
| 类型 | 说明 |
|---|---|
| 论文信息 | Triple-Classification of Respiratory Sounds Using Optimized S-Transform and Deep Residual Networks HAI CHEN, (Member, IEEE), XIAOCHEN YUAN , (Member, IEEE), ZHIYUAN PEI,MIANJIE LI, AND JIANQING LI, (Senior Member, IEEE) |
| 会议期刊 | IEEE Access |
| 介绍 | 说明 |
|---|---|
| 背景 | 典型的偶发异常呼吸音wheezes与crackles与哮喘、慢阻肺、肺炎等疾病相关联,相关领域研究已经研究数十年,然而,由于呼吸音包含杂音以及受限于特征提取方法,wheezes、crackles、normal三类的准确性和可靠性仍需要改进。 |
| 解决的问题 | 本文提出一种优化后的S变换特征提取方法,以及ResNet变体进行音频三分类 |
| 数据集 | ①ICBHI挑战赛数据集,总共489个音频记录,149个呼吸循环包含Wheezes,386个呼吸循环包含Crackles以及1125个呼吸循环包含正常呼吸音。 ②数据集划分train/test:70%/30% |
| 评价指标 | Accuracy、Specificity、Sensitivity,其中敏感度统计的为两类异常音作为正类的指标,特异性则统计的为正常音作为负类的指标 |
| 特征提取方法 | 说明 |
|---|---|
| (1) | 短时傅里叶变换STFT:较为常用的音频特征提取方法 |
| (2) | S-transform S变换:通过与特殊频率依赖窗口突出频率相关特征,它在低频率表现更宽而在高频率表现更窄;S变换是一种更好地时频方法。不仅如此,S变换唯独能够提供绝对相关的局部相信息和相应的频率特征。 |
| (3) | 本文提出的优化的S-transform:由于频率变换范围在100~2000Hz应当展现更多细节,可以进一步优化S变换,为了实现窗口变量更精确的控制,本文提出了一种优化的S变化方法提取特征。 |
| 三种特征提取方法,提取的频谱图通过双线性插值调整至224×224的图像大小作为神经网络的输入。 | |
| 特征图示 | 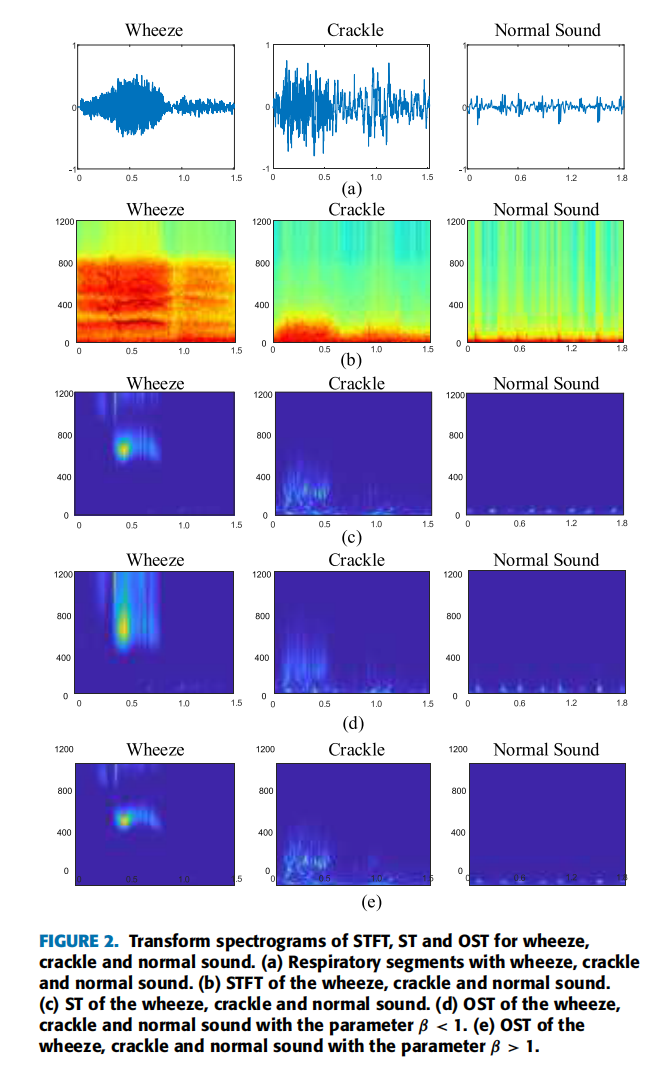 |
| 模型结构 | 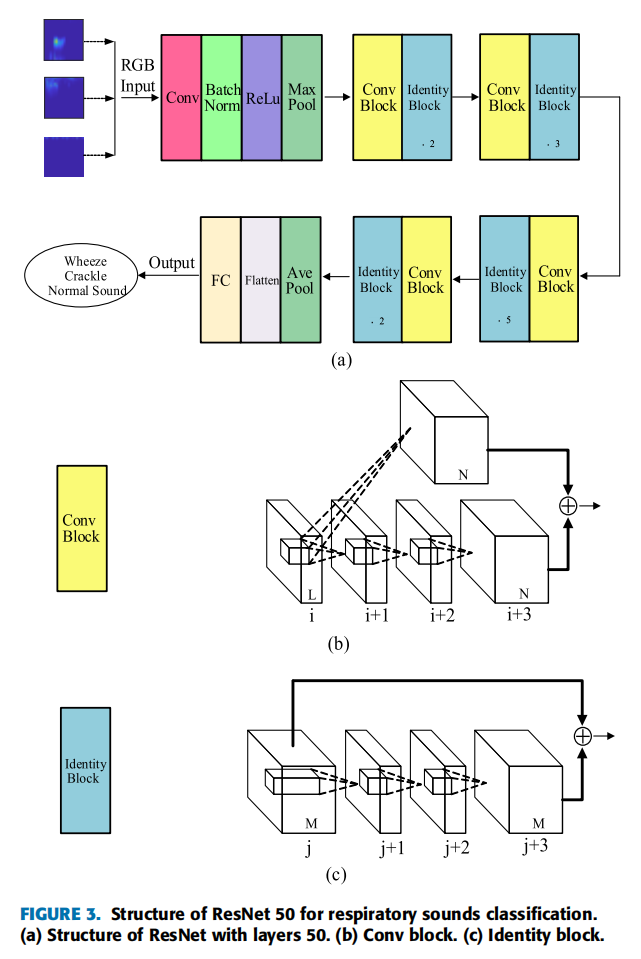 |
| 与典型图像分类的ResNet50的不同,这里ResNet模型结构有些不同,具体细节参数论文未给出,猜测为默认的ResNet50的参数,文中只给出了输入大小以及最后一个卷积层输出大小。 |
| 实验 | 说明 |
|---|---|
| (1)三类特征下ResNet分类 | 准确度: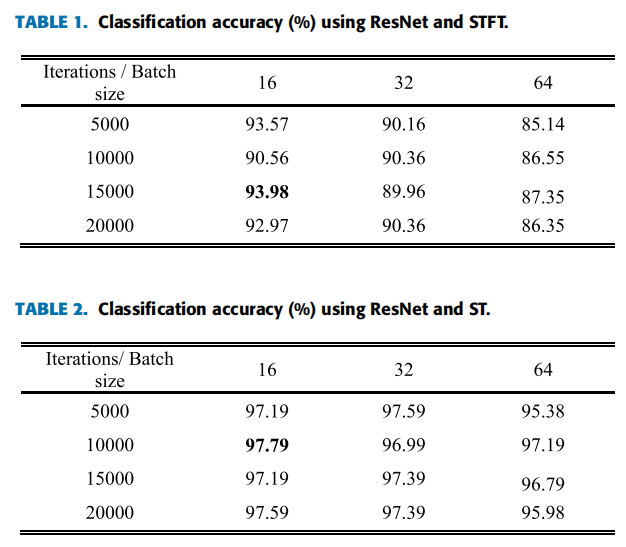 ) )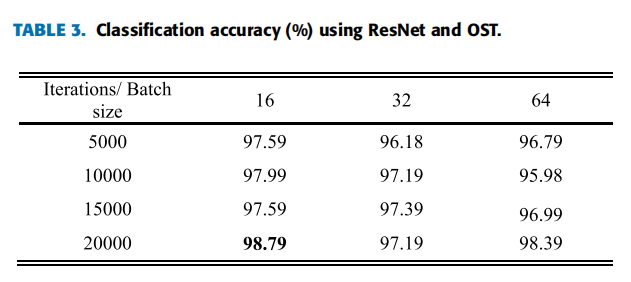 ) )特异性、敏感度: 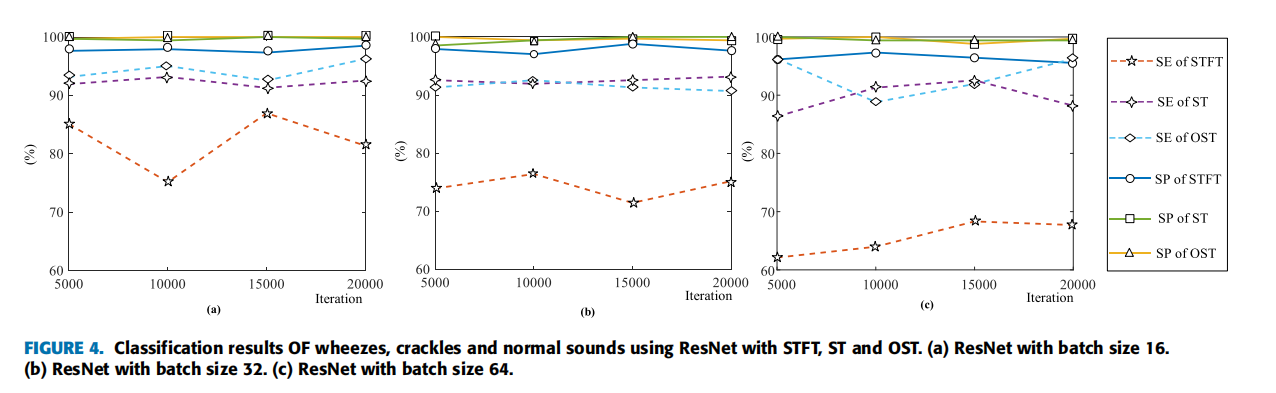 |
| (2)与其他研究对比 | 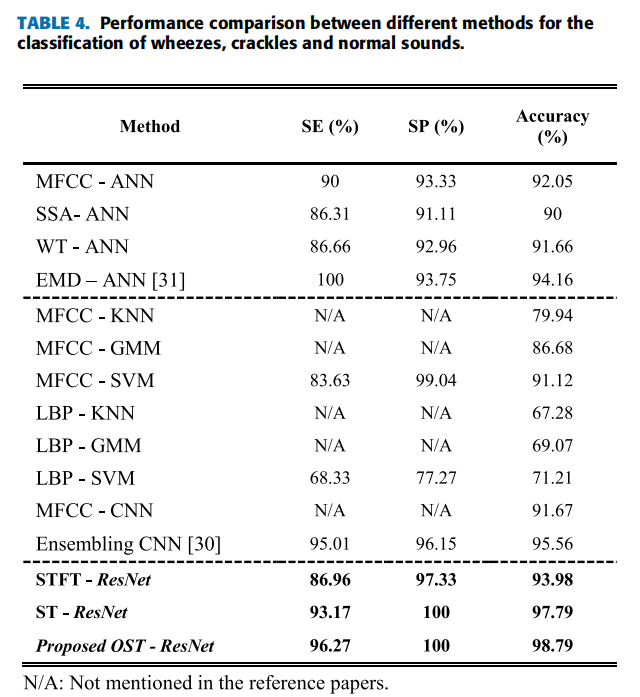 |
| 不同研究所使用的数据集不同! |
| 结论 | 说明 |
|---|---|
| 本文提出的优化的S变换特征提取方法以及ResNet变体实现了98.79%准确率,96.27%和100%的敏感度和特异性。 |
| 问题 | 说明 |
|---|---|
| (1)数据集问题 | 现有拿到的数据以及另外两篇使用该数据集的论文以及数据集原本的论文,都是920个音频文件,数据不对,本文的数据更少 |
| (2)模型详细结构不明 | 这里只能假设本文模型只是结构不同,具体参数相同 |
| (3)评价指标问题 | 本文是三分类问题,而特异性与敏感度只给出了类似于二分类的指标,即两类异常音作为正类,正常音作为负类 |
| (4)不同研究对比 | 不同研究指标对比中,三者所使用的数据集不同,这里直接比较似乎没有可比性。 |
| (5)特征提取细节 | ST OST不懂,但是对于STFT来说具体参数也没有给出,后续打算进行STFT以及其模型相应尝试 |