
| 评价指标 | 说明 |
|---|---|
| 混淆矩阵 | 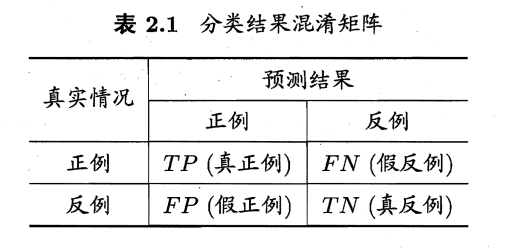 |
| 灵敏度Sensitivity 召回率Recall(查全率) | 即真正例率(True Positive Rate, TPR)$$Sensitivity = \frac{TP}{TP+FN}$$ |
| 特异性Specificity | 即真负类率(True Negative Rate) $$Specificity = \frac{TN}{TN+FP}$$ |
| 准确率Accuracy | $$Accuracy = \frac{TP+TN}{TP+TN+FP+FN}$$ |
| 精确率Precision(查准率) | 即正预测值(Positive Predictive Value)$$Precision = \frac{TP}{TP+FP}$$ |
| F1 Score | Sensitivity与Precision的调和平均数(Harmonic Mean)$$F1\, Score = \frac{2\times \left(Sensitivity\times Precision\right)}{\left(Sensitivity + Precision\right)}$$ |
| J Score | 即Youdens J statistic$$J\, Score = Sensitivity + Specificity - 1$$ |
| 假正例率False Positive Rate(FPR) | $$FPR = 1 - Specificity$$ |
| AUC(Area Under the curve) | Recevier Operating Characteristic(ROC)接受者操作特征曲线: TPR与FPR在不同阈值下的曲线,代表二分类器的正确检测能力 $$AUC \in [0,1] \\Ideal: 1$$ |
很多时候我们有多个二分类混淆矩阵,例如进行多次训练/测试,每次得到一个混淆矩阵;或是在多个数据集上进行训练/测试,希望估计算法的”全局”性能;甚或是执行多分类任务,每两两类别的组合都对应一个混淆矩阵,….总之,我们希望在 个二分类混淆矩阵上综合考察查准率和查全率
| 分类 | 说明 |
|---|---|
| 宏平均Macro-averaging | 一种直接的做法是先在各混淆矩阵上分别计算出查准率和查全率,记为 $(P_1, R_1),…(P_n,R_n)$ 再计算平均值,这样就得到”宏查准率” (macro-P) “宏查全率” (macro-R) ,以及相应的”宏F1” (macro-F1) |
| $$P_{macro}=\frac{1}{n}\sum^{n}_{i=1}P_i$$ | |
| $$R_{macro}=\frac{1}{n}\sum^{n}_{i=1}R_i$$ | |
| $$F1_{macro}=\frac{2\times P_{macro} \times R_{macro}}{P_{macro}+R_{macro}}$$ | |
| 微平均Micro-averaging | 还可先将各泪淆矩阵的对应元素进行平均,得到 $TP, FP, TN, FN$平均值,分别记为 $\overline{TP},\overline{FP},\overline{TN},\overline{FN}$,再基于这些平均值计算出”微查准”(micro-P) “徽查全率” (micro-R) 和”微F1” (micro-F1) |
| $$P_{micro}=\frac{\overline{TP}}{\overline{TP}+\overline{FP}}=\frac{TP_1+…+TP_n}{TP_1+…+TP_n+FP_1+…+FP_n}$$ | |
| $$R_{micro}=\frac{\overline{TP}}{\overline{TP}+\overline{FN}}=\frac{TP_1+…+TP_n}{TP_1+…+TP_n+FN_1+…+FN_n}$$ | |
| $$F1_{micro}=\frac{2\times P_{micro}\times P_{micro}}{P_{micro}+R_{micro}}$$ | |
| 举例-多分类问题 | 混淆矩阵转化为二分类问题,例如三分类(猫、狗、猪),对于每一类,都可以转化为二分类混淆矩阵,然后求各个评价指标,最后求对应的宏平均或微平均。 |
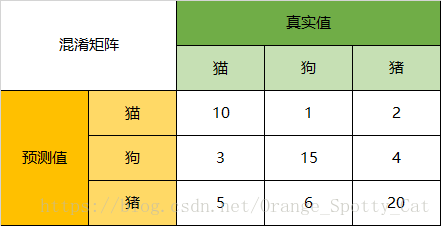 | |
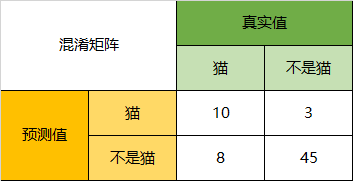 |