
初步使用,具体特征的意思,运算过程还有待跟进…感觉一堆知识要补。
基本操作
正常人听觉的频率范围大约在20Hz~20kHz之间。
采样频率是指将模拟声音波形进行数字化时,每秒钟抽取声波幅度样本的次数。
根据奈奎斯特采样理论,为了保证声音不失真,采样频率应该在40kHz左右。
常用的音频采样频率有8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz等,
如果采用更高的采样频率,还可以达到DVD的音质。
对采样率为44.1kHz的AAC音频进行解码时,一帧的解码时间须控制在23.22毫秒内。
通常是按1024个采样点一帧
分析:
- AAC
一个AAC原始帧包含某段时间内1024个采样点相关数据。
用1024主要是因为AAC是用的1024点的mdct。
音频帧的播放时间 = 一个AAC帧对应的采样样本的个数 / 采样频率(单位为s)。
采样率(samplerate)为 44100Hz,表示每秒 44100个采样点,
所以,根据公式,
音频帧的播放时长 = 一个AAC帧对应的采样点个数 / 采样频率
则,当前一帧的播放时间 = 1024 * 1000000/44100= 22.32ms(单位为ms)
48kHz采样率,
则,当前一帧的播放时间 = 1024 * 1000000/48000= 21.32ms(单位为ms)
22.05kHz采样率,
则,当前一帧的播放时间 = 1024 * 1000000/22050= 46.43ms(单位为ms)
2.MP3
mp3 每帧均为1152个字节,
则:
每帧播放时长 = 1152 * 1000000 / sample_rate
例如:sample_rate = 44100HZ时,
计算出的时长为26.122ms,
这就是经常听到的mp3每帧播放时间固定为26ms的由来
加载音频
这会将音频时间序列作为numpy数组返回,默认采样率(sr)为22KHZ mono。我们可以通过以下方式更改此行为:
1 | import librosa |
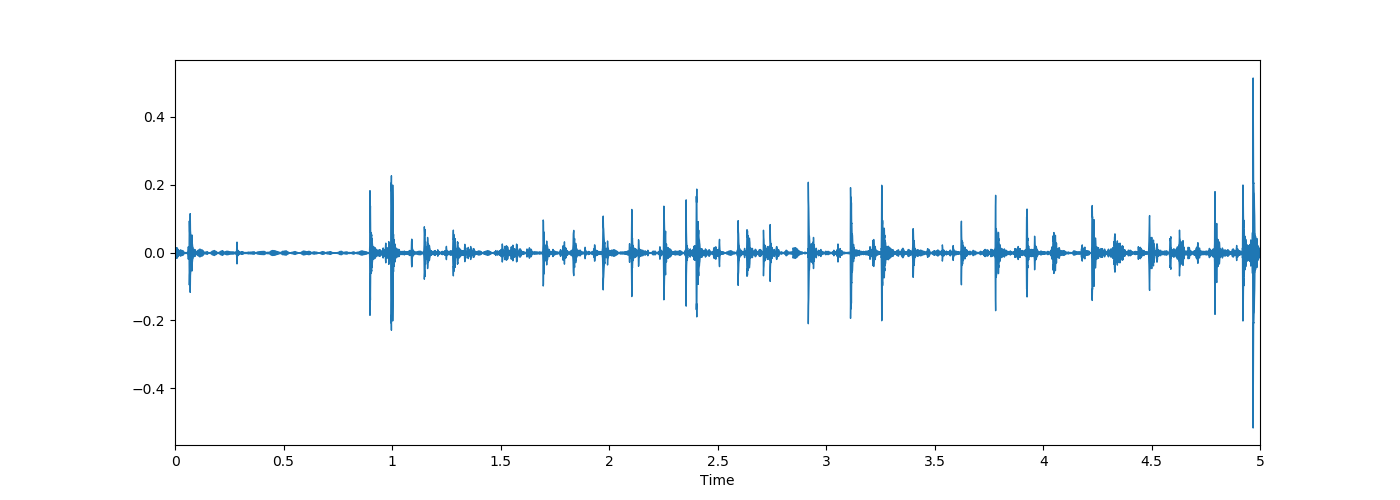
波形图
横坐标时间,纵坐标振幅
1 | import librosa |
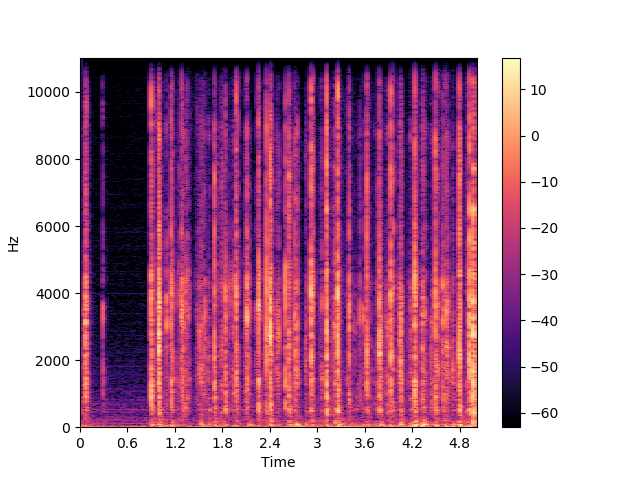
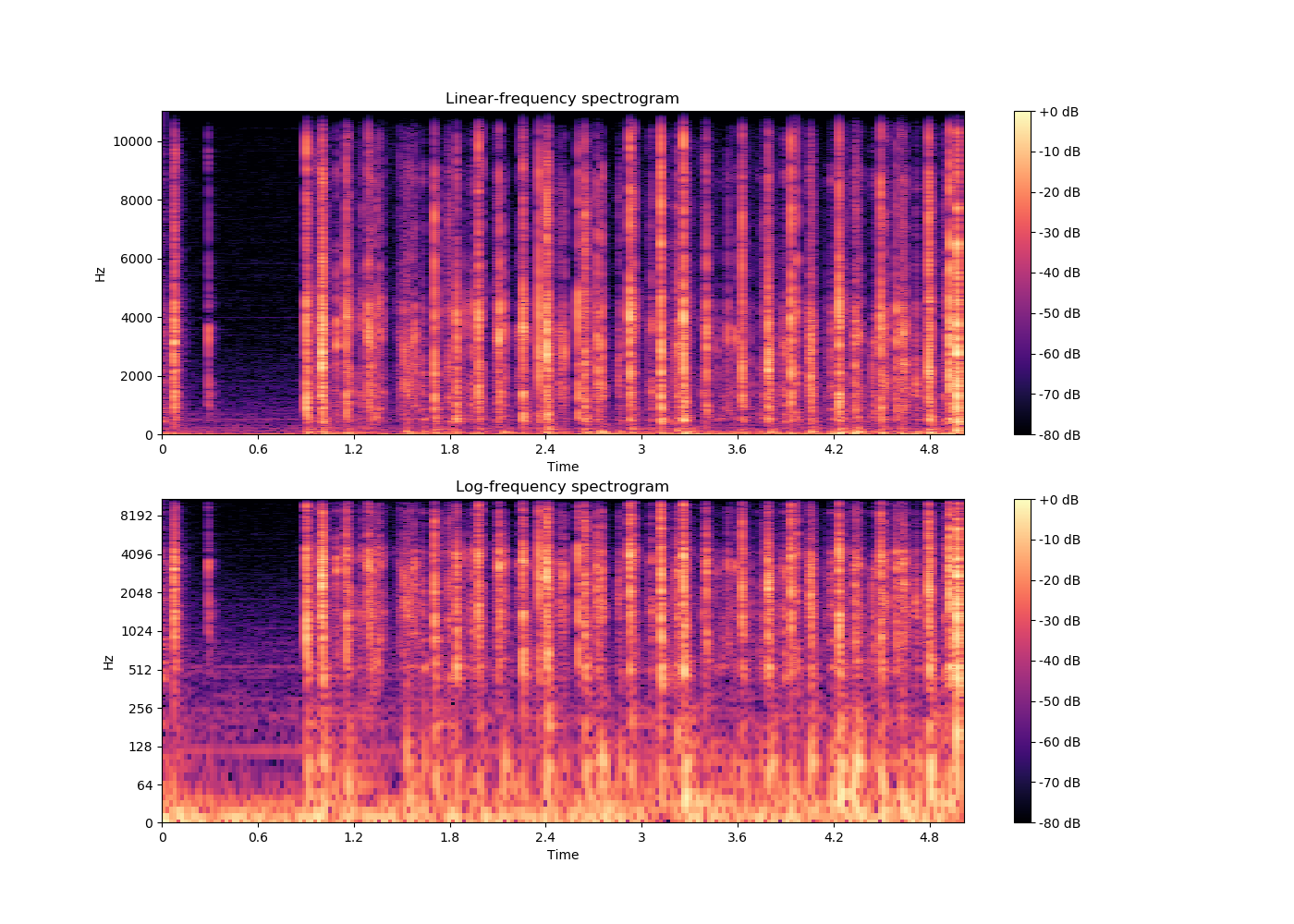
谱图
谱图是通过视觉表示频谱的频率、声音或其他信号,因为它们随时间变化。频谱图有时被称为超声波仪,声纹或语音图。当数据在3D图中表示时,它们可以称为waterfalls。在二维阵列中,第一轴是频率,而第二轴是时间。
1 | import librosa |
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
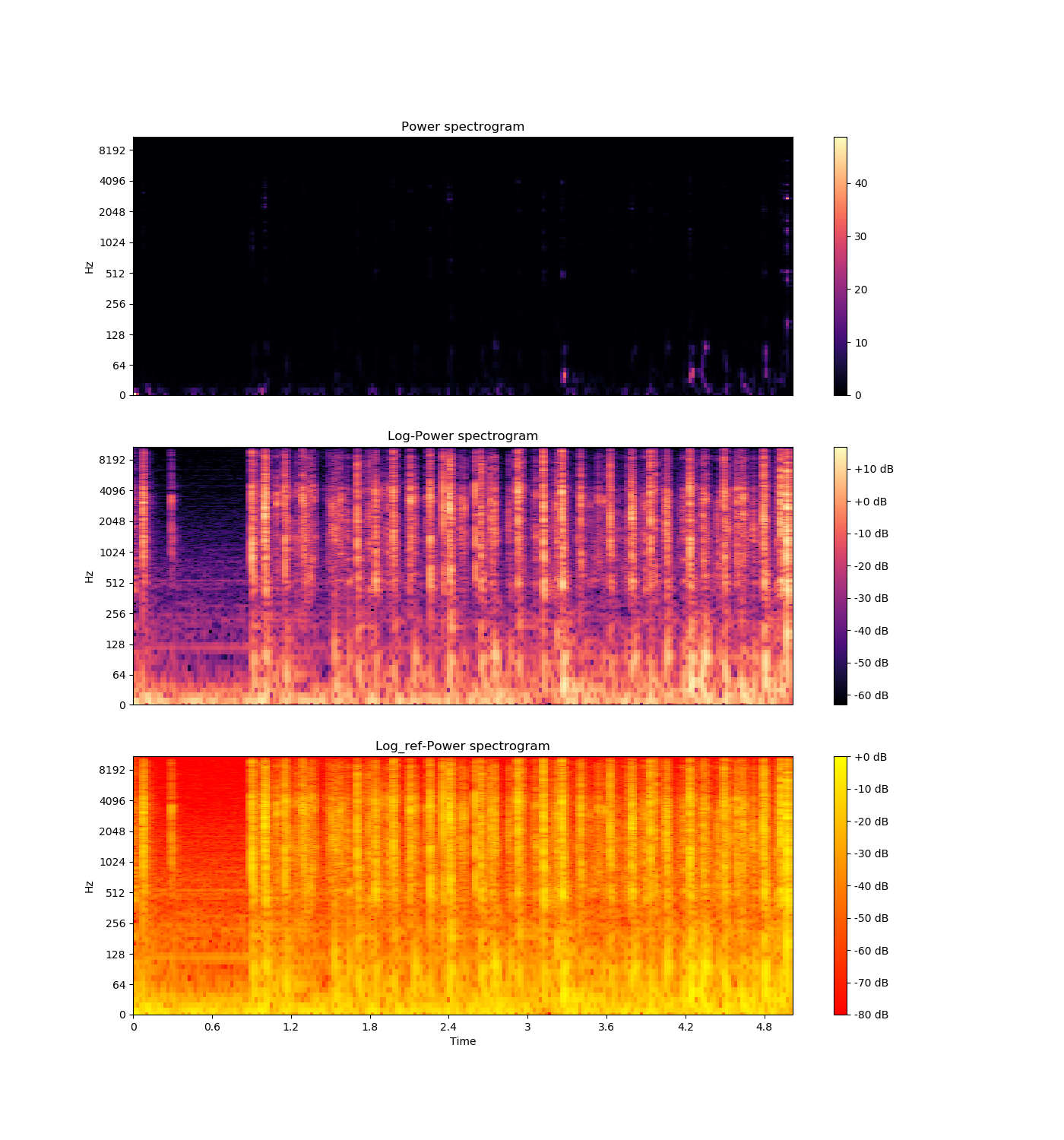
功率谱
将功率谱(幅度平方)转换为分贝(dB)单位.
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
播放音频/写音频
1 | import librosa |
1 | import librosa |
特征提取
过零率
该特征在语音识别和音乐信息检索中都被大量使用。对于像金属和岩石那样的高冲击声,它通常具有更高的值。让我们计算示例音频片段的过零率。
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
光谱质心
它指示声音的“质心”位于何处,并计算为声音中存在的频率的加权平均值。如果有两首歌曲,一首来自布鲁斯类型,另一首属于金属。与长度相同的布鲁斯流派歌曲相比,金属歌曲在最后有更多的频率。因此,布鲁斯歌曲的光谱质心将位于其光谱中间附近,而金属歌曲的光谱质心将朝向它的末端。
1 | import librosa |
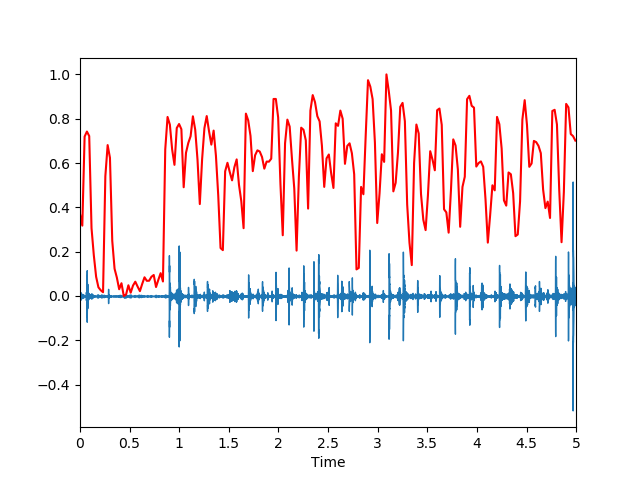
光谱衰减
它是信号形状的度量。librosa.feature.spectral_rolloff 计算信号中每帧的滚降系数:
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
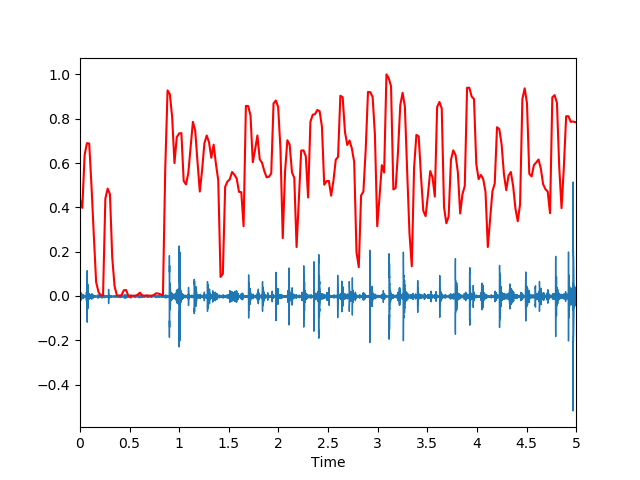
梅尔频率倒谱系数
信号的Mel频率倒谱系数(MFCC)是一小组特征(通常约10-20),其简明地描述了频谱包络的整体形状,它模拟了人声的特征。让我们这次用一个简单的循环波。MFCC特征是一种在自动语音识别和说话人识别中广泛使用的特征。
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
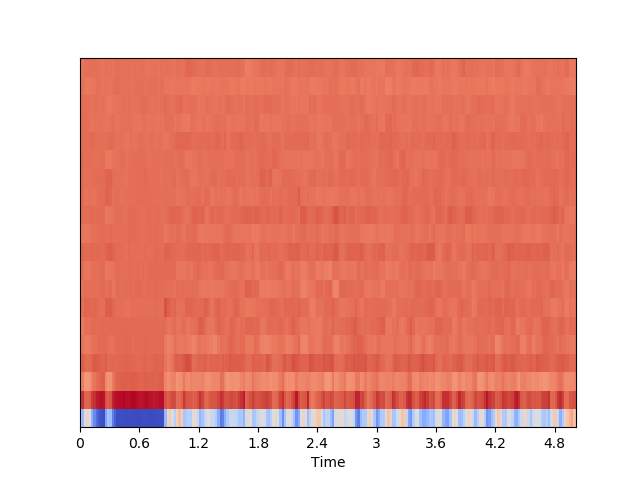
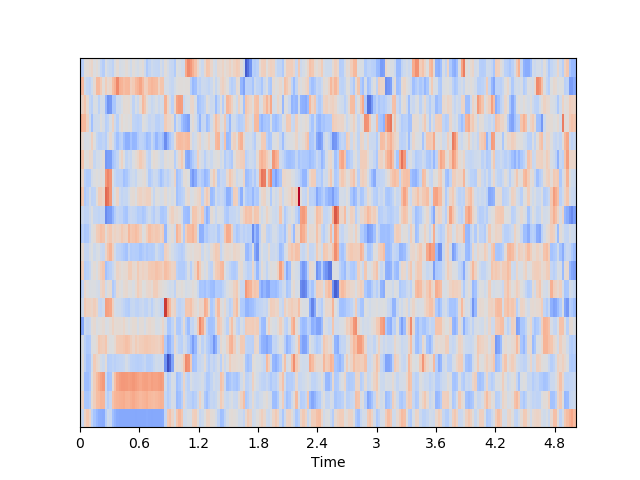
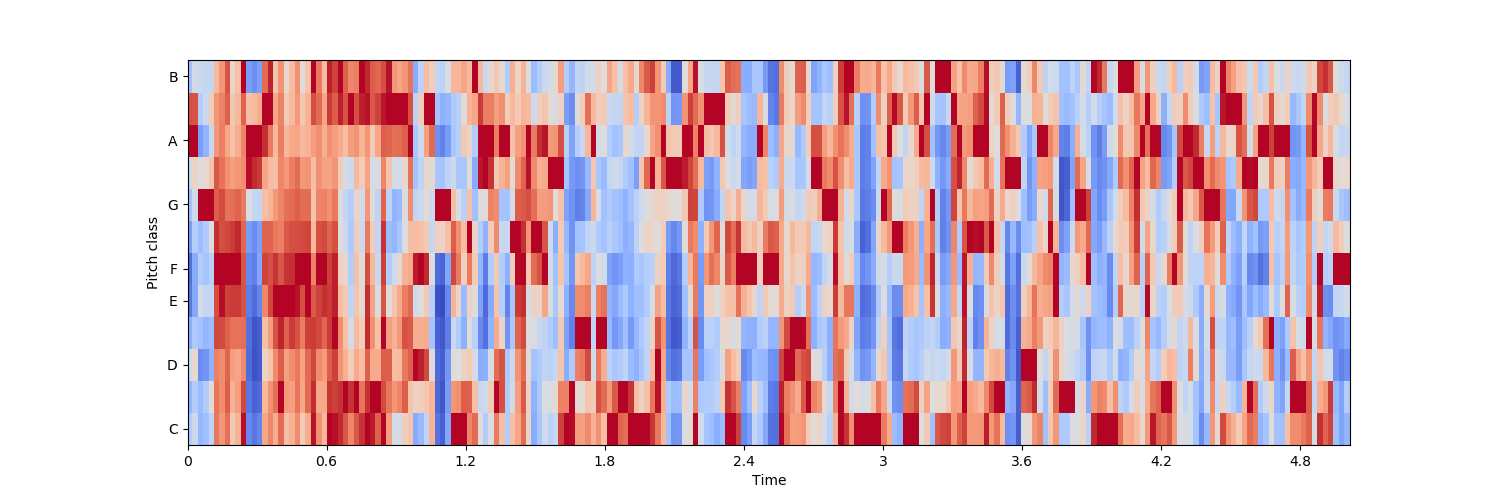
色度频率
色度频率是音乐音频有趣且强大的表示,其中整个频谱被投影到12个区间,代表音乐八度音的12个不同的半音(或色度),librosa.feature.chroma_stft 用于计算。
1 | import librosa |
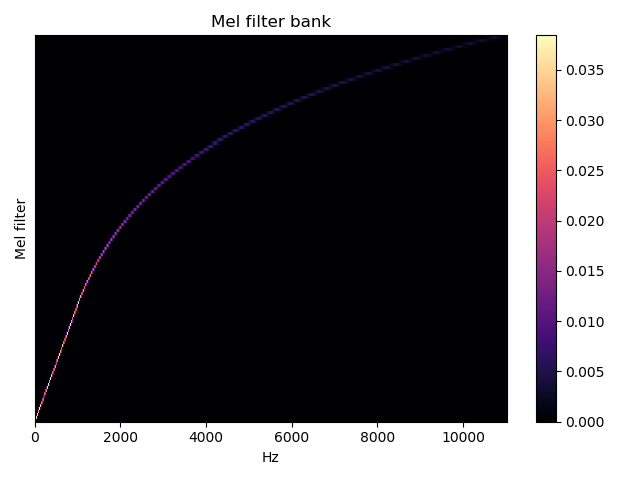
Mel滤波器组
1 | import librosa |
Mel scaled频谱
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
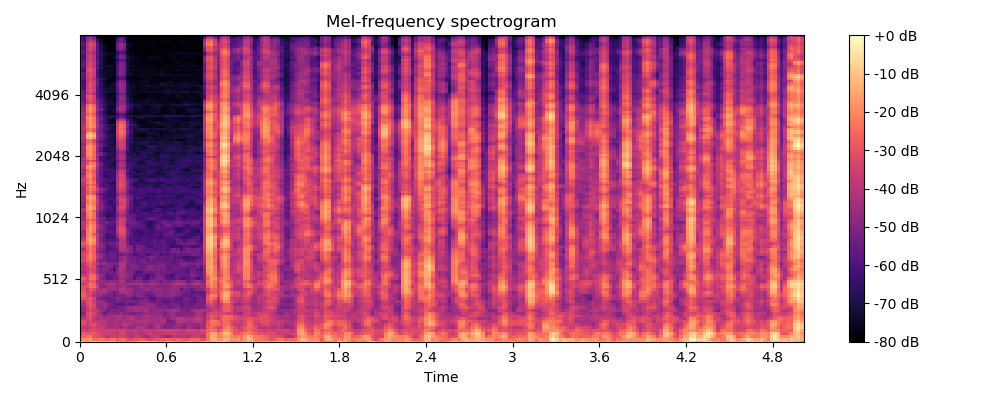
Log-Mel Spectrogram特征
Log-Mel Spectrogram特征是目前在语音识别和环境声音识别中很常用的一个特征,由于CNN在处理图像上展现了强大的能力,使得音频信号的频谱图特征的使用愈加广泛,甚至比MFCC使用的更多。在librosa中,Log-Mel Spectrogram特征的提取只需几行代码:
1 | import librosa |
1 | <class 'numpy.ndarray'> <class 'int'> |
可见,Log-Mel Spectrogram特征是二维数组的形式,128表示Mel频率的维度(频域),216为时间帧长度(时域),所以Log-Mel Spectrogram特征是音频信号的时频表示特征。其中,n_fft指的是窗的大小,这里为1024;hop_length表示相邻窗之间的距离,这里为512,也就是相邻窗之间有50%的overlap;n_mels为mel bands的数量,这里设为128。