
Abstract
作为无监督学习方法的一类,聚类已经广泛地应用在计算机视觉领域。然而只有少数工作将其适用于大范围的数据集上的视觉特征端到端训练。本文我们提出一种方法——DeepCluster,其可以将神经网络的参数同结果特征的聚类分配任务一起进行学习。DeepCluster采用k-means标准聚类算法迭代地将特征分组,并且使用随后的分配任务作为监督更新网络的权重。 我们将DeepCluster应用于基于大数据集(如ImageNet和YFCC100M)的卷积神经网络的无监督训练。训练的模型在所有标准基准测试中的表现超过现有技术标准。
关键字:无监督学习,聚类
Abstract. Clustering is a class of unsupervised learning methods that has been extensively applied and studied in computer vision. Little work has been done to adapt it to the end-to-end training of visual features on large-scale datasets. In this work, we present DeepCluster, a clustering method that jointly learns the parameters of a neural network and the cluster assignments of the resulting features. DeepCluster iteratively groups the features with a standard clustering algorithm, k-means, and uses the subsequent assignments as supervision to update the weights of the network. We apply DeepCluster to the unsupervised training of convolutional neural networks on large datasets like ImageNet and YFCC100M. The resulting model outperforms the current state of the art by a significant margin on all the standard benchmarks.
Keywords: unsupervised learning, clustering
Introduction
当前针对大范围端对端训练的模型还未面世
- 预训练卷积神经网络是大部分计算机视觉应用的基础模块。它们能够产生良好的通用目的的特征,其可提高有限数据集下的模型归纳性。
- 然而,Stock和Cisse最近的经验性结论表明基于ImageNet数据集的现行最先进的分类器性能很大程度上被低估了,并且少量错误未得到解决。其部分解释了为什么尽管近年来提出了大量新颖模型结构,而性能上却接近饱和的原因。
- 事实上,ImageNet根据今天的标准来看,相对为小数据集。推动向前发展的通常方式是建立更大更多样化的数据集。继而,这需要大量的人工标注,尽管这些年来社区积累了大量的专业知识。
- 通过原始数据取代标签的方法所带来的的视觉表示上的偏差将导致不可预测的后果。因此,这呼唤无监督情况下基于互联网大范围数据集上训练的方法。
聚类算法广泛应用,但存在缺陷,没有在大范围数据集集端对端训练的例子
- 无监督学习已经广泛运用于机器学习领域,聚类算法、降维以及密度估计也经常被运用于计算机视觉。
- 而这些成功的一个关键原因是他们仅仅应用于特定领域或者数据集,如卫星、医学图像或新模态数据(如深度,其无法大量获得)
- 尽管聚类方法在图像分类上取得了最初的成功,但很少能够将其适用于端对端的卷积网络训练,更别说大范围数据集。
- 问题在于聚类算法主要用于固定特征的线性模型,无法同时学习多种特征。例如,通过k-means训练模型将导致一个简单的结果,即特征归零,并且聚类将崩塌弱化为单个实体
DeepCluster解决上述问题,仅关注k-means
- 本文,我们提出一个应用于大范围端对端网络训练的新颖聚类方法,其可能通过聚类框架获取有用的通用视觉特征。
- 简单起见,仅关注k-means,但其他聚类方法也能使用,如Power Iteration Clustering
- 整个流程与标准监督训练非常接近,以重复使用许多常见技巧。
- 不同于自我监督式方法,聚类的优点在于需要很少的专业领域知识,以及不需要输入的特定标记。
- 尽管其简单,但较之于早先已有的无监督方法,其在ImageNet数据集的分类和迁移任务上实现了性能上的显著提高。
鲁棒性得到验证
- 最后,通过修改实验拓扑结构,特别是训练集和卷及网络结构,框架的鲁棒性得到验证。
- 结构: 通过VGG取代AlexNet显著提高了特征的质量以及随后迁移任务的性能。
- 数据集: ImageNet作为训练集帮助理解标签对于网络性能的影响,但其有个特殊的图像分布,这一分布源自于细粒度的图像分类挑战: 其由均衡的类组成,并包含各种各样的动物品种。因此,将YFCC100M作为可选数据集。最终结果显示,对于此未确认数据分布进行训练也能保持最先进的性能
- 当前基准测试侧重于无监督网络捕获类级信息的能力。建议在图像检索基准上对其进行评估,已检测其捕获实例级信息的能力。
本文贡献
- 提出一种端对端的运用任何标准聚类算法的新颖无监督方法
- 在许多无监督学习的标准迁移任务上去的最先进的性能
- 在未确定图像分布训练上取得高于之前先进性能的结果
- 无监督特征学习上对于当前评估拓扑结构的讨论
Relate Work
特征的无监督学习
- 少有同本文的无监督学习深度模型。Coastes andNg 也使用k-means,但是通过自底而上地顺序学习每一层,而本文通过端对端进行学习。
- 其他聚类损失被用于共同学习卷积特征和图像聚类,但是并没有大范围测试无法对当前卷及网络进行彻底研究。
- Yang等通过循环框架迭代地学习网络特征和聚类。他们的模型在小数据集上取得很好的性能,但是对于大规模数据集,其高性能可能面临挑战。
自我监督式学习
- 通过由输入数据直接计算伪标签,使用pretext tasks取代人为标注的标签
- Doersch等使用补丁的相对位置预测作为pretext task,而Noroozi和Favaro则训练网络以在空间上重新排列无序的补丁。
- 。。。
- 与本文相反,以上的方法都是域依赖的,需要专业知识仔细设计pretest task
生成模型
- 当前,无监督学习一直在图像生成上取得更大进步。典型地,通过一个自动编码器,生成对抗网络GAN或者更直接地通过重构损失,在预定义随机噪声和图像之间学习参数映射。
- GAN辨别能够产生视觉特征,但是其性能相当令人失望。Donahue和Dumoulin等人的工作显示给GAN添加一个编码器来生成更具竞争力的视觉特征。
Method
初步工作
①$f_{\theta}$表示卷积映射,$\theta$是相关参数集合,通过应用该映射于图像捕获向量作为特征或表示.
②给定训练集$X=\lbrace x_1,x_2,…,x_N\rbrace$N张图像,希望找到一组参数$\theta^{\ast}$使得映射函数$f_{\theta^{\ast}}$生成较好的通用特征。
③这些参数通常通过监督式学习,即每张图片$x_n$与标签$y_n$联系($y_n\in\lbrace 0, 1\rbrace^{k}$。标签表示k个可能得预定义类别中的一个。
④参数化分类器$g_W$预测特征$f_{\theta}\left(x_n\right)$顶部的正确标签.
⑤分类器的参数$W$以及映射参数$\theta$随后通过优化以下问题而一起被学习:
$$
\operatorname*{min}_{\theta,W}\frac{1}{N}\sum_{n=1}^{N}\ell\left(g_W\left(f_{\theta}\left(x_n\right)\right),y_n\right)\qquad (1).
$$
- $\ell$为多项式逻辑损失,也称为负log-softmax函数
- 该损失函数使用小批量随机梯度下降以及反向传播计算梯度进行优化
通过聚类进行无监督学习
- 当从高斯分布采样$\theta$,没有任何学习的时候,$f_{\theta}$确实不生成任何较好的特征。然而,这种随机特征在标准迁移任务上的性能远高于chance level(出现这种机会的正常水平)。例如,一个位于随机AlexNet的最后一个卷积层之上的多层感知机实现了ImageNet数据集上12%的准确率,而chance机会水平是0.1%。
- 随机卷积网络的良好性能与他们的卷积结构密切相关,其提供了输入信号上强有力的先验性。本文的idea是利用这种弱信号激发卷积网络的辨别能力。
- 本文使用卷积网络的输出进行聚类,并使用后续聚类分配认为作为pseudo-labesl(伪标签)来优化$Eq.(1)$。DeepCluster迭代地学习特征并将它们分组。
- 缺少对比点的情况下,本文关注于标准聚类算法k-means。与其他聚类算法对比的初步结果表明这种选择无关紧要。
k-means将一批向量作为输入(本文为卷积网络生成的特征$f_{\theta}\left(x_n\right)$),以及基于几何标准将他们聚集分成k个不同的类组。更准确地,其通过解决以下问题将形状为$d\times k$的矩阵C和每张图聚类分配$y_n$一起学习:
$$
\operatorname*{min}_{C\in\Bbb{R}^{d\times k}}\frac{1}{N}\sum_{n=1}^{N}{min}_{y_n\in\lbrace 0,1\rbrace^{k}}\begin{Vmatrix}f_{\theta}\left(x_n\right)-Cy_n \end{Vmatrix}_2^2\Rightarrow y_n^{\top}1_k=1\qquad (2).
$$
解决此问题得到一组最佳分配$\left(y_n^{\ast}\right)_{n\leq N}$以及矩阵$C^{\ast}$。前者之后作为伪标签,后者不再使用
总之,DeepCluster交替使用$Eq.(2)$聚类特征生成伪标签以及通过预测的这些伪标签由$Eq.(1)$来更新卷积网络的权重。这种交替的程序容易产生较差方案;下一节将描述如何避免这种退化的方案。
$\theta$是卷积层参数,$W$是分类器参数,通过$Eq.(1)$进行迭代优化学习
通过$Eq.(2)$进行聚类得到伪标签,之后将得到的伪标签用于$Eq.(1)$更新网络权重
即$Eq.(1)$中的$y_n$为$Eq.(2)$得到的伪标签$\left(y_n^{\ast}\right)_{n\leq N}$。
如图: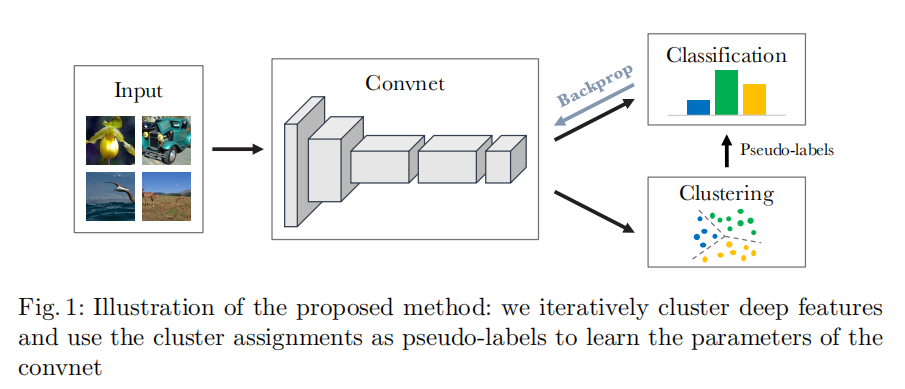
避免退化方案
- 退化方案的存在不是卷积神经网络无监督学习的特例,而是所有将区分分类器与标签一起进行学习的方法都有的问题。甚至当将区分聚类应用于线性模型上时也有这种问题。
- 解决方案通常基于约束或惩罚每个聚集的最小点数,但其不适用于大数据集的模型训练。
①空聚类
原因:
辨别模型学习类间的决策边界。一个可能的决策边界是将所有输入分成一个单独聚类。这个问题使由于缺乏防止空聚类而引起的,并且在卷积网络与线性模型中出现的一样多。
方案
特征量化中使用的常见技巧包括在k-means优化期间自动重分配空聚类。
更准确地说,当一个聚类为空时,随机选择一个非空聚类,并使用其进行小随机扰动后的形状作为这个空聚类的新形状。然后,将属于非空聚类的点重新分配给两个结果聚类。
②简单参数化
原因
如果绝大多数图像被分配给几个聚类,则参数$\theta$将专门区分它们。
最严重时,除了一个聚类之外的所有聚类都是单例,最小化$Eq.(1)$会导致一个简单的参数化,其中无论输入如何,预测都将预测相同的输出。
当每个类的图片数量高度不平衡时,该问题在监督分类中也常见。
方案
基于类或pseudo-labels的均匀分布的图像采样
相当于通过给定聚类大小的倒数在$Eq.(1)$中提高输入在损失函数中的权重,
实施细节
训练集和卷积网络结构
- ImageNet
- AlexNet(五卷积层,96,256,384,384,256过滤器,以及三个全连接层),移出了局部反馈规范化(Local Response Normalization)而是用批量归一化(Batch Normalization)。
- 可选结构VGG-16(批量归一化)
- 无监督方法常常不能直接应用于彩色图像,但不同策略可选。本文应用基于Sobel算子的固定线性变换移出颜色特征来增加局部对比。
优化
- 将中心裁剪的图像特征聚类以及通过数据增强训练卷及网络(随机水平翻转和随机大小和长宽比裁剪)。这强化了数据增强的不变形,有利于特征学习。
- 通过丢弃法、恒定步长、参数$\theta$的l2惩罚范数以及0.9动量参数进行训练
- k-means占用了训练的三分之一时间,因为需要在整个数据集上前向传播(采用Johnson等人的k-means实施方法,其每n个周期重分配聚类,但本文基于ImageNet数据集的设置更优——每个周期更新聚类)。
- 然而基于YFCC100M的Flickr上,周期的概念消失了:在参数更新和集群重新分配之间选择折衷更加微妙。因此保留大部分同ImageNet上的设置
- 500周期,12天,AlexNet结构,Pascal P100 GPU
超参数选择
基于下游任务,即Pascal VOC验证集的目标分类上选择没有微调的超参数。使用公开的代码Experiments
初步的实验,研究DeepCluster在训练期间的行为。随后,在标准基准测试上与先前先进模型方法对比之前,定性地评估学习到的过滤器。
初步研究
通过标准互信息(Normalized Mutual Information, NMI)测算相同数据下不同分配任务A和B之间共享的信息,NMI定义如下:
$$NMI\left(A;B\right)=\frac{I\left(A;B\right)}{\sqrt{H\left(A\right)}H\left(B\right)}$$
- $I$表示互信息,$H$表示熵。
这种测量可应用与任何源于聚类或真实标签的分配任务。
如果A和B是相互独立的,则NMI=0;
如果A和B其中之一是可由另一个确切预测,则NMI=1.聚类和标签的关系
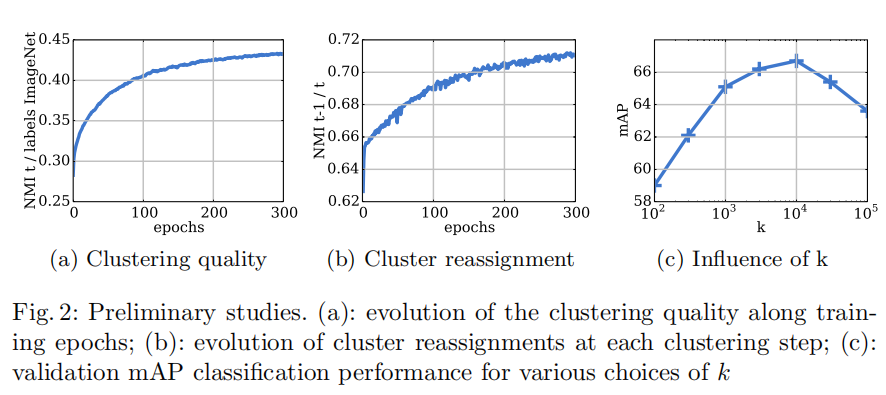
图2显示了训练期间在聚类任务和ImageNet标签之间的NMI变化。其测量了模型预测类级信息的能力。
本文仅仅使用该方法用于分析,而不用于任何模型选择阶段。
聚类与标签的相关性随时间而增加,显示特征逐渐捕获了目标类的相关信息。周期之间的重分配数量
每个周期,本文都不保证稳定性的情况下重新分配图像给一个新的聚类集。
测量t-1与t周期之间的NMI值显示了本文模型的实际稳定性。图2b显示了训练期间的这种测量。NMI在增加,表明越来越少的重分配以及聚类逐渐趋于稳定。然而,NMI逐渐饱和接近于0.8,表明大部分图像被规律地重分配在两个周期之间。事实上,其没有影响训练,并且模型没有偏离。选择聚类数量
本文测量了k-means中不同k值的UI与模型质量的影响。
报告了与超参数选择过程中相同的下游任务,即在PASCAL VOC 2007 分类验证集上的mAP值。
尝试了逻辑范围内的k值,如图2c显示了300周期训练后的结果
虽然每个k值在相同周期训练后 的性能不能直接相比较,但是其反映了超参数k的选择过程。k=10000时获得最好的性能。假设我们在ImageNet上训练,其希望k=1000产生最好的结果,但是明显一定程度的过分割是有益的。
可视化

第一层过滤器
图3显示了AlexNet第一层的过滤器,通过DeepCluster训练原始RGB图像以及经过Sobel算子处理的图像。
基于原始数据学习模型的困难之前已经提及。如图3左图,大部分过滤器仅仅捕获了颜色信息而其对于目标分类几乎不起作用。而Sobel算子预处理后的过滤器表现得类似于边缘检测器。
探究更深层
通过学习输入图像来评估目标过滤器的质量,该图像能够最大限度地激活过滤器。
采用同Yosinki等人表述的目标过滤器与其他同城过滤器之间的交叉熵函数。
与预期一致,更深的卷积层似乎捕获了更大量的纹理结构。然而,如图5第二行所示,最后一层的一些过滤器似乎简单地复制早已在之前层捕获的纹理。这恰恰证实了Zhang等人的发现:卷积层3和4的特征比来自卷积层5的特征更具辨别性。
最后,图5显示了一些conv5的过滤器的钱9张激活图似乎是语义相关的。这第一排的过滤器包含于目标类别高度一致的结构信息。第二排的过滤器则更关注于风格。
使用激活函数的线性分类
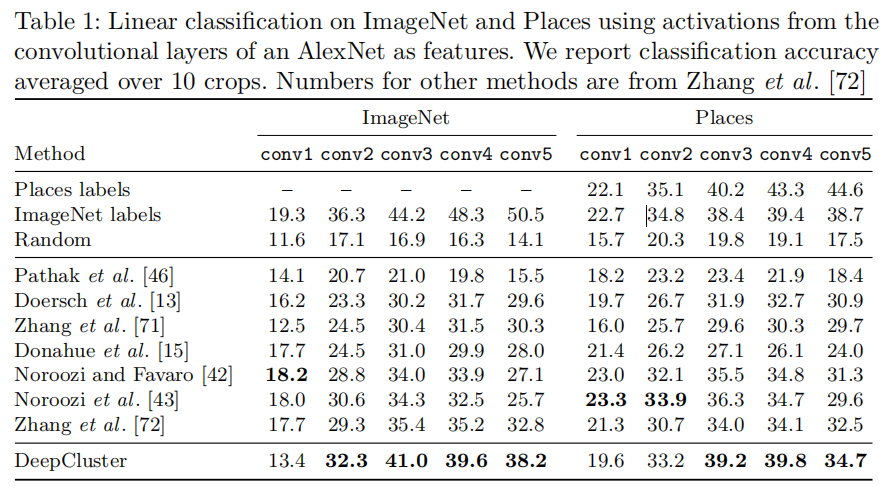
遵循Zhang等人的文章,本文在前几个不同卷积层训练一个线性分类器。与受监督式特性的逐层比较表明convnet开始是特定于任务的,即专门用于对象分类。
如表1,显示了在ImageNet和Palces数据集训练的结果。
通过训练集上的交叉验证选择超参数。
在ImageNet上,DeepCluster在第2到第5层的性能超过现有最先进性能1-6%。卷积层3获得了最大的提升,尽管卷积层1的表现差(其可能因为Sobel算子丢失了颜色信息)。这与上一节一致,卷积层3比卷积层5表现更好。
最后,DeepCluster和监督式学习AlexNet的性能差异性在更高层显著提高:卷积层2和3,差异性仅在4%左右,而卷积层5,差异性上升到12.3%,表明其可能储存了大量类级信息。
补充材料中报告了多层感知机在最后一层训练的准确度,DeepCluster超过当前先进性能8%。
在Places数据集上相同的实验显示,同DeepCluster,监督式模型基于ImageNet的训练的性能在高层有所下降。此外,DeepCluster产生的卷积层3和4的特征与通过ImageNet标签训练的特征更有可比性。这表明,当目标任务距离ImageNet覆盖的领域足够远时,标签就不那么重要了。
Pascal VOC 2007
最后,本文基于PASCAL VOC在图像分类、目标检测和予以分割上做了定性评估。PASCAL VOC相对较小的训练集更接近现实应用,其模型训练资源消耗大,更适用于少实例的任务或数据集。
- 目标检测的结果通过fast-rcnn获得
- 语义分割则通过Shelhamer等人的代码获得
- 对于分类和检测,基于PASCAL VOC 2007报告了性能以及基于验证集选择超参数
- 对于予以分割,遵循相关工作,报告了在PASCAL VOC 2012验证集上的性能
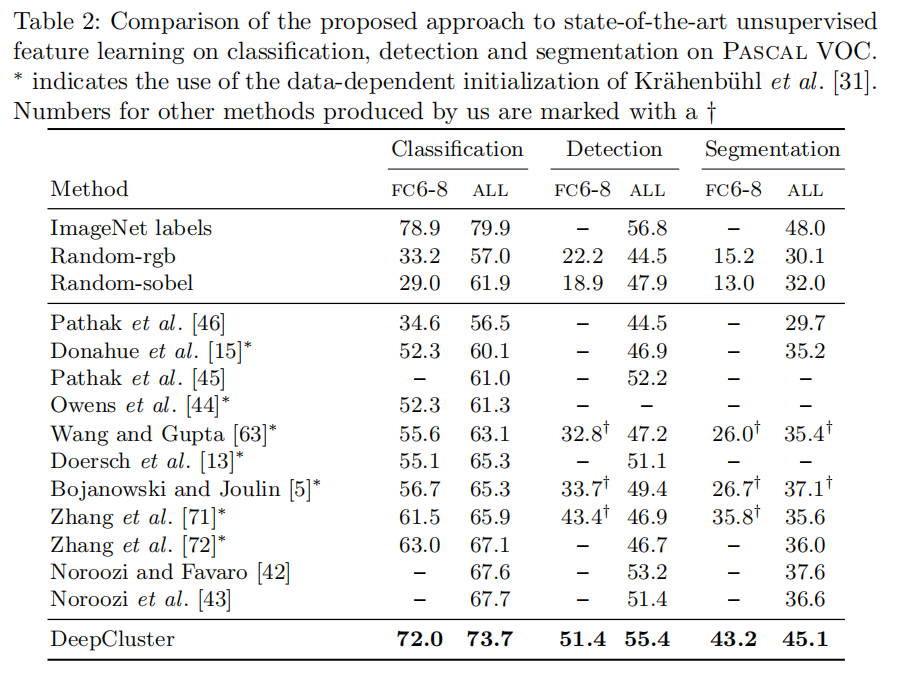
表2概括了DeepCluster与其他特征学习方法在三个任务上的比较。同之前的实验,DeepCluster在三个任务上都超过了之前非监督方法。 - 语义分割提升7.5%
- 目标检测,仅仅较小提升
感兴趣的是微调的随机网络与许多无监督方法相比较发现如果仅仅通过FC6-8学习,性能较差,因此,表2还报告了在DeepCluster使用FC6-8和一些基线进行检测和分割的情况。
Discussion
当前用于非监督方法的评估标准包括AlexNet在ImageNet数据集上训练以及测试类级任务。
为了理解和测量DeepCluster中提到的多种偏差,本文考虑不同的训练集和网络结构以及实例级识别任务
ImageNet与YFCC100M
ImageNet是为细粒度目标分类而设计的数据集,其实面相目标的,手工标识以及组织成了均衡的目标库。
通过设计,DeepCluster更偏向平衡聚类,而且如前文所述,聚类k值某种程度上可以与ImageNet的标签比较。这相比于其他基于ImageNet训练的非监督方法有优势。
为了测量这种效果的影响,本文从YFCC100M中随机选择了1M的图像子集用于预训练。
基于YFCC100M的标签的统计结果表明,目标类别严重失衡,导致数据分布不利于DeepCluster。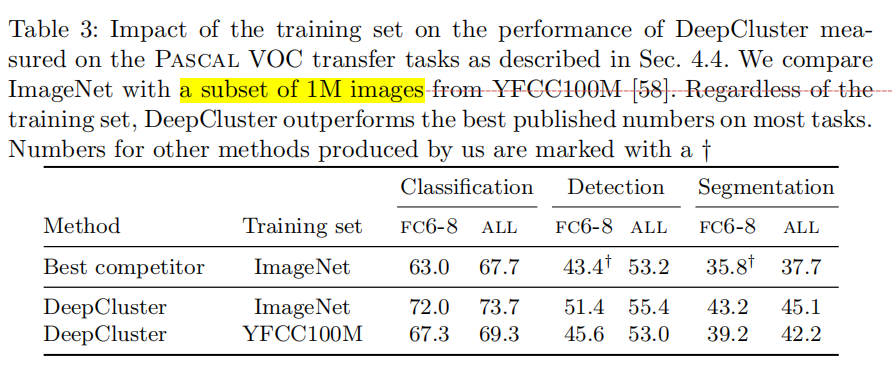
如表3所示,其对比了基于ImageNet和基于YFCC100M预训练在PASCAL VOC验证集上性能的差异性。
如Doersch提到的,该数据集(YFCC100M)不是面向目标的,因此性能上正如预想的那样有所下降。
然而,即使基于未确认的Flickr图像预训练的DeepCluster性能仍然高于当前先进标准。
以此验证了DeepCluster对于不同图像分布的鲁棒性,能够实现最先进的通用视觉特征,即使数据分布不利于DeepCluster的设计。
AlexNet与VGG
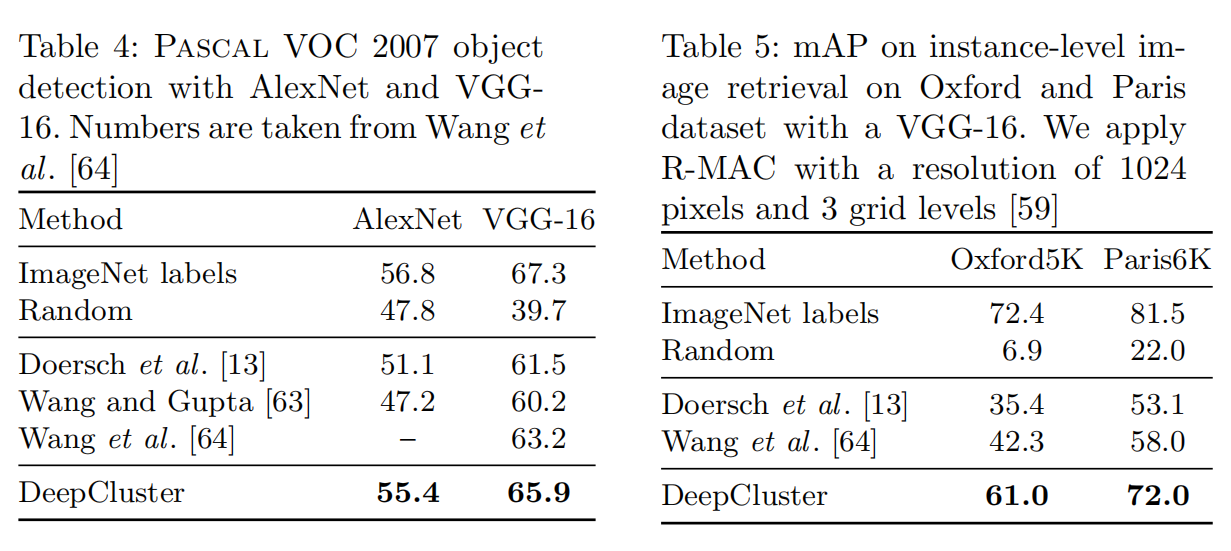
监督学习中,基于ImageNet训练的深度网络VGG或ResNet能够获得比AlexNet更高的准确率
表4比较了采用VGG-16与AlexNet基于ImageNet训练的DeepCluster性能以及在PASCAL VOC 2007数据集上微调的测试性能。
与其他非监督学习方法对比,本文深度网络结构获得了性能上的显著提升。
采用VGG-16的性能高于现行先进标准,仅仅比第一行监督学习方法低1.4%。值得注意的是,AlexNet和VGG-16在DeepCluster与ImageNet labels的差异都是1.4%。
对比其他结构,验证了DeepCluster在缺少监督式数据情况下,对于复杂结果进行无监督预训练的相关性
实例级的评估
之前的基准测试测量了无监督网络捕获类级信息的能力。但是它们都不能评估区分实例级图像。
表5显示了不同方法基于Sobel算子处理后的经过VGG-16训练的性能差异。
在OXford数据及上,预处理提升了5.5%的mAp值,而Paris数据集上则没有提升