
| 类型 | 说明 |
|---|---|
| 论文信息 | InSituNet: Deep Image Synthesis for Parameter Space Exploration of Ensemble Simulations Wenbin He, Junpeng Wang, Hanqi Guo, Member, IEEE, Ko-Chih Wang, Han-Wei Shen, Member, IEEE, Mukund Raj, Youssef S. G. Nashed, and Tom Peterka, Member, IEEE |
| 会议期刊 | IEEE Transactions on Visualization and Computer Graphics, 2019 |
| 介绍 | 说明 |
|---|---|
| ① | 集成仿真在各种科学和工程学科中发挥着越来越重要的作用,如计算流体动力学、宇宙学和天气研究。随着现代超级计算机计算能力的不断增长,集成仿真越来越多地采用高空间和/或时间分辨率的大量参数设置来进行。然而,尽管仿真结果的准确性和可靠性有所提高,但仍面临两个挑战:(1)大规模仿真数据移动的I/O瓶颈;(2)仿真参数的有效探索和分析。现场可视化(In situ visualization)在模拟时生成可视化,仅存储可视化结果(比原始模拟数据小得多)以进行事后分析,在一定程度上解决了第一个挑战。然而,它也限制了事后探索和分析的灵活性,因为原始模拟数据不再可用。本研究的重点是提高科学家对集成仿真的现场可视化结果的探索能力,扩展他们对不同仿真参数影响的研究能力。然而,当前一些针对后处理探究和分析的方法更多地关注于扩展可视化映射参数(如传递函数)和视图参数(如视角)的探索能力,而很少考虑在集成仿真研究中非常重要的仿真参数。仿真参数的空间探索并不是一件小事,因为仿真参数与输出之间的关系往往十分复杂。现有的大部分仿真参数空间探索方法诉诸于同时可视化一组仿真参数和输出,通过可视化链接揭示参数和输出之间的对应关系。然而,这些方法通常依赖于可能无法用于大规模集成仿真的原始仿真数据。此外,这些方法在根据新参数推断仿真输出方面能力有限。因此,必须对新参数进行额外的模拟,这将为大多数科学模拟耗费大量的计算资源。在本文中,我们提出了InSituNet,一个基于深度学习的代理模型,以支持参数空间探索的集成仿真在现场可视化。我们的工作是基于这样的观察,即深度神经网络可以生成高精度和保真度高的图像,用于各种图像合成应用,如超分辨率、图像修复、纹理合成和渲染。具体来说,本文训练InSituNet来学习从模拟、可视化映射和视图参数到可视化图像的端到端映射。经过训练的模型使科学家能够在各种可视化设置下交互式地探索不同仿真参数的综合可视化图像,而不必实际执行昂贵的仿真。 |
| ②方法的三个主要步骤 | ①从集成仿真中收集现场训练数据:针对不同仿真参数下的集成仿真,利用不同的可视化映射和视图参数,实现了仿真数据的可视化。收集得到的可视化图像和相应的参数,用于InSituNet的离线训练。 ②InSituNet的离线训练:在给定参数和图像对的情况下,利用图像合成的前沿深度学习技术训练InSituNet卷积回归模型,将仿真、可视化映射和视图参数直接映射到可视化图像中 ③交互式的事后探索和分析:通过训练有素的InSituNet,我们构建了一个交互式的可视化界面,使科学家能够从两个角度探索和分析模拟:(1)利用InSituNet的正向传播推导参数空间内任意参数设置的可视化结果;(2)利用InSituNet的反向传播分析不同参数的灵敏度。 |
| ③ | 本文证明了该方法在燃烧、宇宙学和海洋模拟方面的有效性,并将InSituNet的预测图像与地面真实值和其他方法进行了比较。另外,还评估了InSituNet中不同超参数(如损失函数和网络结构的选择)的影响,并为超参数的配置提供了指导。 |
| 创新点 | 说明 |
|---|---|
| ① | 深度图像合成模型(即(InSituNet),使综合模拟的参数空间探索成为可能 |
| ② | 一个交互式的可视化界面,探索和分析集成仿真的参数与训练的InSituNet |
| ③ | 综合研究了InSituNet不同超参数的影响,为InSituNet在其他仿真中的应用提供了指导 |
| 相关工作 | 说明 |
|---|---|
| ①现场可视化分类 | 根据输出结果,可将现场可视化分为基于图像的、基于分布的、基于压缩的和基于特征的方法 |
| ②本文为基于图像的现场可视化 | 可以在现场可视化模拟数据,并存储图像进行事后分析。与其他方法相比,我们的工作不仅支持各种可视化映射和视图参数的探索,而且还支持在不实际运行仿真的情况下在新的仿真参数下创建可视化。 |
| ③参数空间探究 | (1)现有的集成仿真参数空间探索工作一般可以从可视化技术和参数空间探索目标两个方面进行综述。而这些参数可视化技术和分析任务主要集中于从集成运行中收集的有限数量的仿真输入和输出。 (2)而本文训练了一个代理模型,将研究扩展到参数空间中的任意参数设置,即使仿真没有使用这些设置执行。此外,我们的方法与在大规模集成模拟中广泛应用的原位可视化相结合。 |
| ④可视化深度学习 | 本文是基于深度学习的图像合成,其已经被用于各种应用,包括超分辨率,去噪,图像修复,纹理合成,文本-图像合成,样式转换,渲染。我们研究并结合不同的图像合成的最先进的深度学习技术(例如,永久损耗(perpetual losses)和GANs)来提高图像合成结果的质量。 |
| 方法流程 | 说明 |
|---|---|
| ①流程图 | 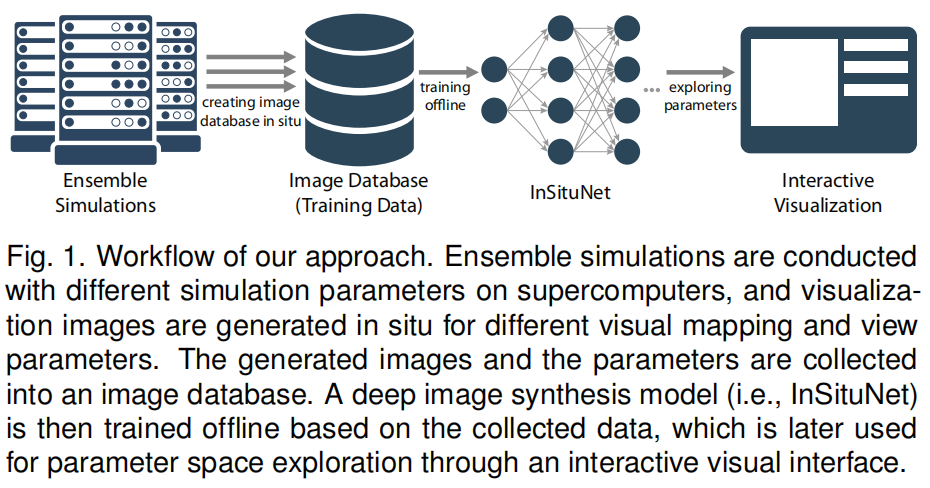 |
| ②三大部分 | (1)首先,在给定不同仿真参数的集成仿真条件下,利用不同的可视化映射和视图参数,在超级计算机上对生成的仿真结果进行可视化处理。这三组参数—模拟、可视化映射和视图参数—以及相应的可视化结果(即,图像),构成图像数据库 (2)通过收集参数和相应图像之间的数据对,训练InSituNet来学习从模拟输入到可视化输出的端到端映射 (3)利用训练好的InSituNet,建立了一个交互式的可视化界面,从两个方面对参数进行了探索和分析:A.对任意仿真的可视化图像进行交互式预测,可视化映射,以及在参数空间内查看参数;B.研究不同输入参数对可视化结果的敏感性。 |
| 数据集收集 | 说明 |
|---|---|
| ① | 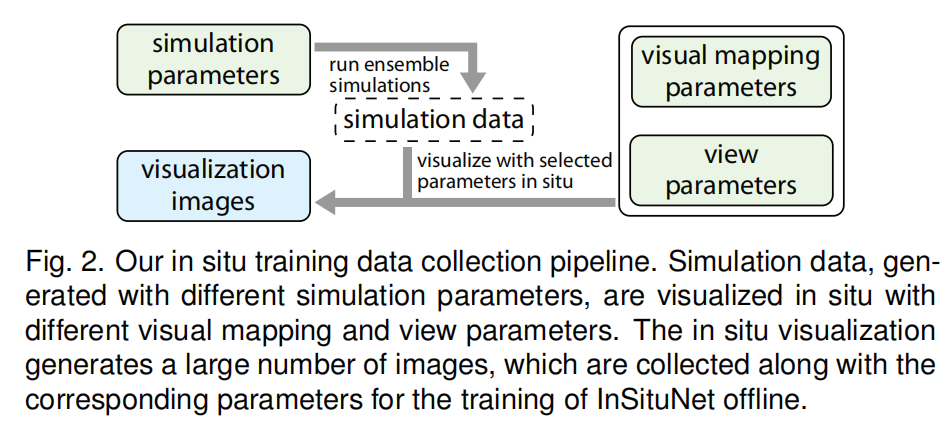 |
| ② | 给定在不同的模拟参数下进行的集成模拟,我们使用一组期望的可视化映射参数(例如,用一组等值线提取等值面)和不同的视图参数(例如,视点)进行了现场可视化。 |
| ③公式 | $$\mathcal{F}(P_{sim},P_{vis},P_{view})\rightarrow I$$ $P_{sim},P_{vis},P_{view}$ (1)Simulation parameters:表示为一个具有一个或多个维度的向量,每个维度的值范围由科学家定义。通过将参数扫掠到定义范围内,进行集成仿真,得到集成数据。 (2)Visual mapping parameters:是用于可视化生成的模拟数据的预定义操作,例如使用预定义的配色方案进行伪着色。注意,我们限制了用户选择任意可视映射以生成和存储更少图像的能力 (3)View parameters:用于控制创建图像的视点。本文定义的视点相机旋转仿真数据,这是由方位角$θ∈[0,360]$和海拔$φ∈[90,−90]$。为了训练一种能够预测任意视点的深度学习模型,我们对视点的方位角和仰角进行采样,并从采样的视点生成图像。基于我们的研究,我们发现每个集合成员取100个视点就足以训练InSituNet。本文工作使用压缩到便携式网络图形(PNG)格式的RGB图像,而不是更复杂的图像格式,如容量深度图像或可探索图像:①首先,通过InSituNet在RGB图像上的训练,可以实现使用那些复杂的图像格式的好处,比如支持视点的改变。②其次,与复杂的图像格式相比,RGB图像更适用于各种可视化,更容易被神经网络处理。 (4)$I$表示对应可视化图像。 InSituNet学习将这三组参数映射到相应的可视化图像的函数$\mathcal{F}$, |
| 模型结构以及训练过程 | 说明 |
|---|---|
| ①图示 | 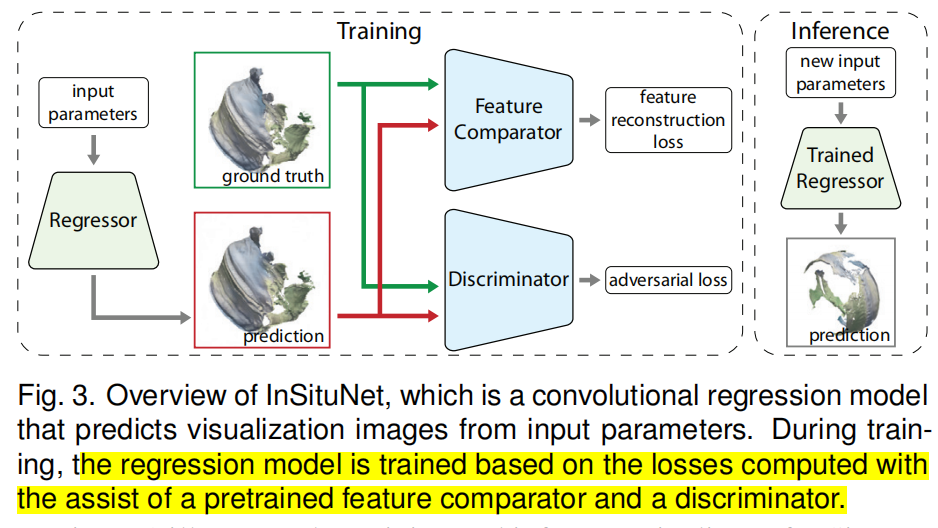 |
| ②组件 | (1)InSituNet由三个子网络组成:一个回归器、一个特征比较器和一个鉴别器 (2)回归器:一个由上文公式将输入参数映射到定义的可视化图像模型(深度神经网络) (3)特征比较器:特征比较器是一种预先训练好的神经网络,其卷积核用于提取和比较预测图像和真实图像之间的图像特征(如边缘、形状),从而获得特征重构损失(reconstruction loss) (4)鉴别器:一个用于评估预测图像与真值图像之间的差异的神经网络,从而得到对抗损失(adversarial loss)。 |
| ③训练过程 | 通过回归器得到预测图,之后通过鉴别器和特征比较器得到对抗损失以及特征重构损失,最后通过这两个损失更新回归器。 |
| 回归器Regressor | 说明 |
|---|---|
| ④图示 | 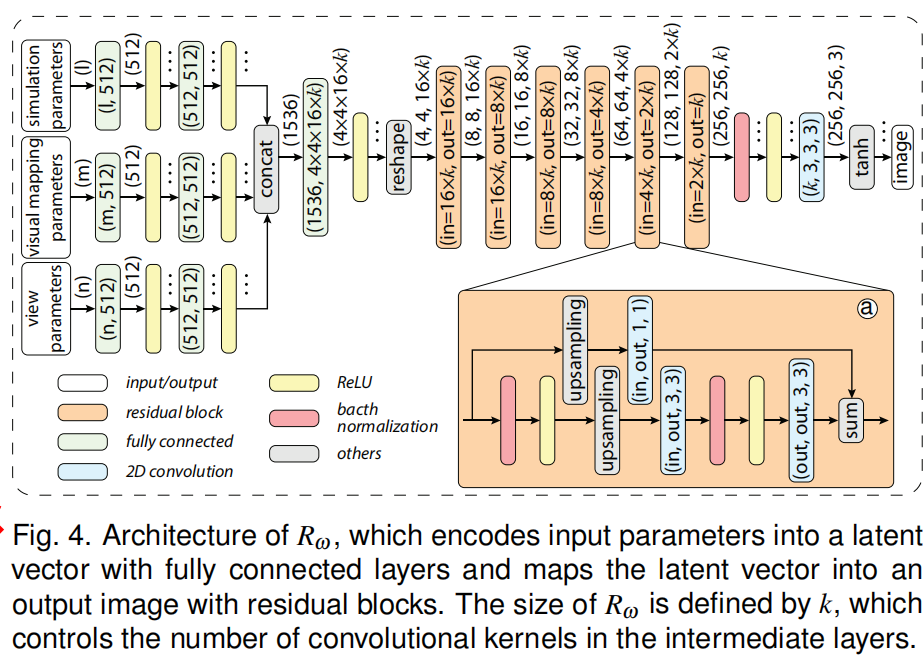 |
| ②流程 | (1)模型将三种类型参数($P_{sim},P_{vis},P_{view}$)作为输入,预测图像$I$作为输出 (2)这三种类型的参数首先分别输入到三组全连接层中,然后将三组全连接层输出联结,输出连接到另一组全连接层中,将它们编码成一个向量 (3)然后,将该向量重新构造成低分辨率图像,通过残差块(Residual Block, 如小图$a$所示)进行二维卷积和上采样,将其映射到高分辨率输出图像 |
| 鉴别器 | 说明 |
|---|---|
| ①图示 | 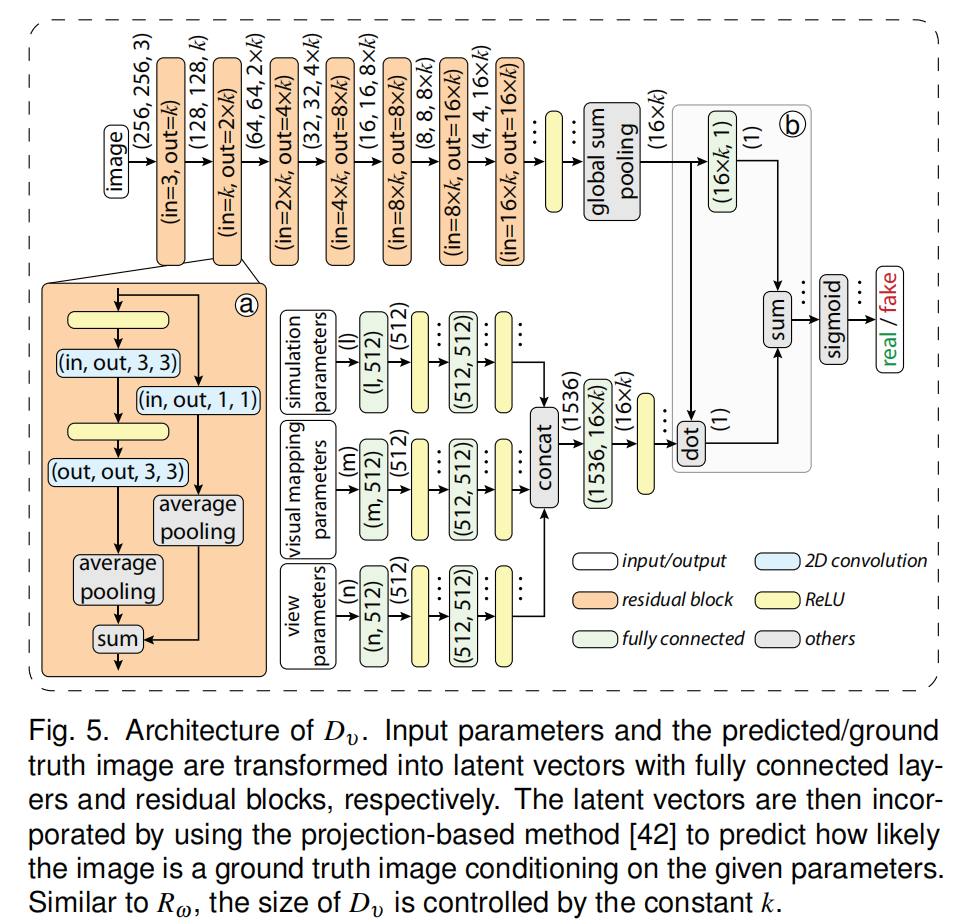 |
| ②流程 | 鉴别器将Regressor预测的图像或真值图像和三组参数作为输入,结果输出一个似然值,该值指示输入图像在给定参数条件下是一个真值图像的可能性有多大。,以此得到对抗损失(adversarial loss)更新Regressor以及discriminator。鉴别器评估的是真值图与预测图分布的差异 |
| 特征比较器 | 说明 |
|---|---|
| ①图示 | 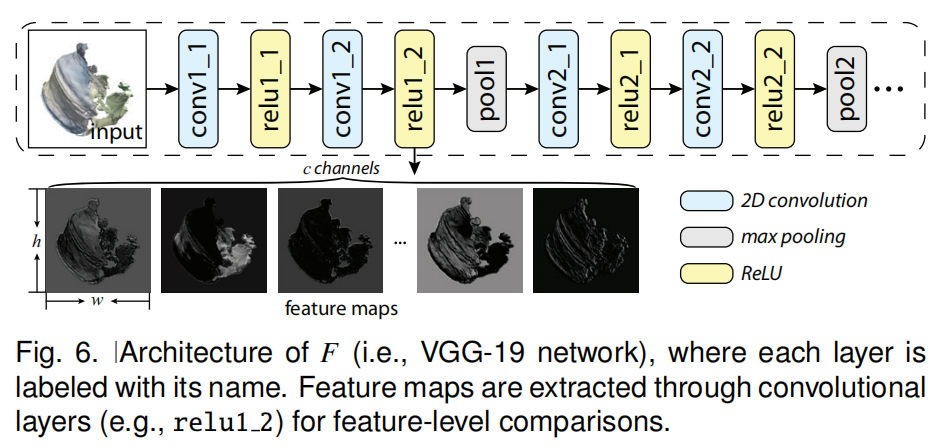 |
| ②流程 | (1)比较器是预训练的VGG19的特征提取部分,即卷积层部分,其每一层的卷积核都经过预处理,提取特定类型的图像特征,如边缘和形状。 (2)具体来说,本文使用层relu1_2来提取的特征图进行比较,原因如下: ①首先,早期的层,如relu1_2层的VGG-19网络关注的是科学可视化图像中普遍存在的边缘、基本形状等底层特征。 ②其次,通过我们的实验,我们发现通过池化层(例如图6中的pool1)将工件引入到生成的图像中。因此,我们使用第一个池化层之前的层relu1 2。 |
| 损失函数(Loss Function) | 说明 |
|---|---|
| ①总损失函数 | $$\mathcal{L}=\mathcal{L}^{F,l}_{feat}+\lambda\mathcal{L}_{adv\underline{}R}$$ $F$为特征比较器,$l$为特征比较器对应特征提取层, $\lambda$为系数 作用:用于更新Regressor以及特征比较器 |
| ②特征重构损失(Feature Reconstruction Loss) | $$\mathcal{L}^{F,l} _{feat}=\frac{1}{hwcb}\sum^{b-1} _{i=0}||{F^{l}(l _i)-F^{l}(\hat{I} _{i})}||^{2} _{2}$$ $h,w,c,b$分别为图像的长、宽、通道、batchsize,$I,\hat{I}$分别为真值图像和预测图,$F^{l}$为鉴别器的对应$l$层提取图像$I$或$\hat{I}$的特征图,损失为特征图像素级均方差 |
| ③对抗损失(Adversarial Loss) | (1)生成器损失(Generator Loss),即Regressor损失: $$\mathcal{L}_{adv\underline{}R}=-\frac{1}{b}\sum^{b-1}_{i=0}\log{D_v(\hat{I_i})}$$ $D_v$为鉴别器,损失值当鉴别器不能区分生成的图像与真值图像时,达到最小 |
| (2)对抗损失(Discriminator Loss): $$\mathcal{L}{adv\underline{}D} = - \frac{1}{b} \sum^{b-1}_{i=0} (\log{D_v(I_i)}+\log{1-D_v(\hat{I_i})})$$ 对抗性损失主要是根据GANs的对抗性理论来识别和最小化两种图像分布之间的差异。 | |
| ③两种损失的区别 | 首先,特征重构损失侧重于图像之间的平均差值,而对抗侧重于局部特征,这些特征是区分预测图像和地面真值图像最重要的特征。其次,特征重构损失比较生成的每对图像与地面真值图像之间的差异,对抗损失度量两种图像分布之间的差异。 |
| Techniques to Stabilize Training | 说明 |
|---|---|
| 介绍 | 对抗性训练的不稳定性是一个众所周知的问题,尤其是在合成图像分辨率较高的情况下,文本训练了一对对抗的网络,$R_ω,D_υ$,直接产生256×256彩色图像,其使用了包括光谱归一化(Spectral Normalization)和双时间尺度更新规则(TTUR)在内的稳定对抗训练的技术。 |
| ①光谱归一化(Spectral Normalization) | 谱归一化是基于矩阵的第一个奇异值对每一层的权矩阵进行归一化,应用于鉴别器每一层 |
| ②学习率 | Adam优化器,Regressor的学习率$\alpha_{R}=5×10^{-5},\alpha_{D}=2×10^{-4}\beta_{1}=0,\beta_{2}=0.99$,其中$\alpha_{R}$为Resgressor的学习率,$\alpha_{D}$为鉴别器的学习率,二者更新频率相同。 |
| 训练过程 | 说明 |
|---|---|
| ①图示 |  ),总量$N$,批量$b$(batchsize),正交初始化模型权重,Exit Criterion为125000次迭代,因为此时损失已经收敛。$v,w$分别为鉴别器和回归器的权重 ),总量$N$,批量$b$(batchsize),正交初始化模型权重,Exit Criterion为125000次迭代,因为此时损失已经收敛。$v,w$分别为鉴别器和回归器的权重 |
| ②流程 | (1)采样$N$组数据,包括三组参数以及相应真值图像; (2)初始化$R_w,D_v,F$权重; (3)每次迭代训练小批量$b$数据,回归器$R_w$生成预测图像,计算损失函数,反向传播更新鉴别器、归回器权重,直至达到迭代次数。 |
| 参数空间探究 | 说明 |
|---|---|
| ①参数空间探究的可视化界面 | 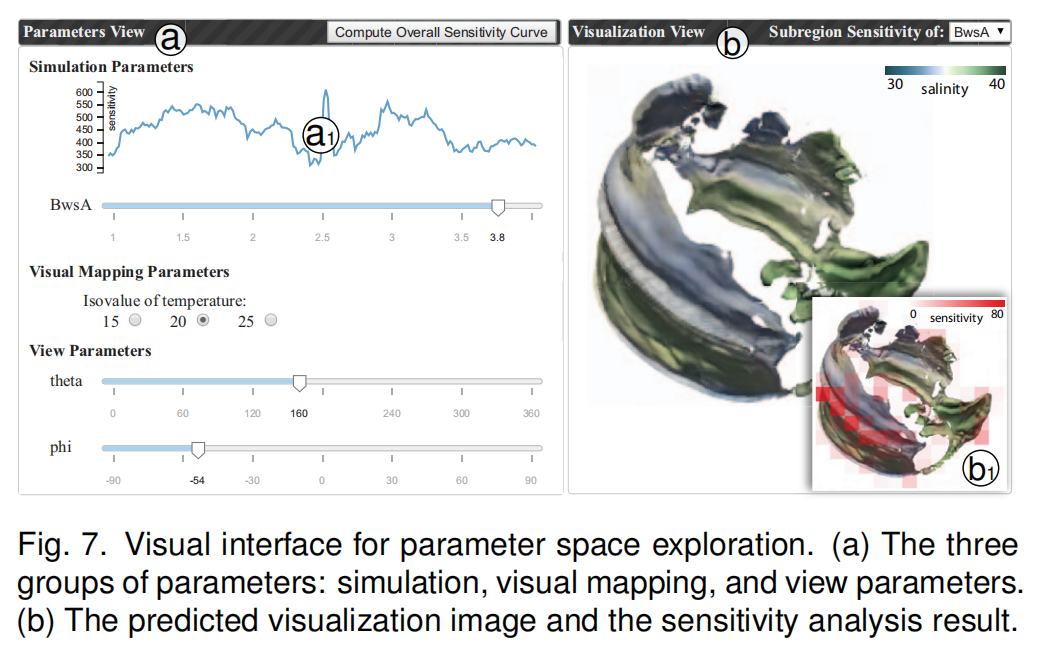 |
| ②用户可从两方面进行参数空间的探究 | (1)首先,通过InSituNet的正向传播,用户可以交互地推断参数空间内任意参数的可视化结果。 (2)其次,使用InSituNet的反向传播,用户可以研究不同参数的敏感性,从而更好地理解参数的选择。 (3)注意,在这项工作中,敏感性分析是用来反映图像空间中的变化(关于参数),而不是数据空间,本文的分析包括整体敏感性分析和分区敏感性分析。 (4)整体敏感性:重点是分析整个图像的灵敏度相对于每个模拟参数的价值范围。控制变量法控制其他参数,遍历该参数所有值,为每个参数返回一个灵敏度值列表,并在与该参数对应的滑条顶部以折线图的形式显示(图7(a1)),以指示该参数在其值范围内的灵敏度。 (5)局部敏感性:分析所选参数对所生成图像不同子区域的灵敏度。将计算出的灵敏度值从白色编码为红色,并将其覆盖在可视化图像的顶部,以指示哪些区域相对于所选参数更敏感(图7(b1)中的红色块)。 |
| 实验 | 说明 |
|---|---|
| ①三项仿真应用数据图示 |  |
| ②三项仿真应用 | (1)二维燃烧仿真$SmallPoolFire$ (2)宇宙模拟$Nyx$ (3)全球海洋模拟MPAS-Ocean |
| ③实现以及性能 | (1)三大组件:现场仿真数据收集、InSituNet训练、可视化探究以及分析组件。 (2)现场可视化通过ParaView Catalyst实施,仿真以及现场可视化使用包含648个节点的超级计算机,每个节点由一个14核以及128GB内存的Intel Xeon E50-2680 CPU组成。对于三项仿真,分别使用1,28,128个进程进行仿真计算。 (3)InSituNet使用PyTorch编写,由一各包含8块NVIDIA V100 GPU构成的NVIDIA DGX-1系统训练。 使用web服务器/客户端框架实施可视化界面,客户端方面使用D3.js进行可视化。 (4)由一台包一块Inter Corei7-4770 CPU以及一块NVIDIA 980Ti GPU的电脑进行可视探究与分析。 (5)表1右侧表明模型尺寸小于原始仿真数据,且训练时间比仿真时间短。 |
| ④模型超参数评估 | |
|---|---|
| 从损失函数、网络结构、训练样本数三个方面对模型进行评估 | |
| (1)评价指标 | |
| A. peak signal-to-noise ratio (PSNR) | PSNR利用图像像素间的累积平均平方误差来测量两幅图像之间的像素级差异。一个更高的PSNR表明比较后的图像在像素方面更加相似 |
| B. SSIM | SSIM基于两幅图像之间的区域汇总统计信息(如小块区域的均值和标准差)对两幅图像进行比较。较高的SSIM意味着从结构的角度来看,比较的图像更相似。 |
| C. earth mover’s distance (EMD) between color histograms | 使用EMD来量化两幅图像的颜色直方图之间的距离。较低的EMD意味着比较的图像根据颜色分布更相似 |
| D. Frechet´ inception distance (FID) | FID近似于两个图像分布之间的距离,在最近的图像合成工作中被广泛使用,作为对其他指标的补充。一个较低的FID表明两个图像采集在统计上更相似。 |
| (2)损失函数评估 | |
| 损失函数的选择 |  ) )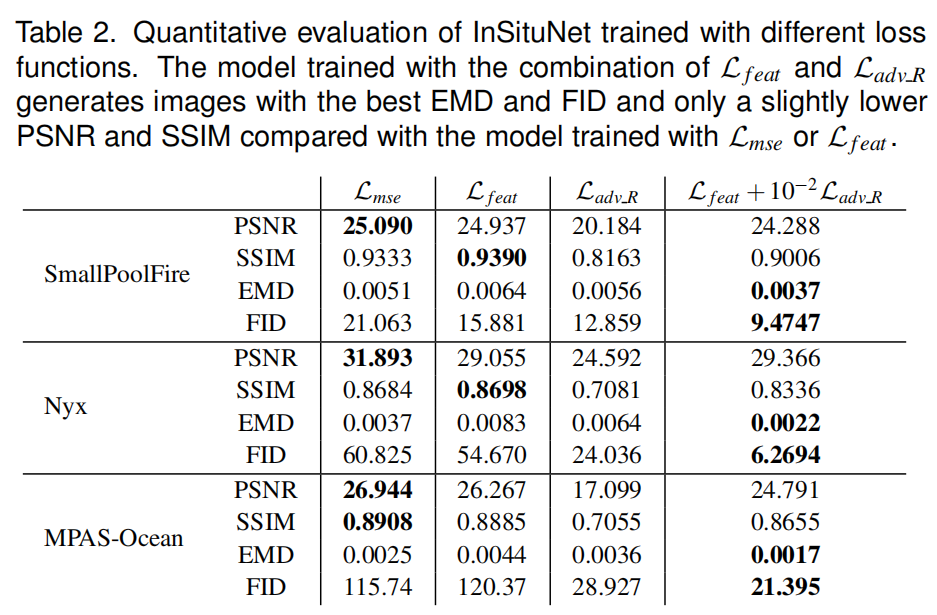 通过图8以及表2可以发现联合特征重构损失以及对抗损失更优 |
| 特征比较器特征提取层的选择 | 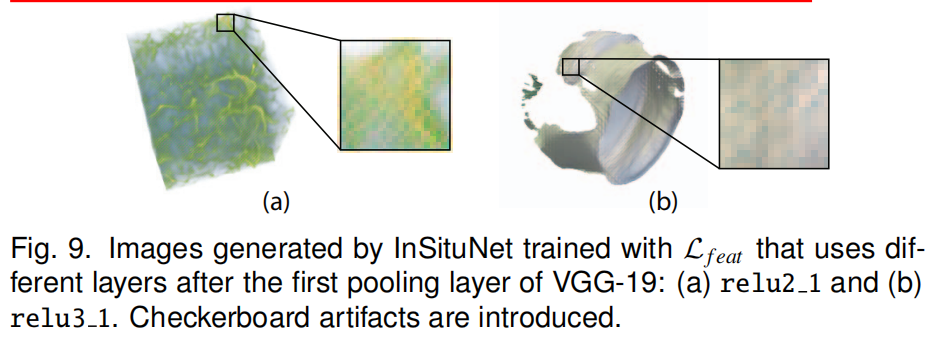 如图经过比较,发现使用relu1_2特征层更优 |
| 联合损失函数$\lambda$的选择 |  如表所示,发现$\lambda = 0.01$更优 |
| (3)网络结构评估 | 之前的图示可知,卷积核数量控制变量k决定网络尺寸 |
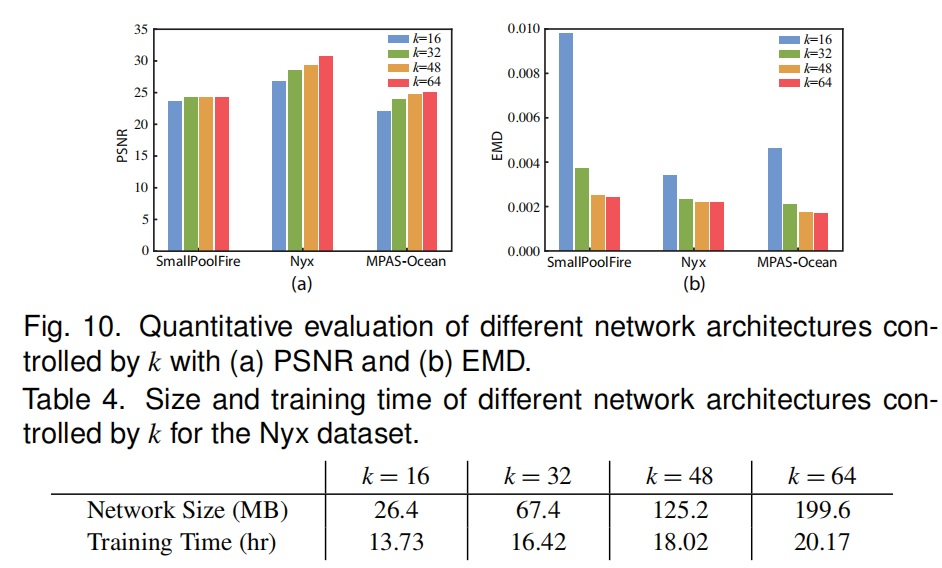 通过对比,三种仿真最优k值分别为32,48,48 | |
| (4)仿真训练次数评估 | 探究仿真运行周期次数对于后续InStituNet训练精度的影响 |
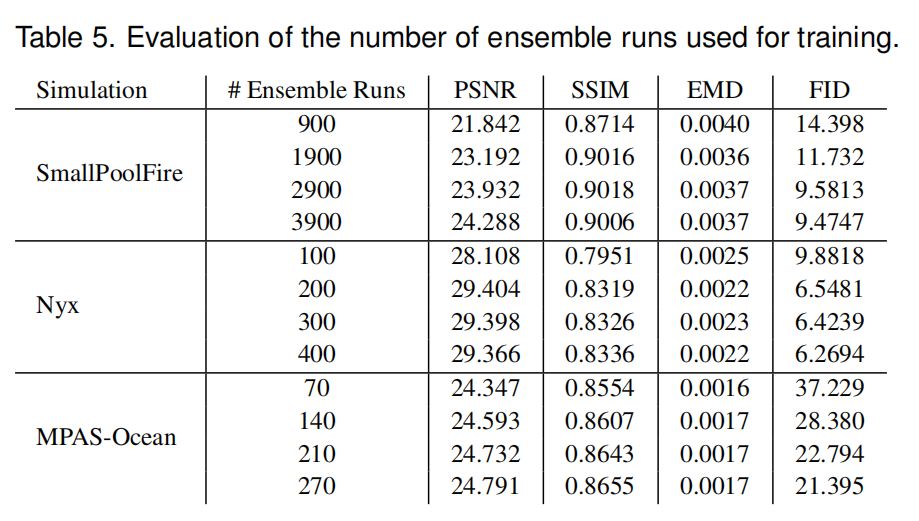 对比发现,3900,400,270分别为三种仿真的最优值。 | |
| (5)不同方法的对比 | |
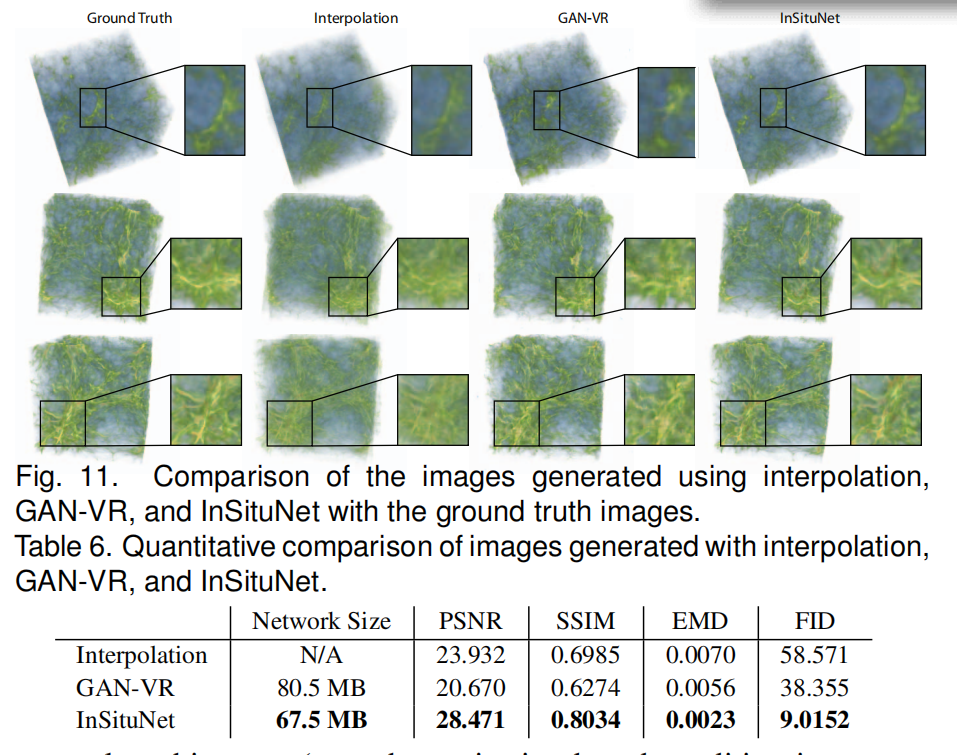 Nxy数据集,两种方法,对比发现,本论文的方法性能更优 |
| ⑤参数空间探究 | |
|---|---|
| (1)Nxy仿真参数探究 | 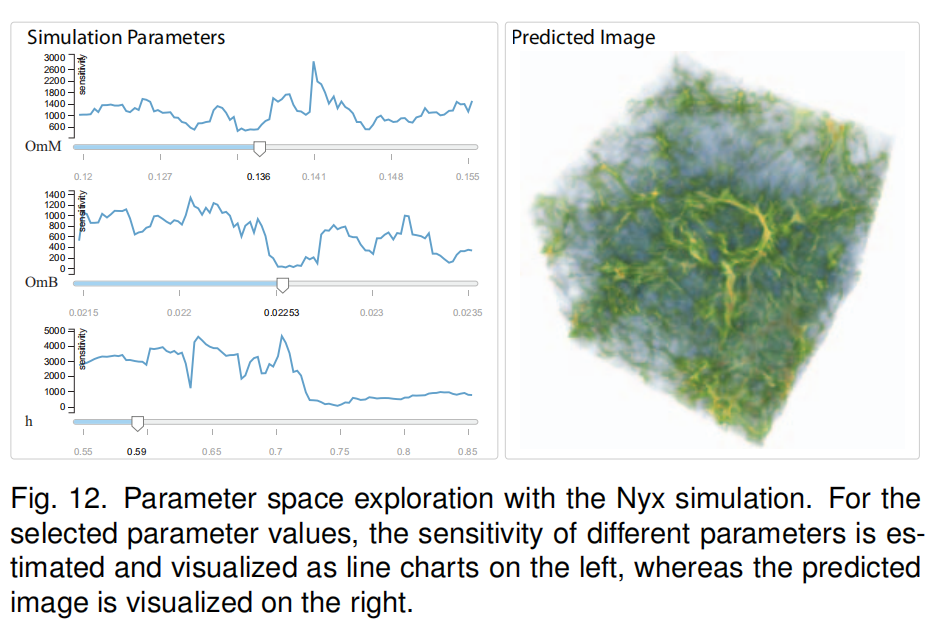 ) )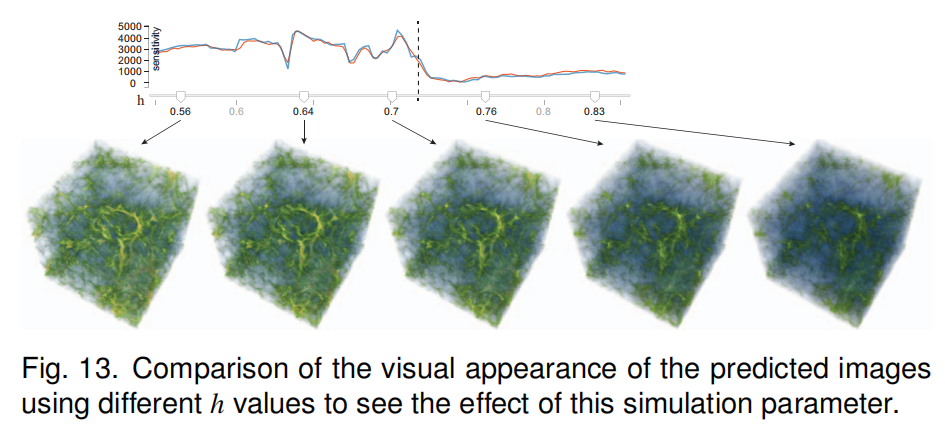 |
| (2)MPAS-Ocean仿真参数探究 |  |
| 讨论以及结论 | 说明 |
|---|---|
| ①模型限制 | (1)限制了任意visual mapping parameters的探究; (2)数据集的影响; (3)输出图像大小有限制,模型结构、性能的都有待未来研究。 |
| ②结论 | 本文提出了InSituNet,一个基于深度学习的图像合成模型,支持大规模集成仿真的参数空间探索。通过可视化界面,可以探究已训练的模型下的不同仿真参数输入下的预测。通过定量和定性的评估,我们验证了InSituNet在分析模拟不同物理现象的集成仿真中的有效性。 |