
MYSQL
语法
使用MYSQL
1 | SHOW DATABASES; //显示有哪些数据库 |
检索数据
1 | SELECT prod_name FROM products; //检索一列 |
排序检索数据
1 | //按单列排序 |
过滤数据

1 | SELECT prod_name, prod_price From products WHERE prod_price = 2.50; |
数据过滤
1 | //AND |
通配符过滤
1 | //LIKE操作符 |
正则表达式
包含表达式的内容即可,例如prod_name REGEXP '1000'可以匹配出‘jet 1000’,’jets 1000’等
1 | //基本字符匹配 |
1 | //匹配单个字符 |
1 | //匹配几个字符之一, [xxx] |
1 | //匹配特殊字符.,-,[],\等 |
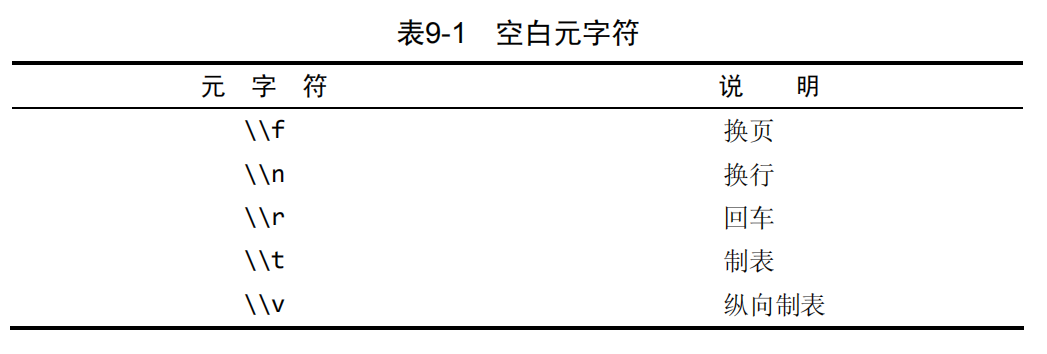


1 | //匹配包含‘(1 stick)’、'TNT (2 sticks)'这种的字符串 |
定位符
目前为止的所有例子都是匹配一个串中任意位置的文本。为了匹配特定位置的文本,需要定位符!
1 | //从文本开始匹配以小数点或数字开头的产品 |
简单的正则表达式测试
可以再不适用数据库表的情况下用SELECT来测试正则表达式。REGEXP检查总是返回0或1,表示不匹配或匹配。
1 | SELECT 'hello' REGEXP '[0-9]'; //返回0,因为“hello”中没有数字 |
计算字段
拼接(concatenate)
1 | SELECT Concat(vend_name, ' (', vend_country, ‘)’) # 拼接成"name(country)"格式 |
LTrim()/RTrim()
1 | SELECT Concat(LTrim(vend_name), ' (', RTrim(vend_country), ')') # RTrim()函数去掉值右边的所有空格,LTrim()函数去掉值左边的所有空格 |
使用别名
1 | SELECT Concat(LTrim(vend_name), ' (', RTrim(vend_country), ')') AS vend_title # 将该新计算列的名字 |
执行算数计算
1 | SELECT prod_id, quantity, item_price |

数据处理函数
函数没有SQL的可移植性强:即不同的DBMS的实现都支持其他实现不支持的函数,而且有时差异还很大。
文本处理函数
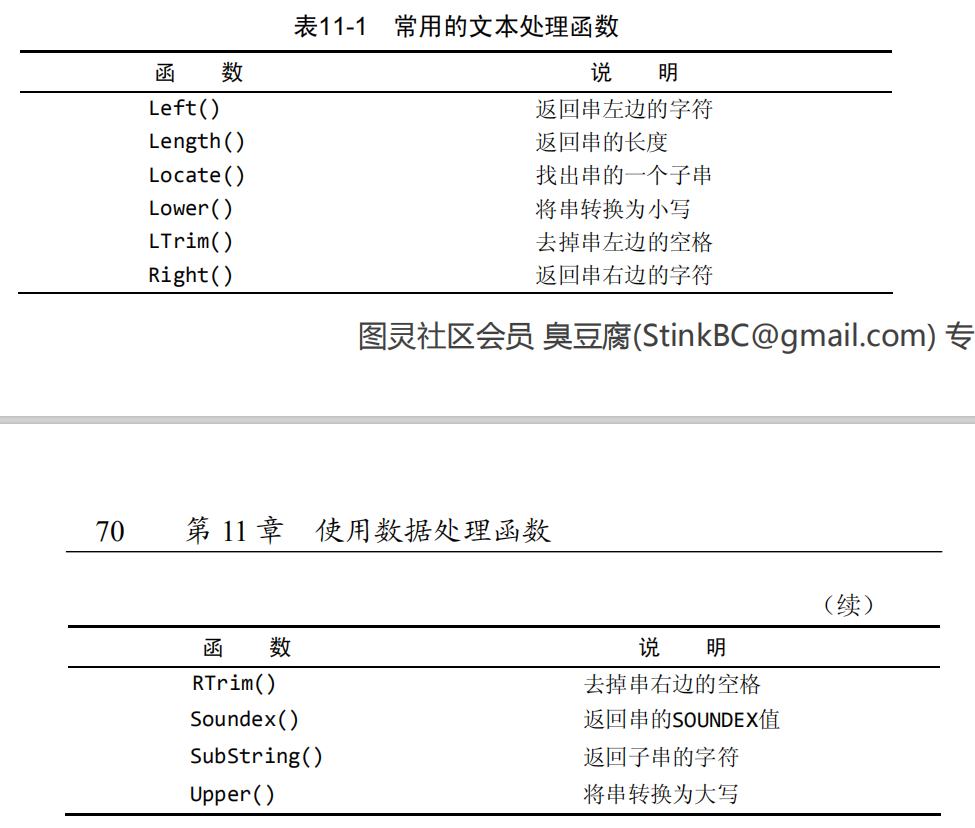
1 | SELECT vend_name, Upper(vend_name) AS vend_name_upcase # Upper()将文本转成大写 |
SOUNDEX()是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX()考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。
1 | SELECT cust_name, cust_contact |
日期和时间处理函数
日期和时间采用相应的数据类型和特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。一般,应用程序不使用用来存储日期和时间的格式,因此日期和时间函数总是被用来读取、统计和处理这些值。
首先注意MySQL使用的日期格式:yyyy-mm-dd
1 | SELECT cust_id, order_num |
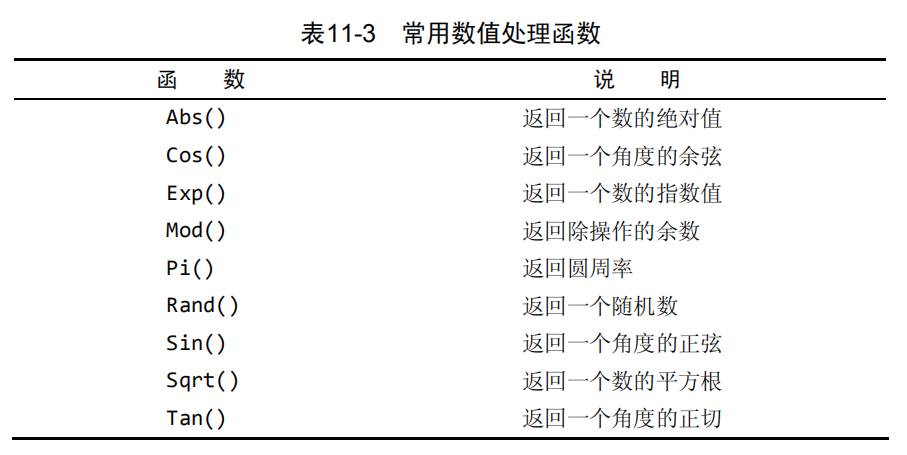
数值处理函数
汇总数据
聚集函数
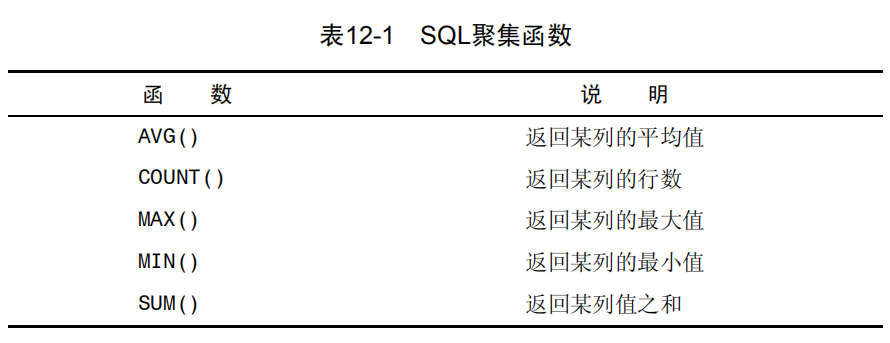
AVG()函数
1 | SELECT AVG(prod_price) AS avg_price # 计算prod_price列的均值 |
COUNT()函数
1 | SELECT COUNT(*) AS num_cust # 计算所有行数 |
MAX()函数
1 | SELECT MAX(prod_price) AS max_price |
MIN()函数
1 | SELECT MIN(prod_price) AS min_price |
SUM()函数
1 | SELECT SUM(quantity) AS items_ordered # 统计订单号为20005的quantity总和 |
聚集不同值
(1)对所有的行执行计算,指定ALL参数或不给参数(因为ALL是默认行为);
(2)只包含不同的值,指定DISTINCT参数。
1 | SELECT AVG(DISTINCT prod_price) AS avg_price # 统计产品价格平均值,只考虑不同价格 |
组合聚集函数
1 | SELECT COUNT(*) AS num_items, |
分组数据
数据分组
1 | SELECT COUNT(*) AS num_prods # 计算vend_id为1003的数量 |
创建分组
GROUP BY的一些规定:
(1)GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制;
(2)如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。即,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据);
(3)GROUP BY子句列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名;
(4)除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出;
(5)如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组;
(6)GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
1 | SELECT vend_id, COUNT(*) AS num_prods # GROUP BY对vend_id分组,然后COUNT计算每个分组内行的数量 |
过滤分组
1 | SELECT cust_id, COUNT(*) AS orders |
分组和排序
1 | SELECT order_num, SUM(quantity*item_price) AS ordertotal |
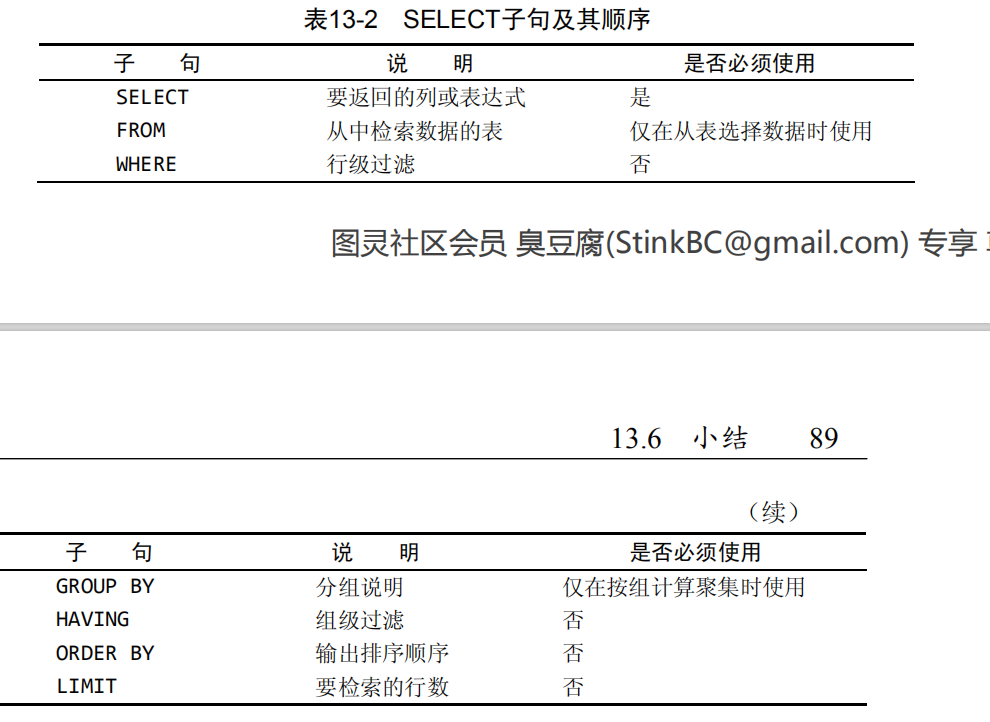
SELECT子句顺序
子查询
利用子查询进行过滤
1 | SELECT order_num |
作为计算字段使用子查询
1 | SELECT cust_name, |
联结表
创建联结
1 | # 等值联结 |
内部联结
1 | # 内部联结,等同上一个例子 |
联结多个表
1 | SELECT prod_name, vend_name, prod_price, quantity |
创建高级联结
使用表别名
1 | SELECT Concat(RTrim(vend_name), ' (', RTrim(vend_country), ')') AS vend_title |
使用不同类型的联结
自联结
1 | # 子查询 |
自然联结
内部联结在联结时会产生重复的列。
自然联结,只能选择哪些唯一的列。
1 | # 通配符只对第一个表使用。所有其他列明确列出,所以没有重复的列被检索出来 |
外部联结
1 | # 只能检索出有订单的客户 |
使用带聚集函数的联结
1 | # 检索所有客户及每个客户所下的订单数 |
组合查询
概念
多数SQL查询只包含从一个或多个表中返回数据的单条SELECT语句。MySQL也允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并或负荷查询:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据。
创建组合查询
使用UNION
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分割(因此,如果组合4条SELECT语句,将要使用3个UNION关键字);
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出);
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT vend_id, prod_id, prod_price
FROM produtcs
WHERE prod_price <= 5;
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002);
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002);包含或取消重复的行
UNION从查询结果中自动去除重复的行,这是默认行为,但是如果需要,可以改变它。事实上,如果想返回所有匹配行,可使用UNION ALL而不是UNION。1
2
3
4
5
6
7SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION ALL
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002);对组合查询结果排序
1
2
3
4
5
6
7
8SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002)
ORDER BY vend_id, prod_price; # UNION组合查询时,只能使用一条ORDER BY子句,不存在对一部分排序,对另一部分另一种排序的方式全文本搜索
使用全文本搜索
为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。
在索引之后,SELECT可与Match()和Against()一起使用以实际执行搜索。
Match():指定被搜索的列,Against()指定要使用的搜索表达式;
启用全文本搜索支持
1 | CREATE TABLE productnotes |
1 | SELECT note_text |
使用查询扩展
1 | SELECT note_text |
布尔文本搜索

1 | SELECT note_text |
插入数据
插入完整的行
如果表的定义允许,则可以在INSERT操作中省略某些列。省略的列必须满足以下某个条件:
1.该列定义为允许NULL值(无值或空值);
2.在表定义中给出默认值。这表示如果不给出值,将使用默认值。
1 | INSERT INTO Customers |
插入多个行
1 | INSERT INTO customers(cust_name, |
插入检索出的数据
1 | INSERT INTO customers(cust_id, |
更新和删除数据
更新数据
1 | UPDATE customers |
删除数据
1 | DELETE FROM customers |
创建和操纵表
创建表
1 | CREATE TABLE customers( |
主键
1 | CREATE TABLE orderitems( |
AUTO_INCREATEMENT
- 覆盖AUTO_INCREMENT,如果一个列被指定为AUTO_INCREMENT,可以简单地在INSERT语句中指定一个值,只要它是唯一的(至今尚未使用过)即可,该值将被用来替代自动生成的值。
- 确定AUTO_INCREMENT值,在插入之前获得AUTO_INCREMENT列的值,用last_insert_id()函数获得这个值:SELECT 用last_insert_id()
指定默认值
1
2
3
4
5
6
7
8CREATE TABLE orderitems(
order_num int NOT NULL,
order_item int NOT NULL,
prod_id char(10) NOT NULL,
quantity int NOT NULL DEFAULT 1,
item_price decimal(8,2) NOT NULL,
PRIMARY KEY (order_num, order_item)
)ENGINE=InnoDB;引擎类型
- InnoDB是一个可靠的事务处理引擎,它不支持全文搜索;
- MEMORY在功能等同于MyISAM,但由于数据存储在内存(不是磁盘)中,速度很快(特别适合于临时表);
- MyISAM是一个性能极高的引擎,它支持全文本搜索,但不支持事务处理。
- 引擎可以混用,即不同表使用不同的引擎;
- 缺陷:外检不能跨引擎。混用引擎类型有一个大缺陷。外键(用于强制实施引用完整性)不能跨引擎,即使用一个引擎的表不能引用具有使用不同引擎的表的外键。
更新表
1
2
3
4
5ALTER TABLE vendors
ADD vend_phone CHAR(20); # 增加一列
ALTER TABLE vendors
DROP COLUMN vend_phone; # 删除一列定义外键
复杂的表结构更改一般需要手动删除过程,它涉及以下步骤:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15ALTER TABLE orderitems
ADD CONSTRAINT fk_orderitems_orders
FOREIGN KEY(order_num) REFERENCES orders(order_num);
ALTER TABLE orderitems
ADD CONSTRAINT fk_orderitems_products FOREIGN KEY (prod_id)
REFERENCES products(prod_id);
ALTER TABLE orders
ADD CONSTRAINT fk_orders_customers FOREIGN KEY (cust_id)
REFERENCES customers (cust_id);
ALTER TABLE products
ADD CONSTRAINT fk_products_vendors
FOREIGN KEY (vend_id) REFERENCES vendors(vend_id);
- 用新的列布局创建一个新表;
- 使用INSERT SELECT语句从旧表赋值数据到新表。如果有必要,可使用转换函数和计算字段;
- 检验包含所需数据的新表;
- 重命名旧表(如果确定,可以删除它)
- 用旧表原来的名字重命名新表
- 根据需要,重新创建触发器、存储过程、索引和外键。
删除表以及重命名表
1
2
3
4
5
6
7DROP TABLE customers2;
RENAME TABLE customers2 TO customers;
RENAME TABLE backup_customers TO customers,
backup_vendors TO vendors,
backup_products TO products;LeetCode题库
176. 第二高的薪水 (Easy)
Description
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
1 | +----+--------+ |
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
1 | +---------------------+ |
Program
1 | # Write your MySQL query statement below |
1 | # Write your MySQL query statement below |
177. 第N高的薪水 (Medium)
Description
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
1 | +----+--------+ |
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
1 | +------------------------+ |
Program
1 | CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT |