
| 类型 | 说明 |
|---|---|
| 论文信息 | ElemNet: Deep Learning the Chemistry of Materials From Only Elemental Composition Dipendra Jha, Logan Ward, Arindam Paul, Wei-keng Liao, Alok Choudhary, Chris Wolverton & Ankit Agrawal |
| 会议期刊 | Scientific Reports |
| 时间 | Received: 1 August 2018 Accepted: 6 November 2018 Published online: 04 December 2018 |
| 解决的问题 | 仅从化合物元素成分预测形成焓,加快新材料发现 |
| 模型名 | ElemNet |
|---|---|
| 模型结构 | 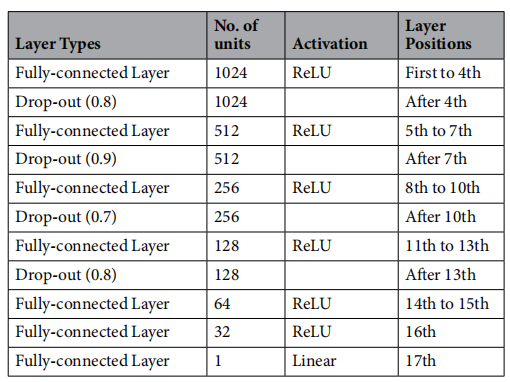 |
| 数据集 | ①Open Ouantum Materials Database(OQMD):用于训练 256622个化合物,其中16339个二元化合物,208824个三元化合物,31459个4-7元化合物; 9:1 训练集/测试集,10折交叉验证; 总共86种元素(元素周期表总共118种元素), ②Inorganic Crystal Structure Database:用于模型对于新的化合物预测的分析 |
| 数据清洗 | 1.86维的向量,非零值表示含有该元素,零值表示没有该元素,多数化合物元素成分少于五种,非常稀疏。 2.由于单元素材料的形成焓为0,故剔除 3.形成焓标准差超过$\pm 5\sigma$范围的剔除 |
| 超参数 | learning rate:$0.1-1e^{-6}$; SGD; momentum:0.9 |
| 对比传统ML方法 | Linear Regression, SGDRegression, ElasticNet, AdaBoost, Ridge, RBFSVM, DecisionTree, Extra Trees, Bagging, Random Forest中发现Random Forest在有误物理特征下都能取得相对最好的结果,故使用Random Forest进行对比 |
| 实验 | 结论 |
|---|---|
| ①训练集大小对于性能的影响 | 4k左右大小数据集便可获得比传统ML方法更优的性能 |
| ②训练时间以及预测时间的实验 | 预测更快更精确 |
| ③评估模型准确率 | 训练集中缺少的化合物对于准确率有影响,但总体上模型对于多数材料具有很强的预测能力,特别对于含有较少可能氧化的元素的稳定化合物来说最准确 |
| ④模型对于元素间相互作用的学习实验 | ①Ti-O二元化合物实验;②Na-Mn-O/Na-Fe-O三元化合物实验 模型在二者上都取得了相较于ML模型更好地性能,模型能更好地推断未观测到的化合物的性质。 |
| ⑤模型可解释性洞察 | 通过对不同组别单元素和二元化合物分析模型第1、2、8层输出结果做PCA降维取前两个主成分可视化后,通过聚集的情况发现,模型前几层更倾向于学习与输入值类型相关的性质,而后几层则能够抽象更复杂的特征 |
| ⑥新材料组合筛选试验 | 总体而言,模型能够有效对新材料做出合理预测 |