
| 类型 | 说明 |
|---|---|
| 论文信息 | Lung sounds classification using convolutional neural networks Dalal Bardou, Kun Zhang, Sayed Mohammad Ahmad |
| 会议期刊 | Artificial Intelligence in Medicine |
| 介绍 | |
|---|---|
| 背景 | (1)肺部声音能够表达与肺部疾病相关的信息,医生可以根据肺部声音评估患者的肺部状况,当前医生通常使用传统听诊技术诊断。听诊设备以其较廉价、非侵入式、安全、耗时少等优点常用于疾病诊断。然而,这种技术受医生专业程度以及经验,其可能会导致错误的诊断。同时,肺部声音是非平稳信号,难以通过传统听诊方法分析和区分。因此,使用电子听诊器,辅以模式识别系统能够有助于克服这些限制。 (2)肺部声音分为两类:正常呼吸声音以及偶发的呼吸声。当无呼吸系统疾病时,可以听到正常呼吸声,相反,则会听到偶发的异常呼吸声。正常呼吸声常伴有特定气管部位,如气管、支气管等的吸气或呼气时的低噪音或含高频成分的噪音;而偶发异常呼吸声则是叠加在此基础上的。 |
| 数据集 | 说明 |
|---|---|
| R.A.L.E Respiratory Sounds | (1)R.A.L.E(Respiration Acoustics Laboratory Environment), Respiratory Acoustics Laboratory of the University of Manitoba in Winnipeg, Cannada. (2)包含50+个音频记录,本文只选取了其中相关的15个音频文件,音频已经经过7.5Hz高通滤波以及2.5Hz低通滤波减少心脏声音的影响。每个音频被分为不重叠的40ms的片段,并由一位胸腔科医生验证检查。 |
| 音频数据信息 | 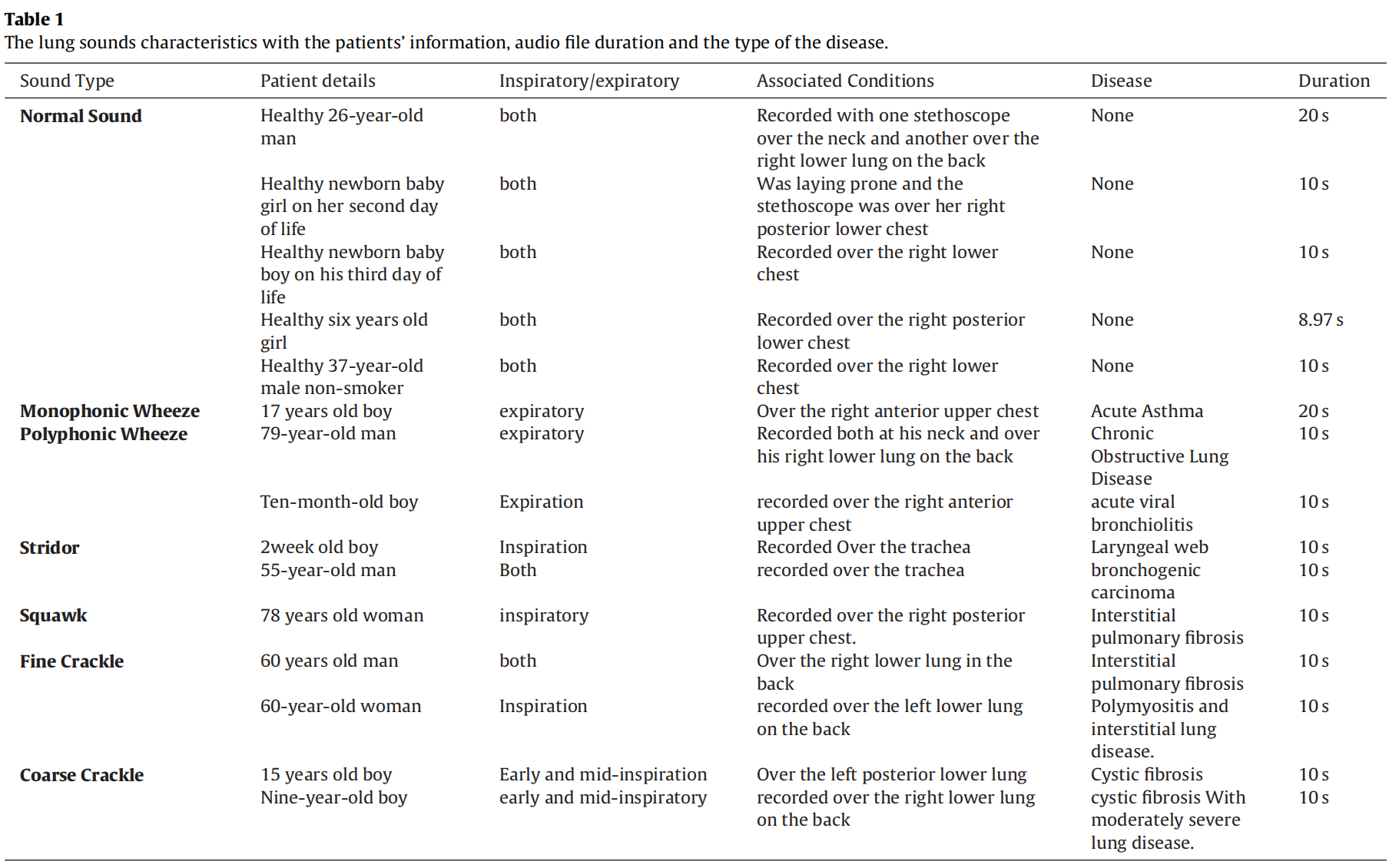 |
| 数据集划分 | 70%训练集 30%测试集,其中训练集的25%保留用于交叉验证,带找到最佳参数后,放回训练集进行训练 |
| 数据标准化 | 零均值归一化用于MFCC的6个统计量; 白化用于LBP特征 |
| 数据增强 | 说明 |
|---|---|
| (1)频谱图随机裁剪 | 其中一个基于频谱图进行分类的CNN模型中用到了该数据增强。 |
| (2)声道长度扰动Vocal tract length perturbation | 语音识别任务中提高识别性能的增强技术。 本文将其用于随机裁剪后的图片,这个有点问题,扰动怎么加到图像上的以及随机裁剪也有问题。 |
| 特征 | 说明 |
|---|---|
| (1)频谱图 | 一般为Mel-spectrogram,每个音频片段一个频谱图750×256,文中没有给出随机裁剪的尺寸! |
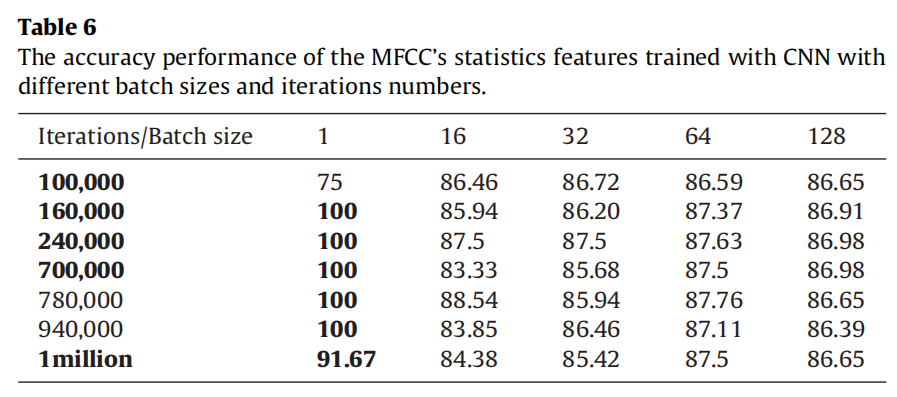
| (2)MFCC的6个统计量 | MFCC梅尔倒频谱系数,常用语音识别特征; 每个音频片段40ms,一般一个音频帧约23ms,这里提取的MFCC特征性状一般为(特征数,音频帧数),本文使用12个MFCC特征,应该是做了平均否则是个矩阵,而不是向量; 6个统计量:12个原始MFCC特征的均值、最大值、最小值、标准差以及其绝对差的均值、绝对差的标准差 |
 | |
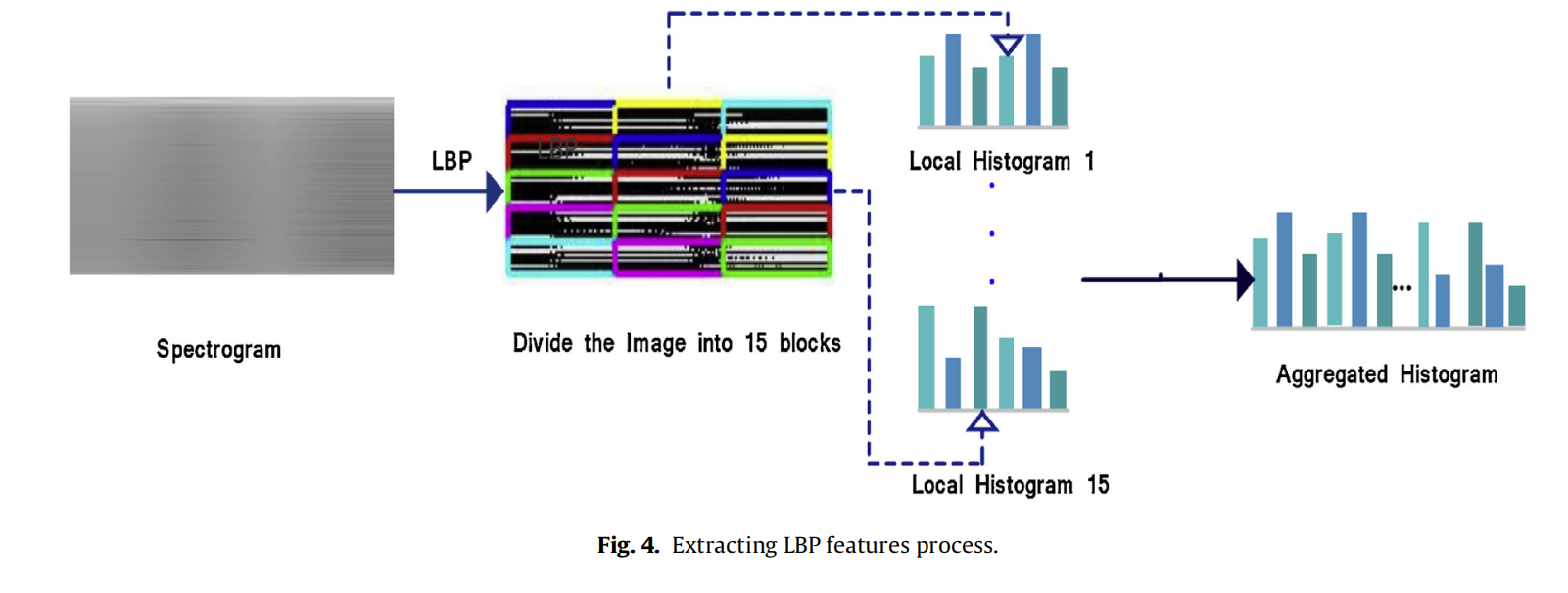
| (3)局部二元模式(Local Binary Patterns) LBP | 从频谱图上划分15个区域,每个区域上提取LBP特征,特征数为256,所以15个区域就有3840维的特征,通过PCA进行降维,仅保留累计方差百分比大于5%的特征 |
 |
| 分类 | 说明 |
|---|---|
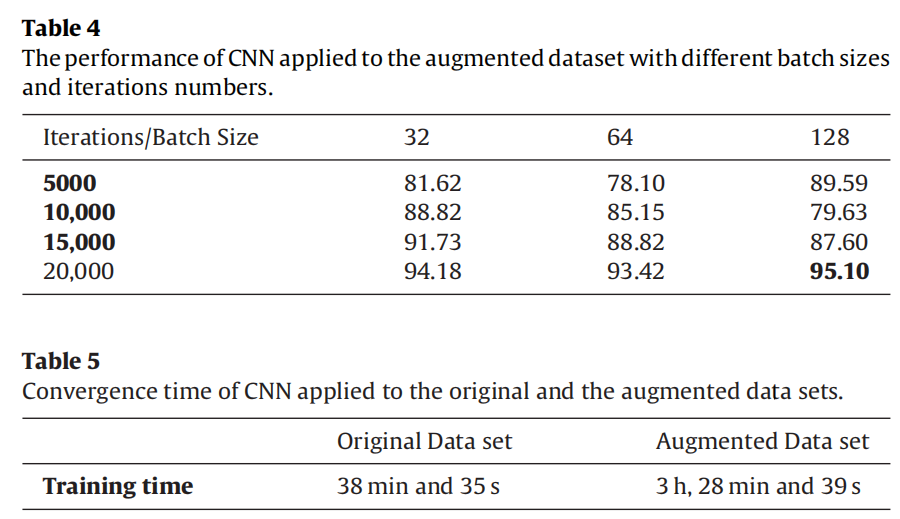
| (1)基于频谱图的CNN分类 | 总共12层模型,5层卷积,每个卷积后跟Relu激活以及一个3×3的最大池化层,最后跟两个全连接层(两层之间加一个50%丢弃层)。 SGD,leraning_rate=0.01,Xavier初始化权重 基于原始频谱图的分类:128批量,ACC 93.26%, 基于数据增强后的频谱图分类:ACC 95.10% |
 | |
| (2)集成模型 | 上一个基于频谱图的CNN模型,结构不变,分四个情况: ①数据增强+20000迭代;②数据增强+19656迭代;③原始数据+2286迭代;③原始数据+2664迭代; 四者最后的分类Softmax向量对应相加,然后取概率最大的为预测类别,即整合了四类CNN的预测结果,ACC 95.56% |
| (3)CNN+SVM | 上述CNN卷积层用于基于频谱图的训练进行特征提取,提取的特征输入SVM进行分类,ACC 88.54% |
| (4)CNN+MFCCs 6个统计量 | 两个全连接层,第一层2400神经元,第二层7个神经元,两层之间加Relu激活以及一个50%的丢弃层。 |
 | |
| (5)CNN+LBP | 三个全连接层,第一层1000个神经元(Relu, 50%丢弃层),第二层50个神经元,第三层7个神经元。 |
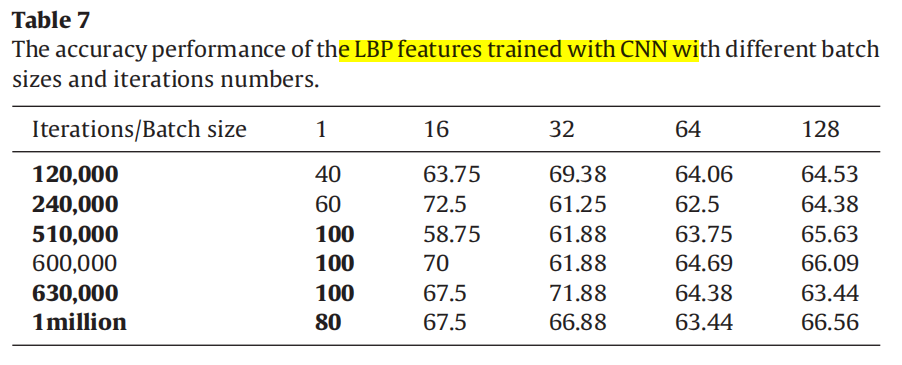 | |
| (6)三类传统分类器+MFCC 6个统计量 | 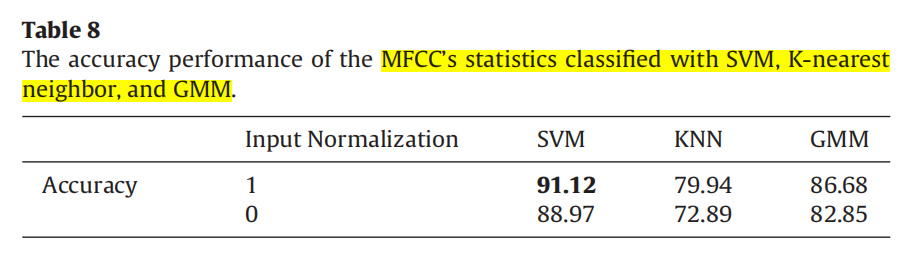 |
| (7)三类传统分类器+LBP | 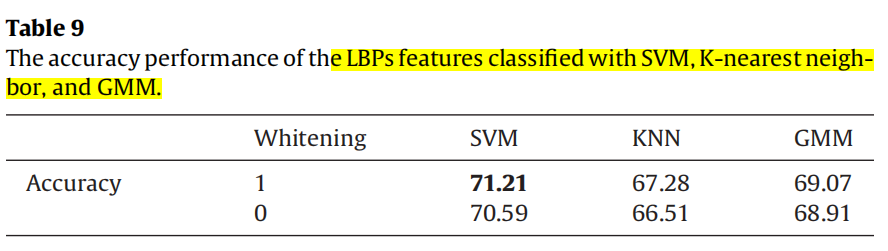 |
| 不同方式的ACC |  |
| 混淆矩阵 | 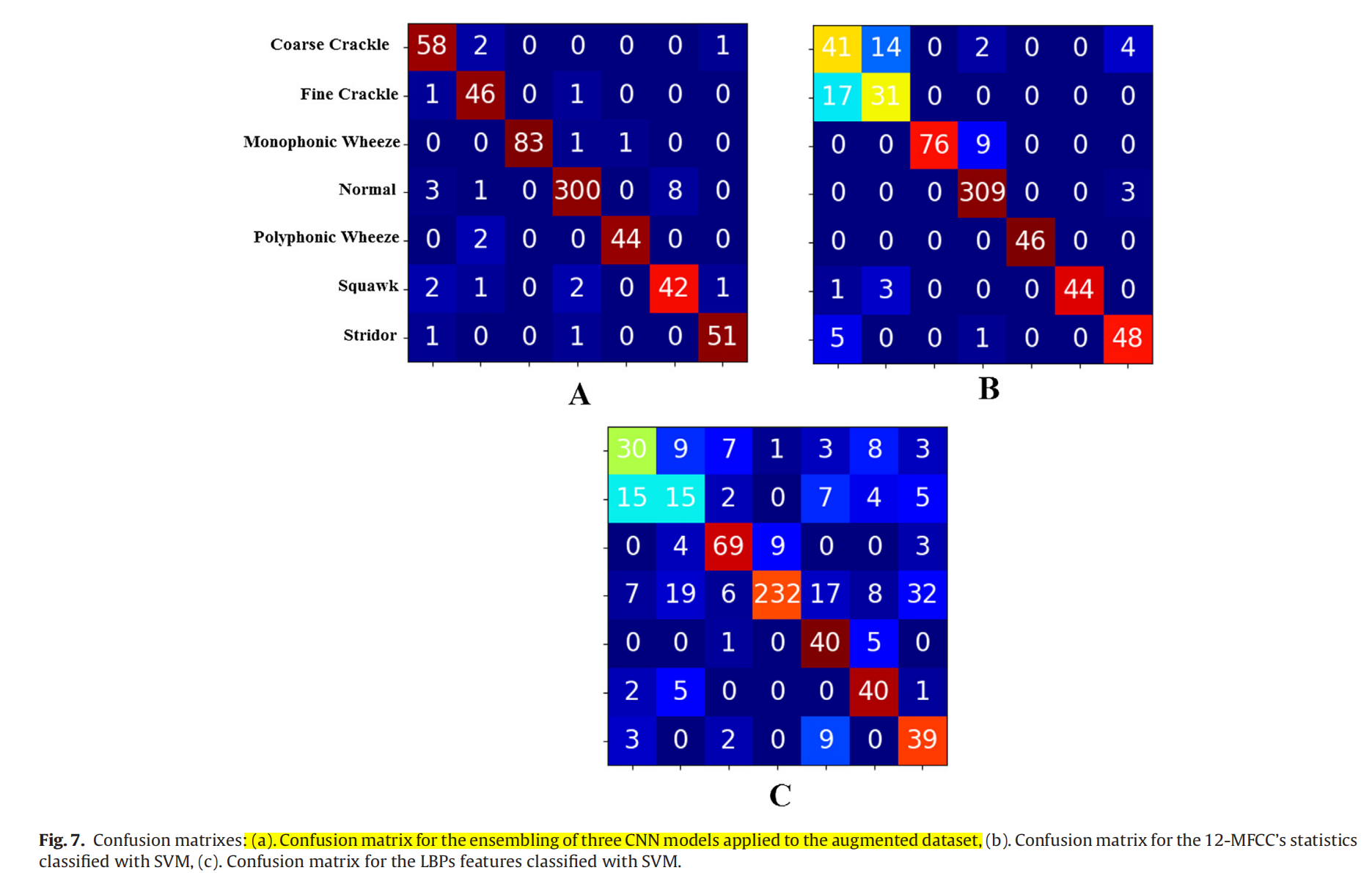 |
| Precision以及Recall | 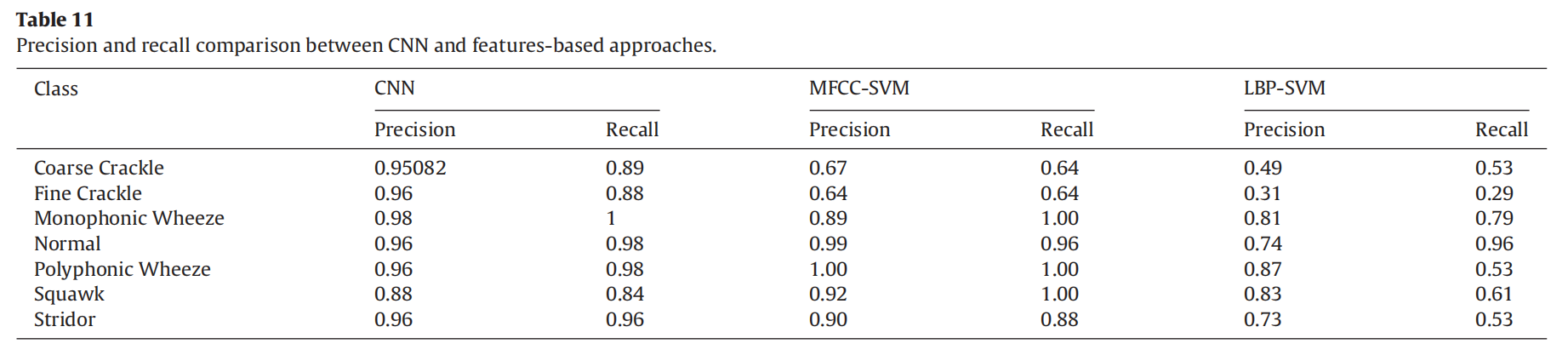 |
| 问题 | 说明 |
|---|---|
| (1) | 频谱图随机裁剪是否合适,以及裁剪的大小未告知,随机裁剪可能导致并没有裁剪到有异常点的位置,这个标签明显没有重新标注,也没法标注。 |
| (2) | 数据增强后的数据量没有告知,频谱图提取的参数未知 |
| (3) | 其原本10~20s的音频文件,为了增加数据集,切分成了40ms的片段,文中只给了一句由一位胸腔专家检查,以保证数据准确,40ms的数据重新打过标签吗?因为整个音频有对应异常声音部位,但切了以后可能有部分片段就没有了对应异常声音点。 |
| (4) | LBP特征提取,15个区域得到总的3840维特征进行降维,保留累计方差百分比高于5%的特征,那么极有可能每张图最后得到的特征维数不同,不知如何解决,pad? |
| (5) | 抛开第(3)点,切成40ms片段进行分类是否还有意义,然后最终定位回原始音频根据其含有异常片段数进行疾病评分? |
| (6) | 实验中用CNN训练六个统计量以及LBP,其实不是卷积网络了,而是普通的DNN,多层感知机。 |