
音频处理期刊/会议
| 音频处理期刊/会议 | 名称 | 中科院分区 | CCF分区 | JCR分区 |
|---|---|---|---|---|
| 国际语音顶刊 | IEEE/ACM Transactions on Audio, Speech, and Language Processing(TASLP) | 中科院一区 | B类 | Q1 |
| 国际语音顶会 | IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) | / | B类 | / |
| 会议 | EUSIPCO European Signal Processing Conference(EUSIPCO) | / | / | / |
多项式分布采样
某随机实验如果有$k$个可能结局$A_1、A_2、…、A_k$,分别将他们的出现次数记为随机变量$X_1、X_2、…、X_k$,它们的概率分布分别是$p_1,p_2,…,p_k$,那么在$n$次采样的总结果中,$A_1$出现$n_1$次、$A_2$出现$n_2$次、…、$A_k$出现$n_k$次的这种事件的出现概率$P$有下面公式:
$p_1+p_2+p_3+…+p_k=1$
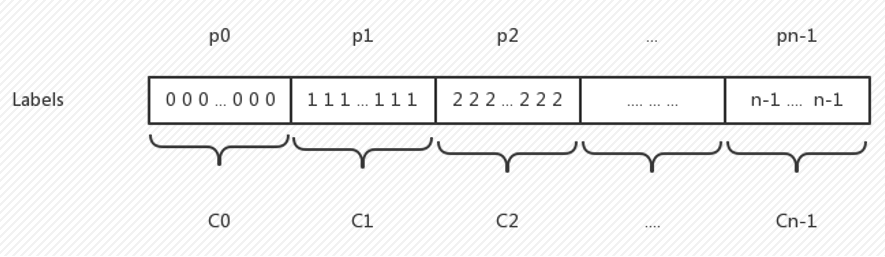
设$m$为每类样本数,$N$为采样总数,$n$为类数,则$N=n * m$;
为使每类样本平衡,且充分利用每类现有样本 (每类现有样本数分别为 $C_0,C_1,…,C_{n-1}$ ),则每类的每个样本选中概率应当相等,
即有每类样本概率分别为$p_0,p_1,p_2,…,p_{n-1}$。
那么,$N$次采样后应有以下关系:
$$N * p_0 * C_0=N * p_1 * C_1=…=N * p_{n-1} * C_{n-1}=m$$
即$$p_0=\frac{m}{N * C_0},p_1=\frac{m}{N * C_1},…,p_{n-1}=\frac{m}{N * C_{n-1}}$$
即每类样本概率:$p_i=\frac{m}{N * C_i},i=0,1,2,…n-1$,
可证得$p_0 * C_0 +p_1 * C_1 +p_2 * C_2 +…+p_{n-1} * C_{n-1}=\frac{m * n}{N}=1.$
Context
Respiratory sounds are important indicators of respiratory health and respiratory disorders. The sound emitted when a person breathes is directly related to air movement, changes within lung tissue and the position of secretions within the lung. A wheezing sound, for example, is a common sign that a patient has an obstructive airway disease like asthma or chronic obstructive pulmonary disease (COPD).
These sounds can be recorded using digital stethoscopes and other recording techniques. This digital data opens up the possibility of using machine learning to automatically diagnose respiratory disorders like asthma, pneumonia and bronchiolitis, to name a few.
Content
The Respiratory Sound Database was created by two research teams in Portugal and Greece. It includes 920 annotated recordings of varying length - 10s to 90s. These recordings were taken from 126 patients. There are a total of 5.5 hours of recordings containing 6898 respiratory cycles - 1864 contain crackles, 886 contain wheezes and 506 contain both crackles and wheezes. The data includes both clean respiratory sounds as well as noisy recordings that simulate real life conditions. The patients span all age groups - children, adults and the elderly.
This Kaggle dataset includes:
920 .wav sound files
920 annotation .txt files
A text file listing the diagnosis for each patient
A text file explaining the file naming format
A text file listing 91 names (filename_differences.txt )
A text file containing demographic information for each patient
Note:
filename_differences.txt is a list of files whose names were corrected after this dataset’s creators found a bug in the original file naming script. It can now be ignored.
General
1 | The demographic info file has 6 columns: |
Citation
Paper: Α Respiratory Sound Database for the Development of Automated Classification
Rocha BM, Filos D, Mendes L, Vogiatzis I, Perantoni E, Kaimakamis E, Natsiavas P, Oliveira A, Jácome C, Marques A, Paiva RP (2018) In Precision Medicine Powered by pHealth and Connected Health (pp. 51-55). Springer, Singapore.
https://eden.dei.uc.pt/~ruipedro/publications/Conferences/ICBHI2017a.pdf
Ref Websites
- http://www.auditory.org/mhonarc/2018/msg00007.html
- http://bhichallenge.med.auth.gr/
Acknowledgements
Many thanks to the research teams at the University of Coimbra, Portugal; the University de Aveiro, Portugal and the Aristotle University of Thessaloniki, Greece for making this dataset publicly available.
Inspiration
Build a model to classify respiratory diseases.
Build a model to detect if a recording contains crackles, wheezes or both.
Annotation is a time consuming process. Create a model to automatically annotate respiratory sound recordings.
Deploy your model as a Tensorflow.js web app so it can be accessed from anywhere in the world.
Bioelectronics - Can you build your own digital stethoscope using an Arduino? If you are an aspiring inventor, this video will give you some valuable practical advice: https://www.youtube.com/watch?v=jo1cQ-ga2MI
Photo by voltamax on Pixabay.
Utility functions for reading .wav files (especially pesky 24bit .wav)
1 | import wave |
Distribution of respiratory cycle lengths
1 | duration_list = [] |
Mel spectrogram implementation (With VTLP)
1 | import scipy.signal |
Data preparation utility functions
1 | #Used to split each individual sound file into separate sound clips containing one respiratory cycle each |
Data augmentation
Two basic forms employed : audio stretching (speeding up or down) as well as Vocal Tract Length perturbation
1 | #Creates a copy of each time slice, but stretches or contracts it by a random amount |
Utility used to import all training samples
1 | from sklearn.model_selection import train_test_split |
Data Pipeline
1 | import scipy.signal |
CNN implementation
1 | batch_size = 128 |
1 | from keras.utils.vis_utils import plot_model |
Data augmentation
1 | ######################## |