
| 类型 | 说明 |
|---|---|
| 论文信息 | Deep auscultation: Predicting respiratory anomalies and diseases via recurrent neural networks Diego Perna ; Andrea Tagarelli |
| 会议期刊 | 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS) |
| 介绍 | 说明 |
|---|---|
| ①背景介绍 | 世界卫生组织定义了五大导致严重疾病和死亡的呼吸疾病: (1)慢性阻塞性肺病(Chronic Obstructive Pulmonary Disease(COPD)) (2)哮喘(Ashma) (3)急性下呼吸道感染(Acute Lower Respiratory Tract Infection(LRTI)) (4)肺结核(Tuberculosis) (5)肺癌(Lung Cancer)。 预防、早期诊断以及治疗是限制这些疾病对于生活质量以及生命长度影响。肺部诊断是呼吸检测必要组成部分,有助于诊断多种疾病,例如在呼吸循环中以异常声音的形式出现的异常(例如,噼啪声(Crackles)和喘息声(Wheezes))。 |
| ②本文创新点 | (1)提出了能够有效处理呼吸疾病预测问题(病理水平以及异常水平——慢性病(COPD,支气管扩张、哮喘)以及急性病(上呼吸道感染、下呼吸道感染,肺炎、支气管炎))的基于循环神经网络的模型框架,因为RNN能够有效发现声音数据的与时间相关的模式,之前还没有充分的使用RNN方法用于该领域。(不同解决方案(两类或多类问题)) (2)提出了一种预处理方法,用于灵活地提取倒频谱特征核心组。 |
| 数据集ICBHI | 说明 |
|---|---|
| ①来源 | 两支来自两个国家的研究团队独立收集。 (采集设备多样、采集胸腔位点也不同、环境噪声也不同) |
| ②标签 | 总共126个病人,两种标签: (1)对于每个呼吸循环是否有crackles或wheezes (2)对于每个病人,是否有预设的特定疾病类别。 ICBHI挑战赛的参与者都关注于第一种更为精细的标签。 |
| ③异常声音 | (1)爆裂声(Crackes)是不连续的、爆发性的、非音乐性的偶发性肺音,通常根据其持续时间、响度、音高、呼吸周期中的时间以及与咳嗽和体位变化的关系,将其划分为细或粗的爆裂声。这两种类型的裂纹通常根据它们的持续时间来区分:粗裂纹长于10ms,细裂纹小于10ms。Crackes的频率范围是60-2000赫兹,最有用的频率是1200赫兹 (2)相反,喘息是一种高频的连续的、音乐性的、不确定的肺部声音,通常以400hz(或更高)的主导频率和正弦波为特征。虽然连续声音的标准定义包括持续时间超过250毫秒,但wheeze不一定超过250毫秒,通常超过80-100毫秒。严重的胸内下气道阻塞或上气道阻塞可伴有吸气性喘息。哮喘和慢性阻塞性肺疾病(COPD)患者出现广泛性气道阻塞。然而,在用力呼气后接近呼气末时,健康人甚至可以检测到喘息(wheeze)。 (3)此外,wheezes的平均持续时间约为600 ms,具有较高的方差,最小持续时间和最大持续时间分别为26 ms和19 s;相反,裂纹的特征是平均持续时间约为50 ms,方差较小,最小持续时间值和最大持续时间值分别为分别为3毫秒和4.88秒。 |
| ④呼吸数据组成 | (1)记录了包含6898次呼吸循环总共5.5小时的数据,其中1874个包含crackes,886个包含wheezes,506个二者均有。 (2)总共920个来自于126个病人的带标注的音频文件,每个音频文件18s~23s,绝大多数都是20s。 (3)注释包括每个呼吸循环的起始和终止时间以及两类声音是否存在0/1标签。 (4)这些录音是使用不同的设备收集的,持续时间从10秒到90秒不等。平均呼吸周期为2.7 s,标准差约为1.17 s;中位数约为2.54秒,而总的时间范围由0.2秒至16秒以上。 |
| 训练集:测试集=8:2 |
| 相关工作 | 说明 |
|---|---|
| A.异常驱动的预测 | (1)基于隐马尔可夫模型(HMM)以及高斯混合模型的方法 |
| ①预处理过程包含了包括基于谱减法的噪声抑制步骤 | |
| ②模型输入:在50Hz~2000Hz范围内提取的梅尔倒频谱系数特征(MFCCs)及其一阶导。 | |
| ③性能提高到39.37% | |
| ④作者还测试了28个使用多数投票的分类器;这种方法使单个分类器的性能略有提高,但代价是增加了10倍的计算负担。 | |
| (2)基于标准信号处理技术的方法 | |
| ①预处理阶段由一个带通滤波器组成,其去除由于心音和其他噪声成分而产生的不需要的频率。 | |
| ②录音部分分为三个通道:噼啪声crackle、喘息声wheeze和背景噪声, | |
| ③通过短时傅里叶变换(STFT)对每个通道提取时频和时标特征。最后将得到的特征进行聚合并输入支持向量机分类器。该方法的准确率为49.86%,ICBHI评分高达69.27%。 | |
| (3)MNRNN方法 | |
| ①在最小预处理需求的情况下进行端到端的分类。 | |
| ②三大组件: a.基于两层递归神经网络的噪声分类器–用于预测每帧的噪音标签 b.异常分类器 c.一种掩码机制,它只选择无噪声的帧来输入异常分类器。 | |
| ③对噪声帧的检测精度达到85%的准确率,以及65%的ICBHI评分 | |
| (4)增强型决策树模型 | |
| ①利用两类特征:MFCCs以及低等级特征 | |
| ②主要用于评估二分类预测(健康/非健康),实现精度85% | |
| B.病理驱动的预测 | (本文早期的工作中,着重于从影响患者的病理角度来预测任务。另一个关键的区别是提取系数的输入单元,它对应的是整个记录,而不是呼吸周期。基于CNNs以及MFCCs系数特征,利用了类不平衡技术SMOTE的方法 |
| 本文关注点 | (1)处理异常驱动的预测问题,以及更具挑战性的病理驱动的预测问题。 |
| (2)基于RNN模型,利用整个ICBHI数据集,而没有忽略具有高噪声特征的音频。 | |
| (3)基于CNNs以及MFCCs系数特征,能够利用RNN结构发现依赖于时序的模式。 |
| 工作流程 | 说明 |
|---|---|
| 流程图 | 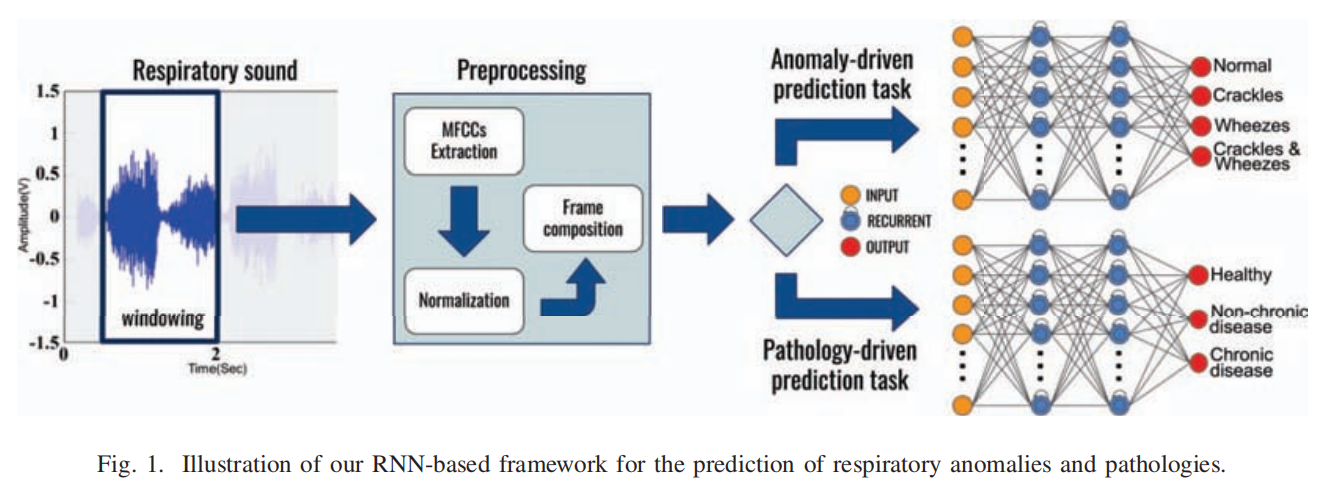 |
| (1)循环神经网络 | ①传统的神经网络结构是基于所有输入都是顺序独立的假设,而实际上,许多任务(例如时序分析、自然语言处理)的连续输入训练实例之间的联系至关重要,所以这种假设是不正确的,甚至是有害的。 |
| ②RNNs背后的基本思想是使网络能够记住过去的数据,目的是通过利用顺序信息来开发更好的模型。换句话说,RNNs可以保留关于过去的信息,使它能够发现数据中相距很远的事件之间的时间相关性。 | |
| ③早起RNNs模型存在梯度爆炸和梯度消失的问题,而近年来的长短期记忆LSTM以及门控循环单元GRU成功的解决了这类问题,使其脱颖而出。 | |
| ④本文框架利用了LSTM以及GRU的模型以及它们相应的双向版本BiLSTM和BiGRU | |
| 设置 | ①在两个预测任务重,使用相同的配置,即2层256个神经元结构,每层使用Tanh激活函数,keras框架 |
| ②为了避免过拟合,引入正则和循环丢弃(both regular and recurrent dropout),尝试了不同的对应丢弃值,发现较小的recurrent dropout能够略微改善预测结果。由于性能改进程度可忽略,所以本文对于两类丢弃法使用相同的值,30~60% | |
| ③此外,引入批量归一化(Batch Normalization, batch = 32)、Adam优化算法,学习率0.002,100个训练周期 | |
| (2)预处理 | |
| ①帧组合(Frame Composition) | a.对每个呼吸循环基于滑动窗口分段,如下图所示为不同尺寸设置下的配置 b.对于每个窗口分段提取MFCCs特征,最后将每个窗口的特征联结。由此产生的倒谱特征组构成一个帧,该帧表示输入循环神经网络的基本数据单元。 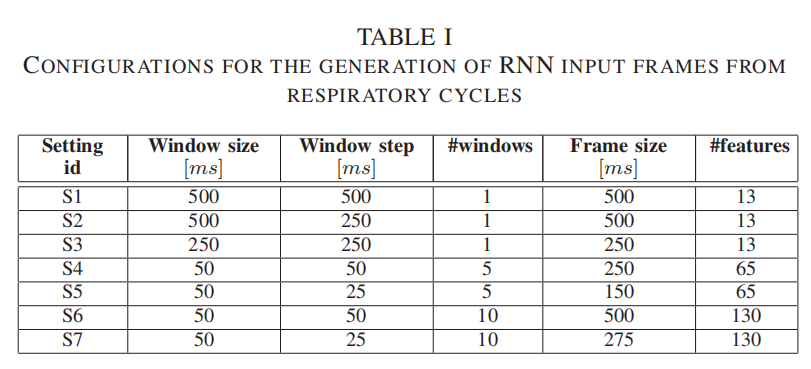 |
| ②特征提取(Feature Extraction) | a.提取梅尔倒频谱系数MFCCs,因为在语音识别领域,MFCC模型有着广泛而成功的应用。 b.本文将输入信号分成多个等长的音频帧,对于每一帧运用窗口函数,例如汉明窗口来减少频谱泄露(加窗主要是为了使时域信号更好地满足FFT处理的周期性要求,减少泄漏),随后,对每一帧,提取倒频谱特征向量以及应用直接傅里叶变换DFT。 c.此外,为了平滑频谱并强调感知上有意义的频率,我们将频谱成分聚合到更少的频率箱中。 d.最后,我们应用离散余弦变换(DCT)去相关滤波器组系数,并得到一个压缩的表示。 |
| ③特征归一化(Feature Normalization) | a.将神经网络的输入归一化可以通过限制陷入局部极小值的机会来提高训练速度(在误差面上更快地接近全局最小值) b.本文使用两种经典的归一化:Min-Max归一化($\frac{(x-x_min)}{(x_max-x_min)}$,是特征值固定在[0,1]范围内)以及Z-score归一化(零均值归一化/标准化)($\frac{x-\mu}{\rho}$,$\mu,\rho$分别为总体均值和总体标准差) |
| 评价指标 | 说明 |
|---|---|
| (1)ICBHI指定指标:微平均Micro-averaging | 包括敏感性Sensitivity和特异性Specificity,其平均值称为ICBHI score |
| (2)宏平均Macro-averaging |
| 实验 | 说明 |
|---|---|
| A.Impact of feature normalization on RNN performance | 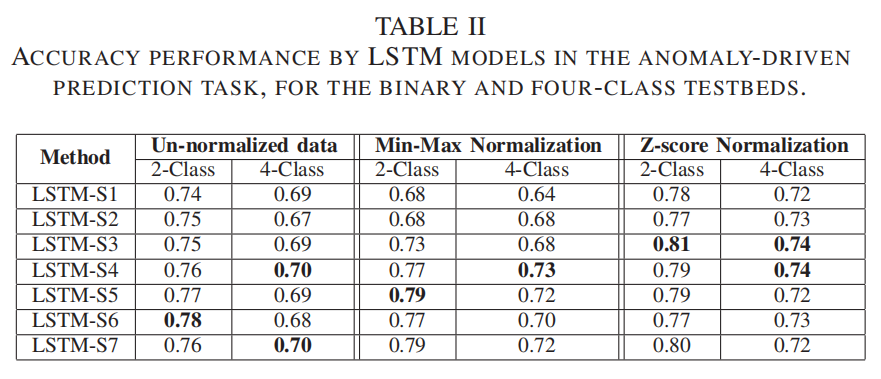 二分类:有误异常存在;四分类:正常、存在crackles,存在wheezes,二者均存在 如表2所示,针对LSTM模型,Z-score Normalization相比于另两种归一化方法更能提高预测精度。而其他RNN模型也显示了相似的结果。故后续实验均采用Z-score Normalization |
| B.Comparison of RNN models | 四种RNN模型的比较:LSTM、GRU、BiLSTM、BiGRU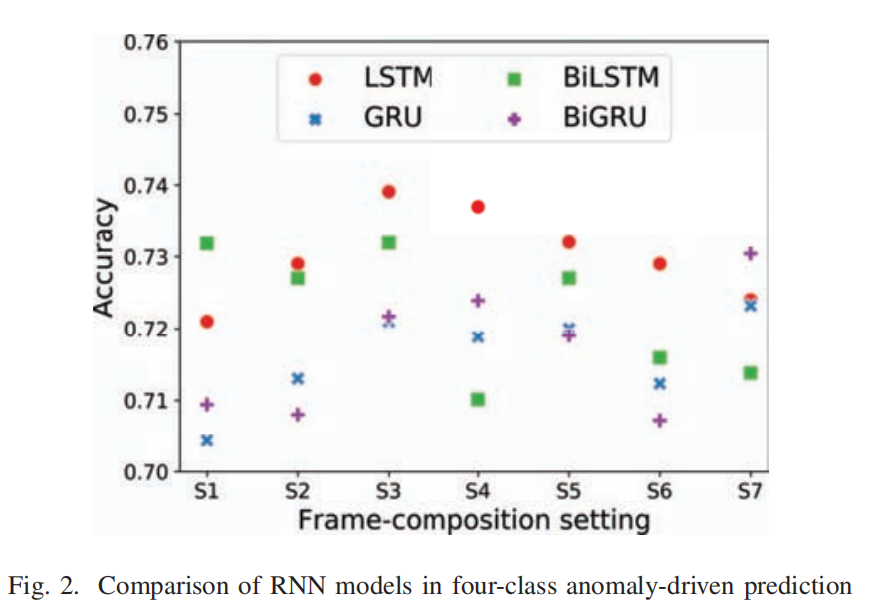 |
| ①四种模型的性能接近,准确率在0.70~0.74范围内。 ②而BiLSTM模型在S4和S1设置中差异较大,分别为其对应设置下的最差结果与最优结果。 ③总体而言,LSTM模型能够在多种设置条件下持续取得更好的结果。 ④训练时间:LSTM 13分钟,GRU 11分钟,BiLSTM 26分钟,BiGRU 22分钟。 后续实验均使用LSTM进行 | |
| C.Comparison with the ICBHI Challenge competitors | 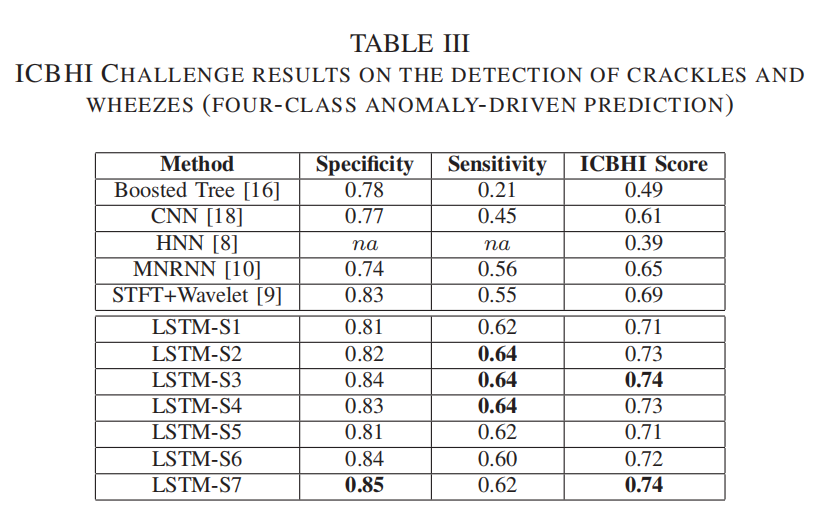 |
| D.Performance on the pathology-driven prediction tasks | 病理驱动的预测任务:二分类(健康/非健康),三分类(健康、慢性病,非慢性病)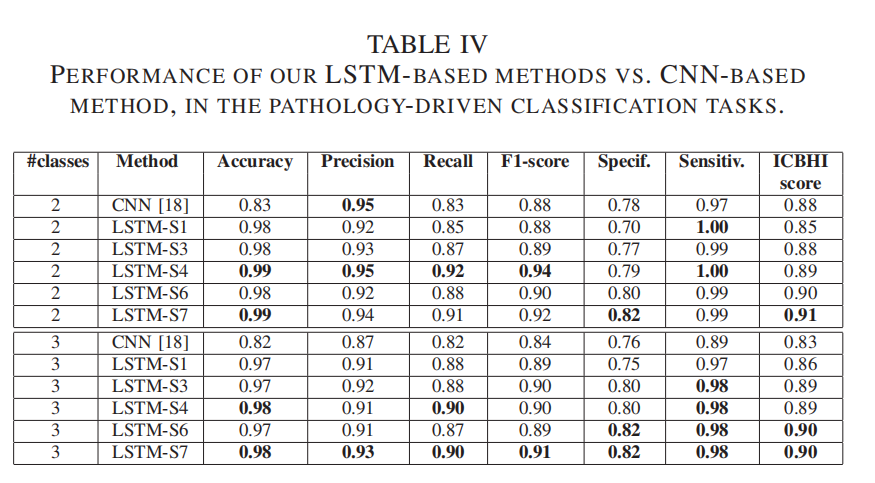 |
| 结论及未来工作 | 说明 |
|---|---|
| 结论 | 本文提出的引入RNN模型以及基于MFCC特征进行呼吸异常/疾病(慢性病/非慢性病)检测方法,在两类预测任务中达到先进水平。 |
| 未来工作 | ①其他可选DL模型引入或混合 ②呼吸声音的不同表示模型(即不同音频预处理方法,不同的特征)对于训练模型的影响。 ③特别对于能够利用时序表示(无论是频域还是时域以及MFCCs)的混合模型感兴趣。 |