
| 类型 | 说明 |
|---|---|
| 论文信息 | Fully Convolutional Networks for Semantic Segmentation Jonathan Long, Evan Shelhamer, Trevor Darrell UC Berkeley |
| 会议期刊 | CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 2015 |
| 解决的问题 | 图像分割任务 |
| 模型结构 | 说明 |
|---|---|
| 模型1 | 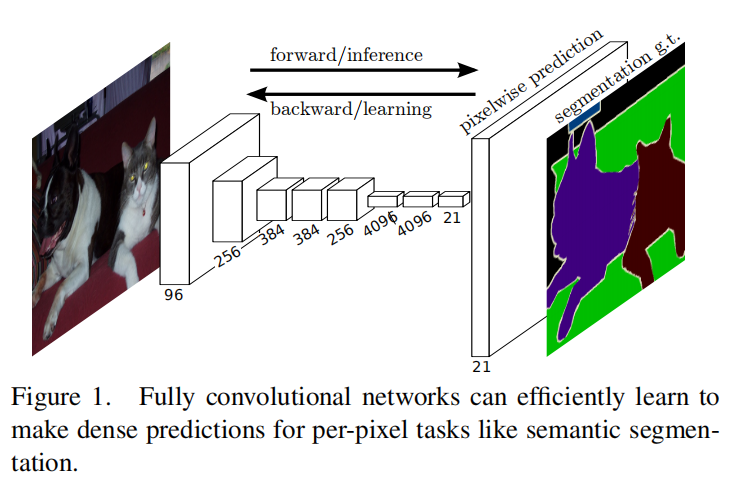 - 这个是实验用的修改已有模型(例如,VGG,AlexNet,GooglNet)的全卷积网络,主要就是将原有模型的卷积层部分保留,而后全连接层用对应的1×1卷积层取代,而后加上对应通道为数据集标签数的1×1卷积层,再加上一个转置卷积层得到原尺寸预测图。 |
| 模型2 | 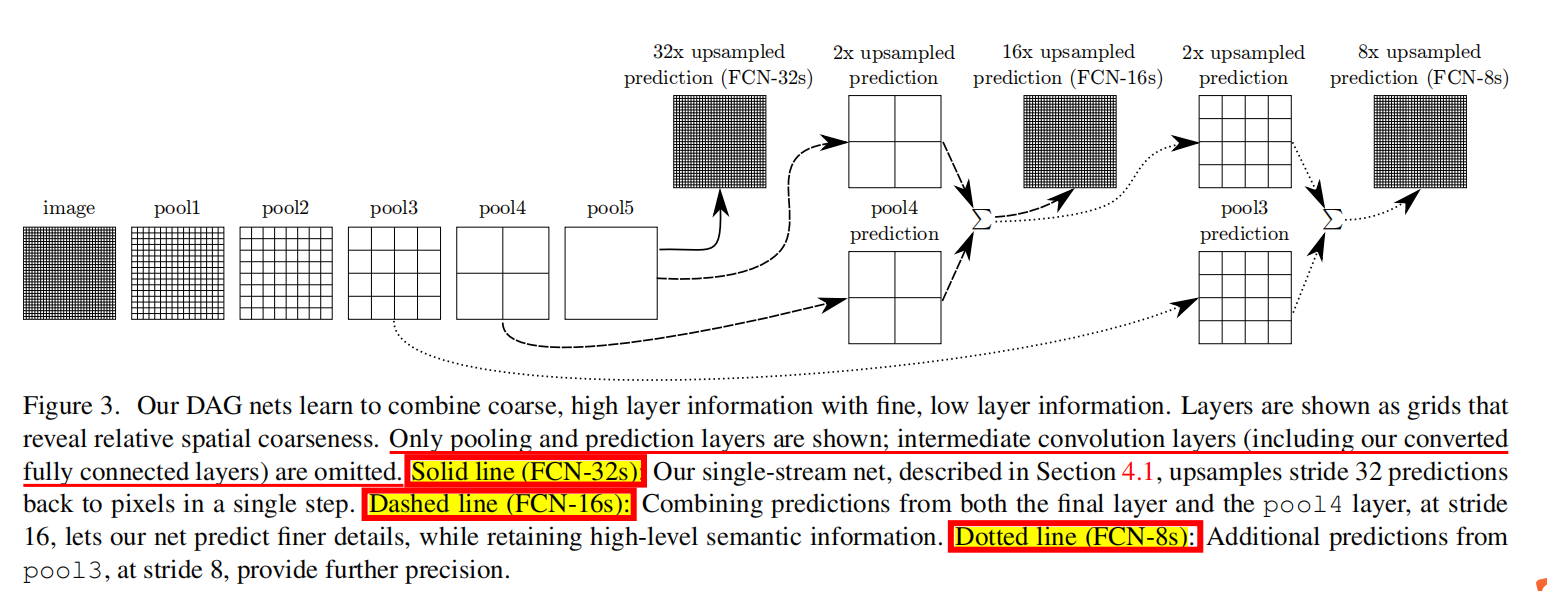 - ②这个是论文新提出的模型结构,主要思想就是跳跃结构。 |
| 跳跃结构 | 后一层的卷积层/池化层的输出特征图上采样得到与前一层相同尺寸(包括通道)的特征图,二者对应求和得到新的特征图,新的特征图要么上采样直接到输出预测,要么进一步向前融合,以此类推。文中只进行了两次融合。 |
| 跳跃结构的意义 | 这是这篇论文最重要的贡献,以至于对于后来的模型影响很大。因为模型浅层捕获的是较精细的特征(包括位置信息),而高层则捕获更加抽象的粗糙信息,有关文献表明,浅层特征有利于最终像素定位以及预测。 |
| 上采样方式 | 说明 |
|---|---|
| ①Shift-and-stitch | 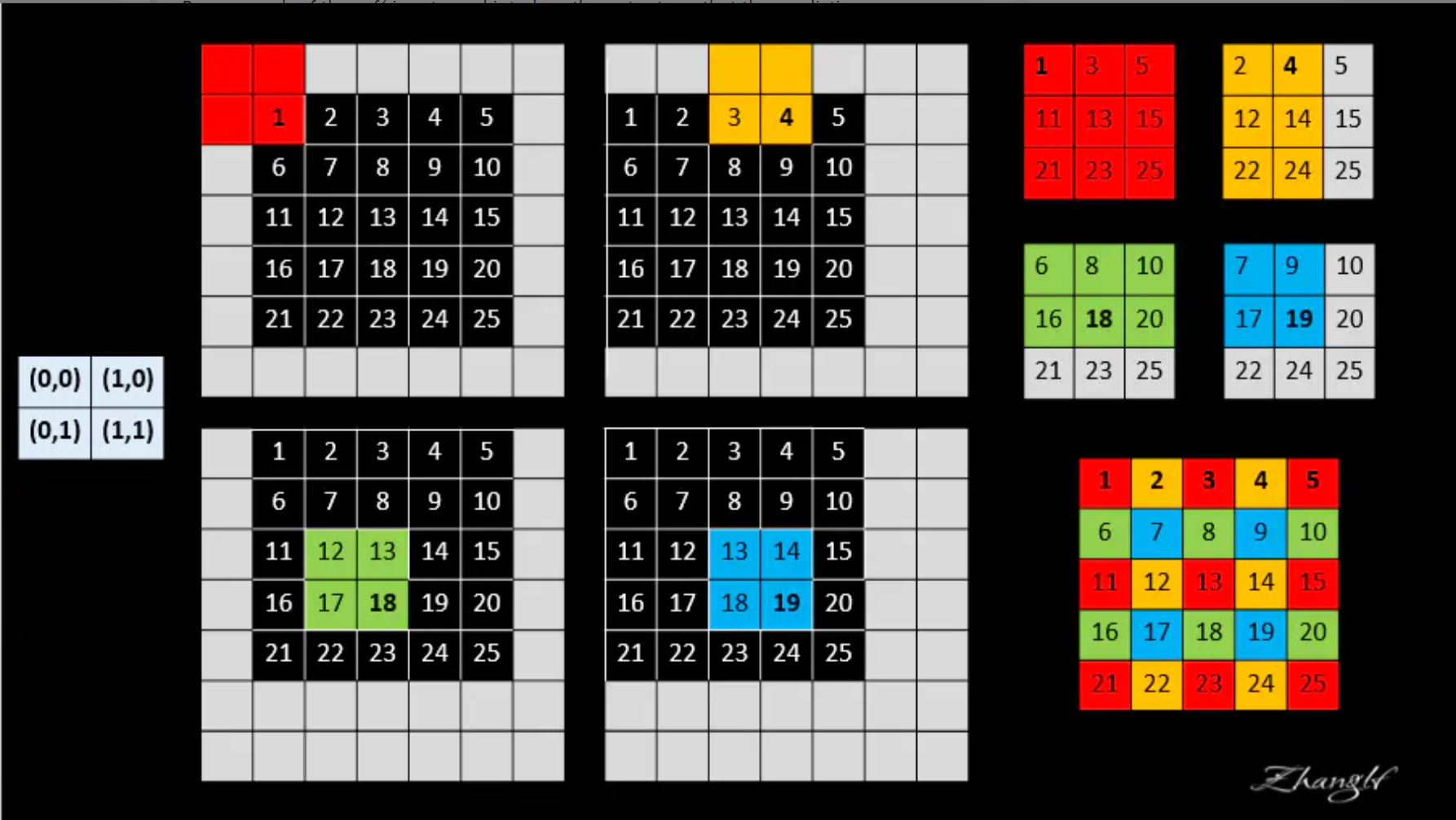 ) )这里参考一篇博文:设下采样因子为$f$,即卷积核大小,通过向原图填充$f-1$个padding得到新图,之后将原图在新图的基础左上移动$(x, y)(0<=x,y<f)$,可以得到$f*f$个新的输入图,经过卷积,可以得到$f*f$张特征图(尺寸比原图小),而后根据每个特征图每个元素下采样时对应的原图位置在输出图(大小与原图一致)上进行交错编织。具体$2*2$最大池化的例子如图所示,灰色部分是重复插入了,故可以舍去。 |
| ②Filter Rarefaction | 两层结构: ①步长为$S$的池化层或卷积层 ②卷积核大小为$f$的卷积层,其卷积核权重为$f_{i,j}$ 为了达到同Shift-and-stitch一样的目的,可以将后一层卷积核权重矩阵稀疏化,前一层步长为1  ) )例如 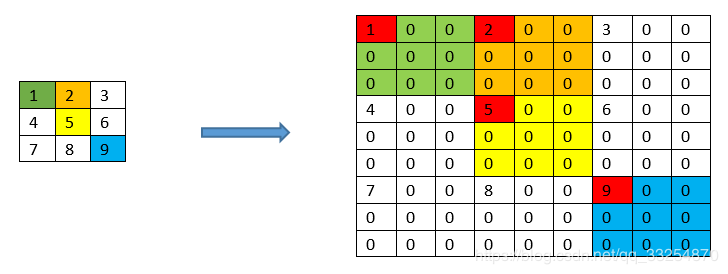 这里理解还有待进一步验证 |
| ③Deconvolution | 这里参考一篇博文 卷积的矩阵表示: 卷积核:  )输入重排: )输入重排: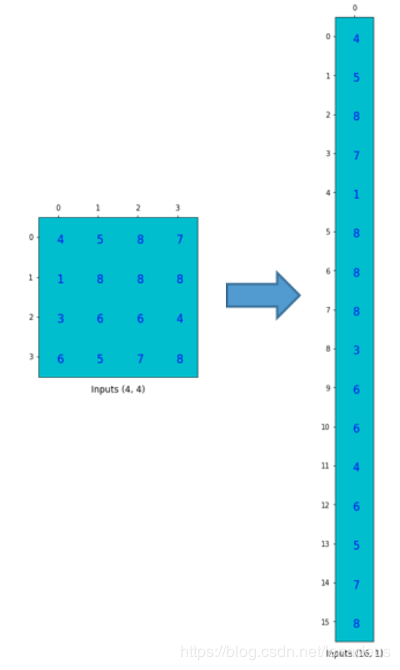 ) )卷积核重排:  ) )卷积的矩阵运算: 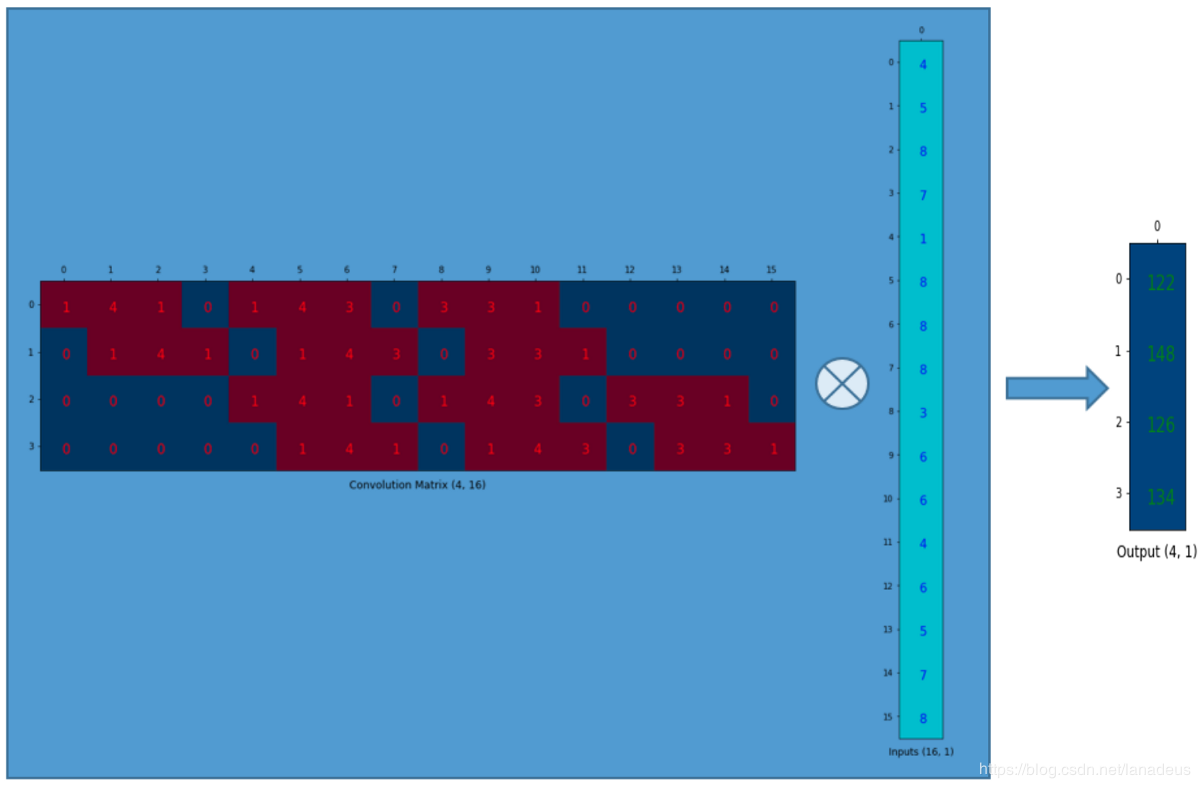 ) )输出重排  ) )反卷积的矩阵表示: 反卷积核重排后转置: 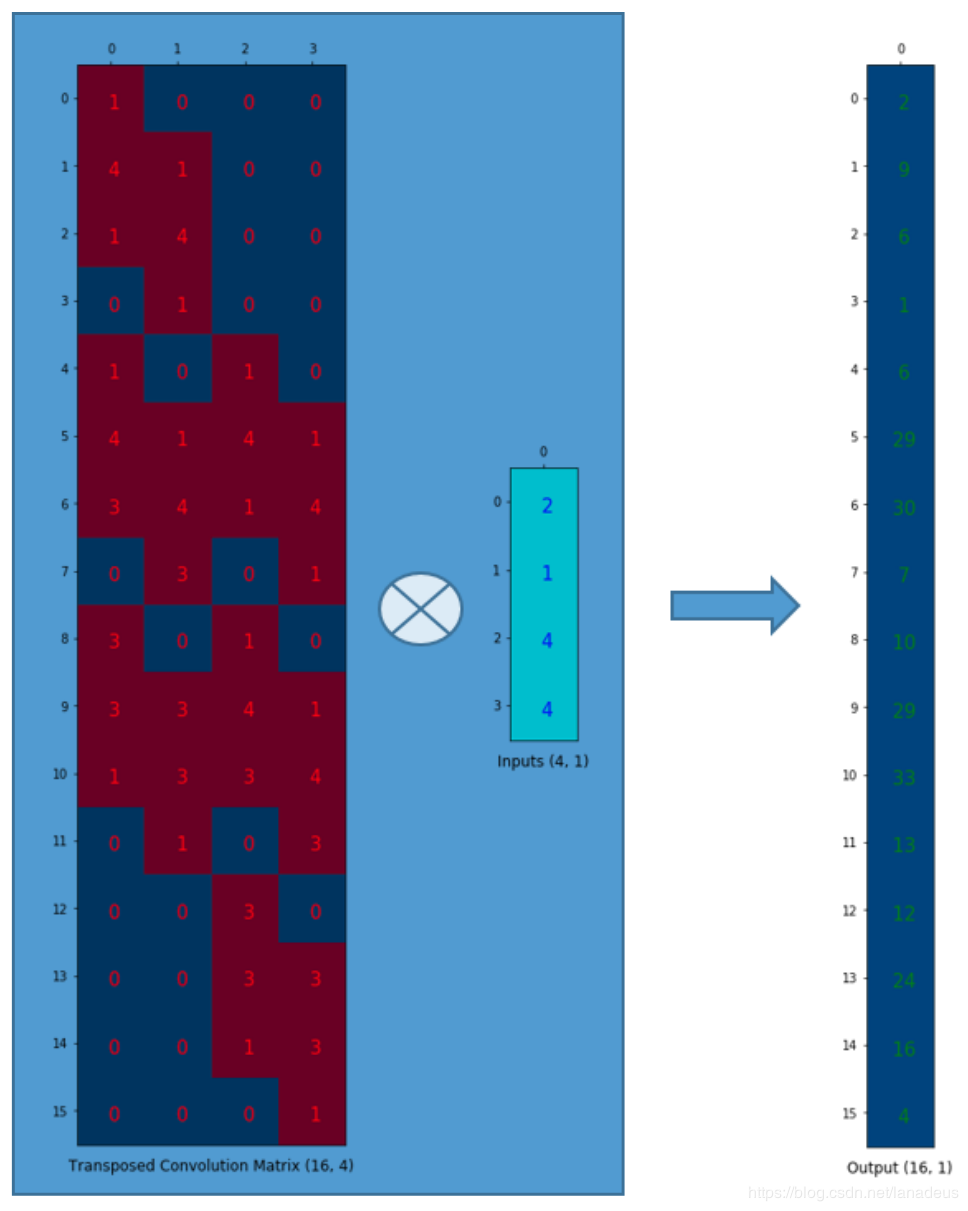 ) )输出重排  |
| 选择 | 论文经过比较,采用第三种转置卷积层(反卷积)的方式,速度更快,效果也差不多 |
| 实验 | 说明 |
|---|---|
| ①三个经典结构重构后的实验 | VGG,AlexNet,GooglNet对应修改成全卷积结构在PASCAL VOC 2011数据集上的实验 |
| ②新颖跳跃结构的实验 | 数据集 PASCAL VOC, NYUDv2, and SIFT Flow |
| ③Whole image与Patch Sampling方式对比实验 | 数据集PASCAL VOC 2011 |
| 评价指标 |  |
| 结论 |
|---|
| 通过修改分类模型用于分割任务,多层特征图融合的方式可以有效提高预测精度,同时简化和加速模型学习和推断。 |
| 其他 |
|---|
| ①Patchwise training的论文部分有些不理解,大致为Patchwise的方式在采样图像高度重合的时候,Whole image训练能够加速训练。 ②三种上采样方式之后试着代码实现以下,有些地方还没搞懂 ③其他实施细节需要关注论文源代码。 |