7 8 9
0 6 7 8 9
0
8.使用reverse反向排列算法
reverse反向排列算法,需要头文件:
#include<algorithm> //测试发现不需要也可以?!难道在vector里面了?
reverse算法可将向量中某段迭代器区间元素反向排列:
1 |
|
输出结果:
9 8 7 6 5 4 3 2 1
9.使用sort算法对象量元素排序
sort算法,需要头文件:
#include<algorithm>
a.sort算法要求使用随机访问迭代器进行排序,在默认的情况下,对向量元素进行升序排列
1 |
|
b.设计排序比较函数,然后,把这个函数指定给sort算法,那么sort就根据这个比较函数指定的排序规则进行排序。
1 |
|
运行结果:
0 1 2 3 4 5 6 7 8 9
9 8 7 6 5 4 3 2 1 0
10.向量的大小
使用size()方法可以返回向量的大小,即元素的个数
使用empty()方法返回向量是否为空
1 |
|
运行结果:
10
0
1
11.resize()方法
void resize (size_type n);
void resize (size_type n, value_type val);
resize函数重新分配大小,改变容器的大小,并且创建对象
当n小于当前size()值时候,vector首先会减少size()值 保存前n个元素,然后将超出n的元素删除(remove and destroy)
当n大于当前size()值时候,vector会插入相应数量的元素 使得size()值达到n,并对这些元素进行初始化,如果调用上面的第二个resize函数,指定val,vector会用val来初始化这些新插入的元素
string基本字符系列容器
介绍
C语言只提供了一个char类型用来处理字符,而对于字符串,只能通过字符串数组来处理,显得十分不便。C++STL提供了string基本字符系列容器来处理字符串,可以把string理解为字符串类,它提供了添加、删除、替换、查找和比较等丰富的方法
内容
1.先决知识
虽然使用vector<char>这样的向量也可以处理字符串,但功能比不上string。向量的元素类型可以是string,如vector<string>这样的向量,实际上就类似于C语言中的字符串数组
头文件:
#include<string>
2.创建sring对象
下面这条语句创建了字符串对象s,s是一个空字符串,其长度为0:
1 |
|
运行结果:
0
3.给string对象赋值
a.直接给字符串对象赋值
1 |
|
运行结果:
hello,C++STL.
b.把字符指针赋给一个字符串对象
1 |
|
运行结果(先从键盘上输入“hello,string.”):
hello,string.
4.从string对象尾部添加字符
a.直接采用“+”操作符
1 |
|
运行结果:
abc123
b.采用append()方法
1 |
|
运行结果:
abc123
5.给string对象插入字符
可以使用insert()方法把一个字符插入到迭代器位置之前
1 |
|
运行结果:
1p23456
6.访问string对象的元素
一般使用下标方式随机访问string对象的元素,下标是从0开始计数的。另外,string对象的元素是一个字符(char)
1 |
|
运行结果:
a
0
7.删除string对象的元素
a.清空一个字符串,则直接给它赋空字符串即可
b.使用erase()删除迭代器所指的那个元素或一个区间中的所有元素
1 |
|
运行结果:
abc123456
3456
0
8.返回string对象长度
a.采用length()方法可返回字符串的长度
b.采用empty()方法,可返回字符串是否为空。如果字符串为空,则返回逻辑真,即1,否则,返回逻辑假,即0.
1 |
|
运行结果:
9
1
9.替换string对象的字符
使用replace()方法可以很方便地替换string对象中的字符,replace()方法的重载函数相当多,常用的只有一两个
1 |
|
运行结果:
abcgood456
10.搜索string对象的元素或子串
采用find()方法可查找字符串中的第一个字符元素(char,用单引号界定)或者子串(用双引号界定),如果查到,则返回下标值(从0开始计数),如果查不到,则返回4294967295.
find()方法有很多重载函数
1 |
|
运行结果:
0
0
0
4
4294967295
11.string对象的比较
string对象可与使用compare()方法与其他字符串相比较。
如果它比对方大,则返回1;
如果它比对方小,则返回-1;
如果它与对方相同(相等),则返回0。
1 |
|
运行结果:
1
0
-1
12.用reverse反向排序string对象
采用reverse()方法可将string对象迭代器所指向的一段区间中的元素(字符
反向排序。
头文件:#include<algorithm>
1 |
|
运行结果:
987654321
13.string对象作为vector元素
string对象可以作为vector向量的元素,这种用法,类似于字符串数组。
1 |
|
运行结果:
Jack
Mike
Tom
J
M
3
14.string类型的数字化处理
在ACM竞赛中,常常需要将读入的数字的每位分离出来,如果采用取余的方法,花费的时间就会太长,这时候,我们可以将读入的数据当成字符串来处理,这样就方便、省时多了
1 |
|
运行结果:
24
15.string对象与字符数组互操作
1 |
|
运行结果(从键盘输入“abc123”后回车):
abc123
abc123
abc123
abc123
16.string对象与sscanf函数
在C语言中,sscanf函数很管用,它可以把一个字符串按你需要的方式分离出子串,甚至是数字。
1 |
|
运行结果:
abc 123 pc
1 2 3
4 5 6
set集合容器
介绍
1.set集合容器实现了红黑树(Red-Black Tree)的平衡二叉树检索树的数据结构,在插入元素时,它会自动调整二叉树的排列,把该元素放到适当的位置,以确保每个子树根结点的键值大于左子树所有节点的键值,而小于右子树所有节点的键值;
2.另外,还得确保根结点左子树的高度与右子树的高度相等,这样,二叉树的高度最小,从而检索速度最快。
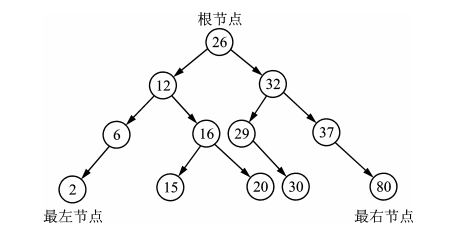
3.要注意的是,它不会重复插入相同键值的元素,二采区忽略处理
4.平衡二叉检索树的检索使用中序遍历算法,检索效率高于vector、deque和list等容器。另外,采用中序遍历算法可以将键值由小到大遍历出来,所以,可以理解为二叉检索树在插入元素是,就会自动将元素按键值从小到大的顺序排列。
5.对于set容器中的键值,不可直接去修改。因为如果把容器中的一个键值修改了,set容器会根据新的键值旋转子树,以保证新的平衡,这样,修改键值很可能就不在原先那个位置上了。换句话来说,狗仔set集合的主要目的就是为了快速检索。
6.multiset(多重集合容器)、map(映照容器)和multimap(多重映照容器)的内部结构也是平衡二叉树
内容
1.先决知识
头文件:
#include<set>
2.创建set集合对象
创建set对象时,需要指定元素的类型
1 |
|
3.元素的插入与中序遍历
1.采用insert()方法把元素插入集合中去,插入的具体规则在默认的比较规则下,是按元素值由小到大插入,如果自己指定了比较规则函数,则按自定义比较规则函数插入。
2.使用前向迭代器对集合中序遍历,其结果正好是元素排序的结果。
1 |
|
运行结果:
1 6 8 12
4.元素的反向遍历
使用反向迭代器reverser_iterator可以反向遍历集合,输出的结果正好是几何元素的方向排序结果。它需要用到rbegin()和rend()两个方法,它们分别给出了反向遍历的开始位置和结束位置。
1 |
|
运行结果:
12 8 6 1
5.元素的删除
与插入元素的处理一样,集合具有高效的删除处理功能,并自动重新调整内部的红黑树的平衡
erase()方法删除迭代器位置元素、等于某键值的元素、一个区间上的元素
clear()清空
注意:vector容器重载了+,而set容器没有,故vector可以it+n,set不能,只能++
1 |
|
运行结果:
12 8 1
0
6.元素的检索
使用find()方法对集合进行搜索,如果找到查找的键值,则返回该键值的迭代器位置,否则,返回集合最后一个元素后面的一个位置,即end()。
1 |
|
运行结果:
6
not find it
7.自定义比较函数
使用insert()将元素插入到集合中去的时候,集合会根据设定的比较函数将该元素放到该放的节点上去。在定义集合的时候,如果没有指定比较函数,那么采用默认的比较函数,即按键值由小到大的顺序插入元素。在很多情况下,需要自己编写比较函数。
(1)如果元素不是结构体,那么可以编写比较函数。由大到小输出
1 |
|
运行结果:
12 8 6 1
(2)如果元素时结构体,那么,可以直接把比较函数卸载结构体内。
1 |
|
运行结果:
Jack:80.5
Nacy:60.5
Tomi:20.5
multiset多重集合容器
介绍
multiset与set一样,也是使用红黑树来组织元素数据的,唯一不同的是,multiset允许重复的元素键值插入,而set则不允许
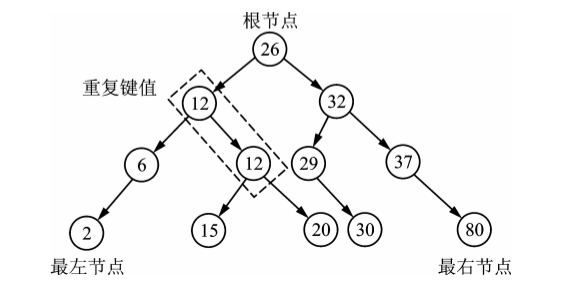
内容
1.先决知识
头文件;
#include<set>
2.multiset元素的插入
1 |
|
运行结果:
111
123
123
aaa
abc
3.multiset元素的删除
a.采用erase()方法可以删除multiset对象中的某个迭代器位置上的元素、某段迭代器区间中的元素、键值等于某个值的所有重复元素,并返回删除元素的个数。
b.采用clear()方法可以清空元素。
1 |
|
运行结果:
111
123
123
aaa
abc
Total deleted : 2
all elements after deleted :
111
aaa
abc
4.查找元素
使用find()方法查找元素
如果找到,则返回元素的迭代器位置(如果该元素存在重复,则返回第一个元素重复元素的迭代器位置);
如果没有找到,则返回end()迭代器位置。
1 |
|
运行结果:
123
not find it
map映照容器
介绍
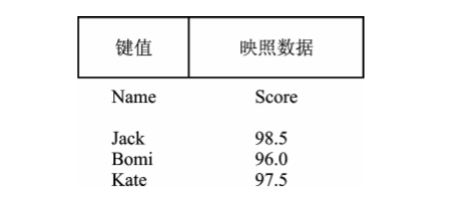
map映照容器的元素数据时由一个键值和一个映照数据组成的,键值与映照数据之间具有一一映照的关系。
map映照容器的数据结构也是采用红黑树来实现的,插入元素的键值不允许重复,比较函数只对元素的键值进行比较,元素的各项数据可通过键值检索出来。由于map与set采用的都是红黑树的数据结构,所以,用法基本相似。
内容
1.先决知识
头文件;
#include<map>
2.map创建、元素插入和遍历访问
创建map对象,键值与映照数据的类型由自己定义。在没有指定比较函数时,元素的插入位置是按键值由小到大插入到红黑去的,这点和set一样。
1 |
|
运行结果:
Bomi : 96
Jack : 98.5
Kate : 97.5
3.删除元素
与set容器一样,map映照容器的erase()删除元素函数,可以删除某个迭代器位置上的元素、等于某个键值的元素、一个迭代器区间上的所有元素,当然,也可使用clear()方法清空map映照容器。
1 |
|
运行结果:
10 : x
25 : m
30 : a
4.元素反向遍历
可以使用反向迭代器reverse_iterator反向遍历map映照容器中的数据,它需要rbegin()方法和rend()方法指出反向遍历的起始位置和终止位置。
1 |
|
运行结果:
30 : a
28 : k
25 : m
10 : x
5.元素的搜索
使用find()方法来搜索某个键值,如果搜索到了,则返回该键值所在的迭代器位置,否则,返回end()迭代器位置。
1 |
|
运行结果:
28 : k
6.自定义比较函数
将元素插入到map中去的时候,map会根据设定的比较函数将该元素放到该放的节点上去。
在定义map的时候,如果没有指定比较函数,那么采用默认的比较函数,即按键值由小到大顺序插入元素。
(1)如果元素不是结构体,那么,可以编写比较函数。
1 |
|
运行结果:
30 : a
28 : k
25 : m
10 : x
(2)如果元素是结构体,那么,可以直接把比较函数写在结构体内。
1 |
|
运行结果:
10 : Bomi 80
30 : Peti 66.5
25 : Jack 60
multimap多重映照容器
介绍
multimap与map基本相同,唯独不同的是,multimap允许插入重复的元素。由于允许重复键值存在,所以,multimap的元素插入、删除、查找都与map不相同
内容
1.先决条件
头文件:
#include<map>
2.multimap对象创建、元素插入
可以重复插入元素,插入元素需要使用insert()方法。
1 |
|
运行结果:
Jack : 300.5
Jack : 306
Kity : 200
Memi : 500
3.元素的删除
删除操作采用erase()方法,可删除某个迭代器位置上的元素、等于某个键值的所有重复元素、一个迭代器区间上的元素,返回删除键值的个数。(删除没有的键值等于不删除任何东西)
使用clear()方法可将multimap容器中的元素清空。
因为有重复的键值,所以,删除操作会将要删除的键值一次性从multimap中删除。
1 |
|
运行结果:
Jack : 300.5
Jack : 306
Kity : 200
Memi : 500
the elements after deleted:
Kity : 200
Memi : 500
4.元素的查找
由于multimap存在重复的键值,所以find()方法只返回重复键值中的第一个元素的迭代器位置,如果没有找到该键值,则返回end()迭代器位置。
1 |
|
运行结果:
all of the elements:
Jack : 300.5
Jack : 306
Kity : 200
Memi : 500
the searching result:
Jack 300.5
not find it
deque双端队列容器
介绍
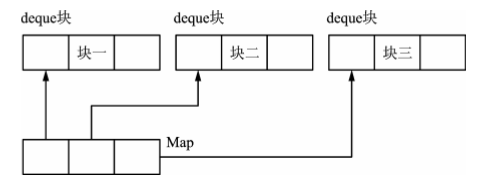
deque双端队列容器与vector一样,采用线性表顺序存储结构。但与vector唯一不同的是,deque采用分块的线性存储结构来存储数据,每块的大小一般为512字节,称为一个deque块,所有deque块使用一个Map块进行管理,每个Map数据项纪录各个deque块的首地址。这样一来deque块在头部和尾部都可插入和删除元素,而不需移动其他元素(使用push_back()方法在尾部插入元素,会扩张队列;而使用push_front()方法在首部插入元素和使用insert()方法在中间插入元素,只是将原位置上的元素值覆盖,不会增加新元素)。一般来说,当考虑到容器元素的内存分配策略和操作的性能时,deque相对于vector更有优势。
内容
1.先决条件
头文件:
#include<deque>
2.创建deque对象
创建deque对象的方法通常有三种。
(1)创建没有任何元素的deque对象,如:
deque<int> d;
deque<float> dd;
(2)创建具有n个元素的deque对象,如:
deque<int> d(10);//创建具有19个整型元素的deque对象d
(3)创建具有n个元素的deque对象,并赋初值,如:
deque<int> d(10,8.5);
3.插入元素
(1)使用push_back()方法从尾部插入元素,会不断扩张队列。
1 |
|
运行结果:
1 2 3
(2)从头部插入元素,不会新增新元素,只将原有的元素覆盖。
即原有队列长度不变,头部插入相当于强行压入元素,显然,多的元素从尾部出队列(形象理解)
1 |
|
运行结果:
20 10 1
(3)从中间插入元素,不会增加新元素,只将原有的元素覆盖
1 |
|
运行结果:
1 88 2
4.前向遍历
(1)以数组方式遍历
1 |
|
运行结果:
1 2 3
(2)以前向迭代器的方式遍历。
1 |
|
5.反向遍历
采用反向迭代器对双端队列容器进行反向遍历
1 |
|
运行结果:
3 2 1
6.删除元素
可以从双端队列容器的首部、尾部、中部删除元素,并可以清空双端队列容器。
(1)采用pop_front()方法从头部删除元素
1 |
|
运行结果:
3 4 5
(2)采用pop_back()方法从尾部删除元素。
1 |
|
运行结果:
1 2 3 4
(3)使用erase()方法从中间删除元素,其参数是迭代器位置。
1 |
|
运行结果:
1 3 4 5
(4)使用clear()方法清空deque对象
1 |
|
运行结果:
0
list双向链表容器
介绍
list容器实现了双向链表的数据结构,数据元素是通过链表指针串连成逻辑意义上的线性表,这样,对链表的任一位置的元素进行插入、删除和查找都是极快速的。
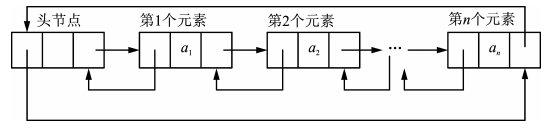
list的每个节点有三个域:前驱元素指针域、数据域和后继元素指针域。前驱元素指针域保存了前驱元素的首地址;数据域则是本节点的数据;后继元素指针域则保存了后继元素的首地址。list的头节点的前驱元素指针域保存的是链表中尾元素的首地址,而list的尾节点的后继元素指针域则保存了头节点的首地址,这样就构成了一个双向循环链。
由于list对象的结点并不要求在一段连续的内存中,所以,对于迭代器,只能通过“++”或“–”的操作将迭代器移动到后继/前驱节点元素处,而不能对迭代器进行+n或-n的操作,这点是与vector等不同的地方
1 |
|
说明:
(1).使名为pos的Input迭代器步进(或步退)n个元素
(2).对bidirectional迭代器和Random Access迭代器而言,n可为负值,表示向后退。
(3).Dist是个template型别,通常是个整数型别。
(4).advance()并不检查迭代器是否超过序列的end(),所有,对序列尾端调用operator++是一种未定义的操作行为。
1 |
|
说明:
(1).传回两个Input迭代器pos1,pos2之间的距离
(2).两个敌当前必须指向同一容器
(3).如果不是随机存取迭代器,则从pos1开始往前走必须能够到达pos2,亦即pos2的位置必须与pos1相同或在其后。
(4).回返值Dist的型别由迭代器决定
内容
1.先决条件
#include<list>
2.创建list对象
(1)创建空链表,如:
list<int> l;
(2)创建具有n个元素的链表,如:
list<int> l(10);//创建具有10个元素的链表
3.元素插入和遍历
三种方法往链表里插入新元素:
(1)采用push_back()方法往尾部插入新元素,链表自动扩张。
(2)采用push_front()方法往首部插入新元素,链表自动扩张。
(3)采用insert()方法往迭代器位置处插入新元素,链表自动扩张。
1 |
|
运行结果:
8 20 2 1 5
4.反向遍历
1 |
|
运行结果:
5 1 2
5.元素删除
(1)可以使用remove()方法删除链表中元素,值相同的元素都会被删除。
1 |
|
运行结果:
2 1 5 1
2 5
(2)使用pop_front()方法删除链表首元素,使用pop_back()方法删除链表尾元素。
1 |
|
运行结果:
2 8 1 5 1
8 1 5
(3)使用earse()方法删除迭代器位置上的元素。
1 |
|
运行结果:
2 8 1 5 1
2 8 5 1
(4)使用clear()方法清空链表。
1 |
|
运行结果:
2 8 1 5 1
0
6.元素查找
采用find()查找算法可以在链表中查找元素,如果找到该元素,返回的是该元素的迭代器位置;如果没有找到,则返回end()迭代器位置。
需要头文件#include<algorithm>
1 |
|
运行结果:
2 8 1 5 1
find it
not find it
7.元素排序
采用sort()方法可以对链表元素进行升序排列
1 |
|
运行结果
2 8 1 5 1
1 1 2 5 8
8.提出连续重复元素
采用unique()方法是可以剔除连续重复元素,只保留一个。
1 |
|
运行结果:
2 8 1 1 1 5 1
2 8 1 5 1
bitset位集合容器
介绍
bitset容器是一个bit位元素的序列容器,每个元素只占一个bit位,取值为0或1,因而很节省内存空间。
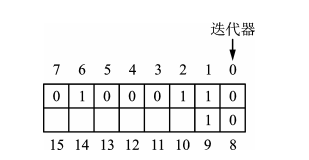
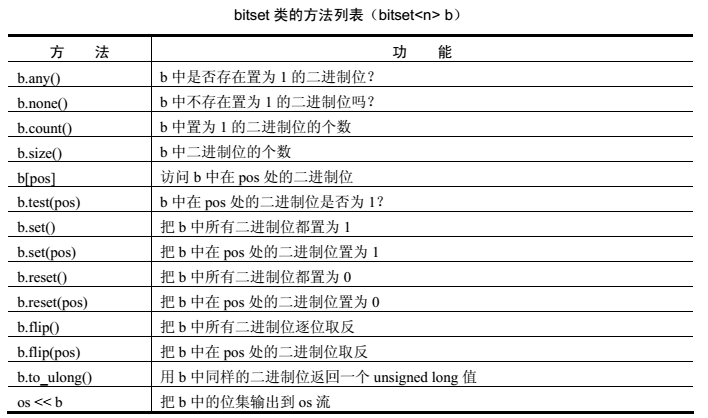
bitset类提供的方法见下表:
内容
1.先决条件
头文件:
#include<bitset>
2.创建bitset对象
创建bitset对象时,必须要指定容器的大小。bitset对象的大小一经定义,就不能修改了。
下面这条语句就定义了bitset对象b,它能容纳100000个元素,即100000个bit(位)此时,所有元素的值都为0.
bitset<100000> b;
3.设置元素值
(1)采用下标法
1 |
|
运行结果:
1001000010
(2)采用set()方法,一次性将元素设置为1。
1 |
|
运行结果:
1111111111
(3)采用set(pos)方法,将某pos位设置为1.
1 |
|
运行结果:
1001000010
(4)采用reset(pos)方法,将某pos位设置为0.
1 |
|
运行结果:
1001000010
4.输出元素
(1)采用下标法输出元素
1 |
|
运行结果:
1001000010
(2)直接向输出流输出全部元素。
1 |
|
运行结果:
1001000010
stack堆栈容器
介绍
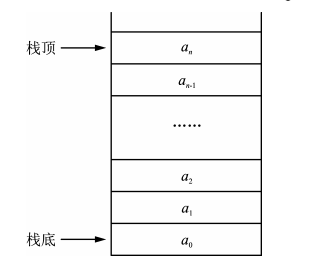
stack堆栈是一个侯建先出(Last In First Out, LIFO)的线性表,插入和删除元素都只能在表的一端进行。插入元素的一端称为栈顶(Stack Top),而另一端则称为栈底(Stack Bottom)。插入元素叫入栈(Push),元素的删除则 称为出栈(Pop)。
内容
1.先决条件
头文件:
#include<stack>
2.使用方法
堆栈只提供入栈、出栈、栈顶元素访问和判断是否为空等几种方法。
a.采用push()方法将元素入栈;
b.采用pop()方法出栈;
c.采用top()方法访问栈顶元素;
d.采用empty()方法判断堆栈是否为空,如果是空的,则返回逻辑真,否则返回逻辑家。
e.采用size()方法返回当前堆栈中有几个元素。
1 |
|
运行结果:
9
4
0
9 3 2 1
queue队列容器
介绍
queue队列容器是一个先进先出(First In First Out, FIFO)的线性存储表,元素的插入只能在队尾,元素的删除只能在队首。
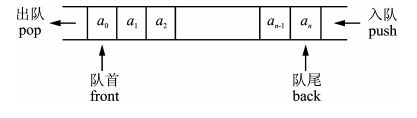
内容
1.先决条件
头文件:
#include<queue>
2.使用方法
入队push()
出队pop()
读取队首元素front()
读取队尾元素back()
判断队列是否为空empty()
队列当前元素的数目size()
1 |
|
运行结果:
4
0
1
9
1 2 3 9
priority_queue优先队列容器
介绍
priority_queue优先队列容器与队列一样,只能从队尾插入元素,从队首删除元素。但它有一个特性,就是队列中最大的元素总是位于队首,所以出队时,并非按先进先出的原则进行,而是将当前队列中最大的元素出队。、元素的比较规则默认为按元素值由大到小排序;当然可以重载“<”操作符来重新定义比较规则
内容
1.先决条件
头文件:
#include<queue>
2.优先队列的使用方法
入队push()
出队pop()
读取队首元素top()
读取队尾元素back()
判断队列是否为空empty()
队列当前元素的数目size()
1 |
|
运行结果:
4
9 3 2 1
3.重定义优先级
(1)如果元素类型是结构体,重载“<”操作符定义优先级
1 |
|
运行结果:
Bomi : 18.5
Jack : 68.5
Peti : 90
(2)如果优先队列的元素不是结构体类型,重载“()”操作符来定义优先级
1 |
|
运行结果:
1 2 9 30
参考文献

