
| 类型 | 说明 |
|---|---|
| 论文信息 | Classifying environmental sounds using image recognition networks Venkatesh Boddapatia, Andrej Petefb, Jim Rasmussonb, Lars Lundberg |
| 会议期刊 | International Conference on Knowledge Based and Intelligent Information and Engineering Systems, KES2017, 6-8 September 2017, Marseille, France |
| 介绍 | 说明 |
|---|---|
| 简介 | 1.环境声音自动分类有助于智能家居、远程监控的应用 2.现有移动设备普遍有图像深度神经网络模型,本文研究用现有图像分类模型Alexnet、GoogLeNet模型进行语音分类 |
| 常用音频预处理方法 | 说明 |
|---|---|
| (1) Framing-based | 1) Framing-based where the audio signals are separated into frames using a Hamming window. Then the features are extracted from each frame and classified separately. |
| (2) Sub-framing | 2) Sub-framing based processing where the frames are further subdivided and each frame is classified based on the majority voting of the sub-frames. |
| (3) Sequential processing | 3) Sequential processing where the audio signals are divided into segments of typically 30 ms with 50% overlap. The classifier then classifies the features extracted from these segments. |
| 数据集 | 说明 |
|---|---|
| (1)ESC-10 | 400个5秒音频,10类,每类40个音频 |
| (2)ESC-50 | 2000个5秒音频,50类,每类40个音频 |
| (3)UrbanSound8K | 8732个<=4s的环境声音音频,共10类, {0: 1000, 1: 429, 2: 1000, 3: 1000, 4: 1000, 5: 1000, 6: 374, 7: 1000, 8: 929, 9: 1000} |
| 方法 | 说明 |
|---|---|
| (1)特征 | MFCC(Mel-Frequency Cepstral Coefficients)、Spectrogram、CRP(Cross Recurrence Plot)三类特征单通道图以及组合成的三通道图(256×256) ) ) |
| (2)模型 | AlexNet、GoogLeNet |
| (3)设置 | 五折交叉验证、32kHz采样率、帧长30ms、帧重叠率50%、50训练周期、学习率0.01、SGD优化器、学习率计划:指数(0.95)衰减、256×256 |
| 实验 | 说明 |
|---|---|
| (1)三类特征两种模型实验 | 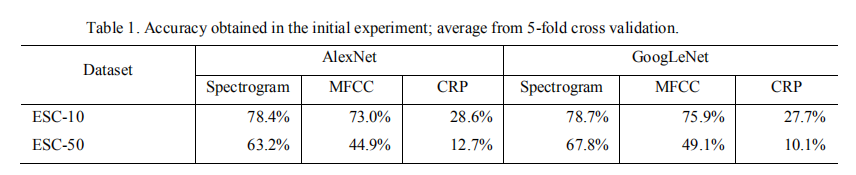 **** |
| (2)采样率实验 | 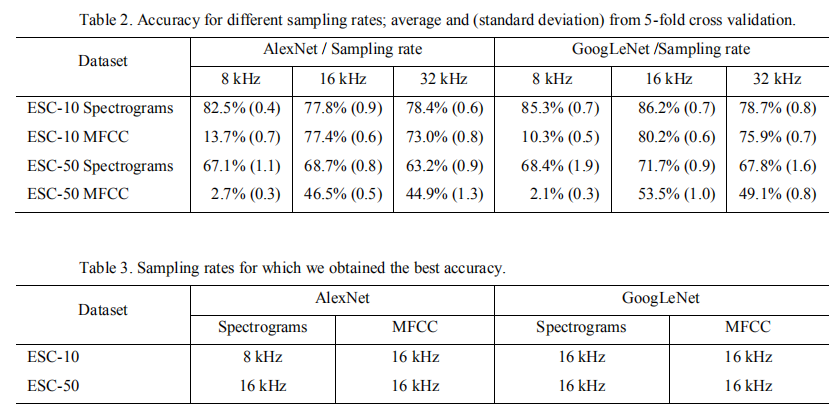 最优采样率分别用于后续实验 |
| (3)帧长实验 | 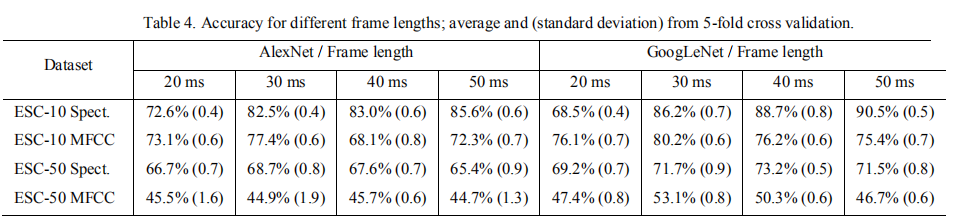 ) ) |
| (4)UrbanSound8K实验以及CRNN实验 | 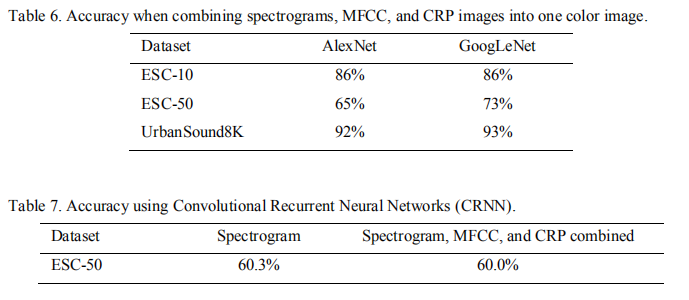 CRNN并没有提高准确度 |
| 结论 | 说明 |
|---|---|
| ① | 在ESC-50、ESC-10和UrbanSound8K数据集上,GoogLeNet的分类准确率分别为73%、91%和93%。 |
| ② | 三通道组合图并没有提高分类准确率、CRNN也没有得到较高精度 |