
| 题目 | 难度 | 算法 |
|---|---|---|
| 1. 两数之和 | Easy | Hash |
| 2. 两数相加 | Meidum | 数学 |
| 3. 无重复字符的最长子串 | Medium | 滑动窗口 |
| 4. 寻找两个正序数组的中位数 | Hard | 分治 |
| 5. 最长回文子串 | Medium | 动态规划 |
| 7. 整数反转 | Easy | 限制判断 |
| 8. 字符串转换整数 (atoi) | Medium | 数学 |
| 9. 回文数 | Easy | 字符串,Two points |
| 10. 正则表达式匹配 | Hard | 动态规划 |
| 11. 盛最多水的容器 | Medium | 双指针 |
| 12. 整数转罗马数字 | Medium | 数学 |
| 13. 罗马数字转整数 | Easy | 字符串,技巧 |
| 14. 最长公共前缀 | Easy | 字符串比较 |
| 17. 电话号码的字母组合 | Medium | 回溯 |
| 20. 有效的括号 | Easy | 栈 |
| 21. 合并两个有序链表 | Easy | 单链表 |
| 22. 括号生成 | Medium | 回溯 |
| 23. 合并K个排序链表 | Hard | 分治/非递归归并 |
| 24. 两两交换链表中的节点 | Medium | 链表 |
| 26. 删除排序数组中的重复项 | Easy | 数组去重 |
| 27. 移除元素 | Easy | 数组去重 |
| 28. 实现strStr | Easy | KMP算法 |
| 29. 两数相除 | Medium | 数学 |
| 31. 下一个排列 | Medium | 双指针 |
| 32. 最长有效括号 | Hard | 字符串/动态规划 |
| 33. 搜索旋转排序数组 | Medium | 二分查找 |
| 35. 搜索插入位置 | Easy | 二分查找 |
| 37. 解数独 | Hard | 解数独 |
| 38. 报数 | Easy | 字符串 |
| 39. 组合总和 | Medium | 回溯 |
| 40. 组合总和 II | Medium | 回溯 |
| 43. 字符串相乘 | Medium | 模拟 |
| 44. 通配符匹配 | Hard | 动态规划 |
| 46. 全排列 | Medium | 回溯 |
| 47. 全排列 II | Medium | 回溯 |
| 48. 旋转图像 | Medium | 数组 |
| 50. Pow(x, n) | Medium | 二分查找 |
| 51. N 皇后 | Hard | 回溯 |
| 52. N皇后 II | Hard | 回溯 |
| 53. 最大子序和 | Easy | 动态规划 |
| 54. 螺旋矩阵 | Medium | 数组 |
| 55. 跳跃游戏 | Medium | 贪心 |
| 56. 合并区间 | Medium | 排序 |
| 57. 插入区间 | Hard | 排序 |
| 58. 最后一个单词的长度 | Easy | 字符串 |
| 60. 第k个排列 | Medium | 回溯+剪枝 |
| 61. 旋转链表 | Medium | 链表 |
| 62. 不同路径 | Medium | 动态规划 |
| 63. 不同路径 II | Medium | 动态规划 |
| 64. 最小路径和 | Medium | 动态规划 |
| 65. 有效数字 | Hard | 确定有限状态自动机 |
| 66. 加一 | Easy | 加法进位 |
| 67. 二进制求和 | Easy | 加法进位 |
| 69. x 的平方根 | Easy | 二分法 |
| 70. 爬楼梯 | Easy | 动态规划 |
| 71. 简化路径 | Medium | 栈/字符串 |
| 74. 搜索二维矩阵 | Medium | 二分 |
| 75. 颜色分类 | Medium | 排序 |
| 77. 组合 | Medium | 回溯+剪枝 |
| 78. 子集 | Medium | 位运算 |
| 79. 单词搜索 | Medium | 回溯 |
| 81. 搜索旋转排序数组 II | Medium | 二分 |
| 82. 删除排序链表中的重复元素 II | Medium | 链表 |
| 83. 删除排序链表中的重复元素 | Easy | 单链表 |
| 86. 分隔链表 | Medium | 链表 |
| 88. 合并两个有序数组 | Easy | 数组合并 |
| 89. 格雷编码 | Medium | 回溯 |
| 90. 子集 II | Medium | 回溯 |
| 91. 解码方法 | Medium | 动态规划 |
| 92. 反转链表 II | Medium | 链表 |
| 93. 复原IP地址 | Medium | 回溯 |
| 94. 二叉树的中序遍历 | Medium | 栈/树 |
| 95. 不同的二叉搜索树 II | Medium | 递归 |
| 96. 不同的二叉搜索树 | Medium | 动态规划 |
| 97. 交错字符串 | Hard | 动态规划 |
| 98. 验证二叉搜索树 | Medium | 二叉搜索树 |
| 99. 恢复二叉搜索树 | Hard | 树 |
| 100. 相同的树 | Easy | 二叉树 |
| 101. 对称二叉树 | Easy | 二叉树 |
| 102. 二叉树的层次遍历 | Medium | 广搜 |
| 103. 二叉树的锯齿形层次遍历 | Medium | 广搜 |
| 104. 二叉树的最大深度 | Easy | 二叉树 |
| 105. 从前序与中序遍历序列构造二叉树 | Medium | 二叉树 |
| 106. 从中序与后序遍历序列构造二叉树 | Medium | 二叉树 |
| 107. 二叉树的层次遍历 II | Easy | 二叉树 |
| 108. 将有序数组转换为二叉搜索 | Easy | 二叉树 |
| 109. 有序链表转换二叉搜索树 | Medium | 平衡二叉树 |
| 110. 平衡二叉树 | Easy | 二叉树 |
| 111. 二叉树的最小深度 | Easy | 二叉树 |
| 112. 路径总和 | Easy | 二叉树 |
| 113. 路径总和 II | Medium | 二叉树 |
| 114. 二叉树展开为链表 | Medium | 二叉树遍历 |
| 116. 填充每个节点的下一个右侧节点指针 | Medium | 层次遍历 |
| 117. 填充每个节点的下一个右侧节点指针 II | Medium | 层次遍历 |
| 118. 杨辉三角 | Easy | 简单模拟 |
| 119. 杨辉三角 II | Easy | 动态规划 |
| 120. 三角形最小路径和 | Medium | 动态规划 |
| 121. 买卖股票的最佳时机 | Easy | 动态规划 |
| 122. 买卖股票的最佳时机 II | Easy | 动态规划 |
| 123. 买卖股票的最佳时机 III | Hard | 动态规划 |
| 125. 验证回文串 | Easy | 字符串 |
| 126. 单词接龙 II | Hard | 双向广搜 |
| 127. 单词接龙 | Medium | 双向广搜 |
| 129. 求根到叶子节点数字之和 | Medium | 二叉树遍历 |
| 130. 被围绕的区域 | Medium | 并查集 |
| 131. 分割回文串 | Medium | 回溯 |
| 132. 分割回文串 II | Hard | 动规 |
| 133. 克隆图 | Medium | BFS+Map |
| 134. 加油站 | Medium | 贪心 |
| 135. 分发糖果 | Hard | 贪心 |
| 136. 只出现一次的数字 | Easy | 逻辑 |
| 139. 单词拆分 | Medium | 动态规划 |
| 140. 单词拆分 II | Hard | DP+回溯 |
| 141. 环形链表 | Easy | 单链表,快慢指针 |
| 142. 环形链表 II | Medium | 链表 |
| 143. 重排链表 | Medium | 链表 |
| 145. 二叉树的后序遍历 | Hard | 树/栈 |
| 146. LRU缓存机制 | Medium | 设计 |
| 147. 对链表进行插入排序 | Medium | 排序 |
| 148. 排序链表 | Medium | 排序 |
| 150. 逆波兰表达式求值 | Medium | 栈/字符串 |
| 152. 乘积最大子序列 | Medium | 动态规划 |
| 153. 寻找旋转排序数组中的最小值 | Medium | 二分 |
| 155. 最小栈 | Easy | 栈 |
| 160. 相交链表 | Easy | 双指针 |
| 162. 寻找峰值 | Medium | 二分查找 |
| 166. 分数到小数 | Medium | 数学/模拟 |
| 167. 两数之和 II - 输入有序数组 | Easy | Hash |
| 168. Excel表列名称 | Easy | 字符串hash |
| 169. 多数元素 | Easy | 逻辑 |
| 170. 两数之和 III - 数据结构设计 | Easy | 设计 |
| 171. Excel表列序号 | Easy | 字符串hash |
| 173. 二叉搜索树迭代器 | Medium | 设计 |
| 174. 地下城游戏 | Hard | 动态规划 |
| 179. 最大数 | Medium | 排序 |
| 187. 重复的DNA序列 | Medium | 位运算 |
| 188. 买卖股票的最佳时机 IV | Hard | 动态规划 |
| 189. 旋转数组 | Easy | 数组移动 |
| 190. 颠倒二进制位 | Easy | 二进制 |
| 191. 位1的个数 | Easy | 二进制 |
| 198. 打家劫舍 | Easy | 动态规划 |
| 199. 二叉树的右视图 | Medium | DFS |
| 200. 岛屿数量 | Medium | 并查集 |
| 201. 数字范围按位与 | Medium | 位运算 |
| 202. 快乐数 | Easy | 快慢指针 |
| 203. 移除链表元素 | Easy | 单链表 |
| 204. 计数质数 | Easy | 素数Euler |
| 205. 同构字符串 | Easy | Hash |
| 206. 反转链表 | Easy | 单链表 |
| 207. 课程表 | Medium | 拓扑排序 |
| 208. 实现 Trie (前缀树) | Medium | 设计 |
| 209. 长度最小的子数组 | Medium | 滑动窗口 |
| 210. 课程表 II | Medium | 拓扑排序 |
| 211. 添加与搜索单词 - 数据结构设计 | Medium | 设计 |
| 213. 打家劫舍 II | Medium | 动态规划 |
| 214. 最短回文串 | Hard | 字符串/KMP |
| 215. 数组中的第K个最大元素 | Medium | 分治 |
| 216. 组合总和 III | Medium | 回溯 |
| 217. 存在重复元素 | Easy | Hash |
| 218. 天际线问题 | Hard | 分治 |
| 219. 存在重复元素 II | Easy | Hash |
| 220. 存在重复元素 III | Medium | 排序 |
| 221. 最大正方形 | Medium | 动态规划 |
| 222. 完全二叉树的节点个数 | Medium | 树 |
| 223. 矩形面积 | Medium | 数学 |
| 225. 用队列实现栈 | Easy | 队列 |
| 226. 翻转二叉树 | Easy | 二叉树 |
| 230. 二叉搜索树中第K小的元素 | Medium | 二分查找 |
| 231. 2的幂 | Easy | 快速幂 |
| 232. 用栈实现队列 | Easy | 设计 |
| 234. 回文链表 | Easy | 链表 |
| 235. 二叉搜索树的最近公共祖先 | Easy | 树 |
| 236. 二叉树的最近公共祖先 | Medium | 树 |
| 237. 删除链表中的节点 | Easy | 链表 |
| 239. 滑动窗口最大值 | Hard | 滑动窗口 |
| 240. 搜索二维矩阵 II | Medium | 数学 |
| 241. 为运算表达式设计优先级 | Medium | 分治 |
| 242. 有效的字母异位词 | Easy | 排序 |
| 256. 粉刷房子 | Easy | 动态规划 |
| 257. 二叉树的所有路径 | Easy | 深搜 |
| 258. 各位相加 | Easy | 数学 |
| 260. 只出现一次的数字 III | Medium | 位运算 |
| 264. 丑数 II | Medium | 动态规划+三指针 |
| 268. 缺失数字 | Medium | 位运算 |
| 270. 最接近的二叉搜索树值 | Easy | 二分查找 |
| 274. H 指数 | Medium | 二分查找 |
| 275. H指数 II | Medium | 二分查找 |
| 276. 栅栏涂色 | Easy | 动态规划 |
| 278. 第一个错误的版本 | Easy | 二分查找 |
| 279. 完全平方数 | Medium | 动态规划 |
| 284. 顶端迭代器 | Medium | 设计 |
| 287. 寻找重复数 | Medium | 二分查找 |
| 292. Nim 游戏 | Easy | 极大极小化 |
| 303. 区域和检索 - 数组不可变 | Easy | 动态规划 |
| 304. 二维区域和检索 - 矩阵不可变 | Medium | 动态规划 |
| 306. 累加数 | Medium | DFS |
| 307. 区域和检索 - 数组可修改 | Medium | 树状数组 |
| 309. 最佳买卖股票时机含冷冻期 | Medium | 动态规划 |
| 310. 最小高度树 | Medium | 拓扑排序变体 |
| 312. 戳气球 | Hard | 动态规划 |
| 313. 超级丑数 | Medium | 数组、DP |
| 315. 计算右侧小于当前元素的个数 | Hard | 树状数组 |
| 316. 去除重复字母 | Medium | 单调栈 |
| 318. 最大单词长度乘积 | Medium | 位运算 |
| 321. 拼接最大数 | Hard | 单调栈 |
| 322. 零钱兑换 | Medium | 动态规划 |
| 324. 摆动排序 II | Medium | 排序 |
| 327. 区间和的个数 | Hard | 树状数组 |
| 328. 奇偶链表 | Medium | 链表 |
| 329. 矩阵中的最长递增路径 | Hard | 深搜/拓扑排序 |
| 331. 验证二叉树的前序序列化 | Medium | 栈/字符串 |
| 332. 重新安排行程 | Medium | 欧拉回路、深搜 |
| 337. 打家劫舍 III | Medium | 树形DP |
| 338. 比特位计数 | Medium | 位运算+动态规划 |
| 341. 扁平化嵌套列表迭代器 | Medium | 设计 |
| 342. 4的幂 | Easy | 位运算 |
| 343. 整数拆分 | Medium | 动态规划/数学 |
| 344. 反转字符串 | Easy | 双指针 |
| 347. 前 K 个高频元素 | Medium | 堆 |
| 349. 两个数组的交集 | Easy | 集合 |
| 350. 两个数组的交集 II | Easy | 排序/哈希表 |
| 354. 俄罗斯套娃信封问题 | Hard | 动规 |
| 355. 设计推特 | Medium | 设计 |
| 357. 计算各个位数不同的数字个数 | Medium | 动态规划 |
| 367. 有效的完全平方数 | Easy | 数学 |
| 368. 最大整除子集 | Medium | 动态规划 |
| 371. 两整数之和 | Easy | 位运算 |
| 372. 超级次方 | Medium | 数学 |
| 374. 猜数字大小 | Easy | 二分查找 |
| 375. 猜数字大小 II | Medium | 动态规划 |
| 376. 摆动序列 | Medium | 动态规划 |
| 377. 组合总和 Ⅳ | Medium | 动态规划 |
| 378. 有序矩阵中第K小的元素 | Medium | 二分查找 |
| 385. 迷你语法分析器 | Medium | 栈/字符串 |
| 389. 找不同 | Easy | 位运算 |
| 392. 判断子序列 | Medium | 动态规划 |
| 393. UTF-8 编码验证 | Medium | 位运算 |
| 394. 字符串解码 | Medium | 栈/字符串 |
| 397. 整数替换 | Medium | 位运算、动态规划 |
| 399. 除法求值 | Medium | 并查集 |
| 400. 第N个数字 | Medium | 数学 |
| 401. 二进制手表 | Easy | 位运算 |
| 402. 移掉K位数字 | Medium | 贪心 |
| 403. 青蛙过河 | Hard | 记忆化搜索/动规 |
| 404. 左叶子之和 | Easy | 树 |
| 405. 数字转换为十六进制数 | Easy | 位运算 |
| 406. 根据身高重建队列 | Medium | 贪心 |
| 410. 分割数组的最大值 | Hard | 动态规划 |
| 415. 字符串相加 | Easy | 字符串/模拟 |
| 416. 分割等和子集 | Medium | 动态规划 |
| 417. 太平洋大西洋水流问题 | Medium | 广搜 |
| 421. 数组中两个数的最大异或值 | Medium | 位运算/字典树 |
| 424. 替换后的最长重复字符 | Medium | 滑动窗口 |
| 429. N叉树的层序遍历 | Medium | 广搜 |
| 430. 扁平化多级双向链表 | Medium | 链表 |
| 435. 无重叠区间 | Medium | 贪心 |
| 436. 寻找右区间 | Medium | 二分查找 |
| 437. 路径总和 III | Medium | 树 |
| 441. 排列硬币 | Easy | 数学 |
| 445. 两数相加 II | Medium | 链表 |
| 446. 等差数列划分 II - 子序列 | Hard | 动态规划 |
| 452. 用最少数量的箭引爆气球 | Medium | 贪心 |
| 454. 四数相加 II | Medium | 二分查找 |
| 455. 分发饼干 | Easy | 贪心 |
| 456. 132模式 | Medium | 栈 |
| 459. 重复的子字符串 | Easy | 字符串 |
| 461. 汉明距离 | Easy | 位运算 |
| 464. 我能赢吗 | Medium | 动态规划 |
| 467. 环绕字符串中唯一的子字符串 | Medium | 动态规划 |
| 474. 一和零 | Medium | 动态规划 |
| 475. 供暖器 | Easy | 二分查找 |
| 476. 数字的补数 | Easy | 位运算 |
| 477. 汉明距离总和 | Medium | 位运算 |
| 478. 在圆内随机生成点 | Medium | 数学 |
| 486. 预测赢家 | Medium | 动态规划 |
| 491. 递增子序列 | Medium | 回溯+剪枝 |
| 493. 翻转对 | Hard | 分治+二分查找+树状数组 |
| 496. 下一个更大元素 I | Easy | 栈 |
| 497. 非重叠矩形中的随机点 | Medium | 二分查找/设计 |
| 501. 二叉搜索树中的众数 | Easy | 树/Morris中序遍历 |
| 503. 下一个更大元素 II | Medium | 栈 |
| 508. 出现次数最多的子树元素和 | Medium | 树 |
| 513. 找树左下角的值 | Medium | 广搜 |
| 514. 自由之路 | Hard | 动态规划 |
| 515. 在每个树行中找最大值 | Medium | 广搜 |
| 516. 最长回文子序列 | Medium | 动态规划 |
| 523. 连续的子数组和 | Medium | 动态规划 |
| 524. 通过删除字母匹配到字典里最长单词 | Medium | 排序 |
| 526. 优美的排列 | Medium | 回溯 |
| 528. 按权重随机选择 | Medium | 二分查找/随机数 |
| 529. 扫雷游戏 | Medium | 广搜 |
| 530. 二叉搜索树的最小绝对差 | Easy | 树 |
| 535. TinyURL 的加密与解密 | Medium | 数学 |
| 537. 复数乘法 | Medium | 数学 |
| 538. 把二叉搜索树转换为累加树 | Easy | 树 |
| 542. 01 矩阵 | Medium | 广搜 |
| 543. 二叉树的直径 | Easy | 树 |
| 546. 移除盒子 | Hard | 动态规划 |
| 547. 朋友圈 | Medium | 并查集 |
| 553. 最优除法 | Medium | 数学 |
| 557. 反转字符串中的单词 III | Easy | 字符串 |
| 559. N叉树的最大深度 | Easy | 广搜 |
| 563. 二叉树的坡度 | Easy | 树 |
| 567. 字符串的排列 | Medium | 滑动窗口 |
| 572. 另一个树的子树 | Easy | 树 |
| 576. 出界的路径数 | Medium | 动态规划 |
| 592. 分数加减运算 | Medium | 数学 |
| 593. 有效的正方形 | Medium | 数学 |
| 598. 范围求和 II | Easy | 数学/短板效应 |
| 617. 合并二叉树 | Easy | 树 |
| 621. 任务调度器 | Medium | 贪心 |
| 622. 设计循环队列 | Medium | 设计 |
| 632. 最小区间 | Hard | 堆 |
| 636. 函数的独占时间 | Medium | 栈 |
| 637. 二叉树的层平均值 | Easy | 树 |
| 638. 大礼包 | Medium | 动态规划 |
| 640. 求解方程 | Medium | 数学 |
| 641. 设计循环双端队列 | Medium | 设计 |
| 645. 错误的集合 | Easy | 数学 |
| 646. 最长数对链 | Medium | 动态规划 |
| 647. 回文子串 | Medium | 动态规划 |
| 648. 单词替换 | Medium | 字典树 |
| 649. Dota2 参议院 | Medium | 模拟+贪心 |
| 650. 只有两个键的键盘 | Medium | 深搜+剪枝/数学 |
| 652. 寻找重复的子树 | Medium | 序列化 |
| 655. 输出二叉树 | Medium | 树 |
| 657. 机器人能否返回原点 | Easy | 字符串 |
| 658. 找到 K 个最接近的元素 | Medium | 二分查找 |
| 659. 分割数组为连续子序列 | Medium | 贪心 |
| 662. 二叉树最大宽度 | Medium | 树 |
| 673. 最长递增子序列的个数 | Medium | 动态规划 |
| 676. 实现一个魔法字典 | Medium | 字典树 |
| 679. 24 点游戏 | Hard | 回溯 |
| 682. 棒球比赛 | Easy | 栈 |
| 684. 冗余连接 | Medium | 并查集 |
| 685. 冗余连接 II | Hard | 并查集 |
| 688. “马”在棋盘上的概率 | Medium | 动态规划 |
| 690. 员工的重要性 | Easy | 广搜 |
| 691. 贴纸拼词 | Hard | 状压DP+BFS |
| 693. 交替位二进制数 | Easy | 位运算 |
| 696. 计数二进制子串 | Easy | 字符串 |
| 698. 划分为k个相等的子集 | Medium | 动态规划 |
| 703. 数据流中的第K大元素 | Easy | 设计 |
| 704. 二分查找 | Easy | 二分查找 |
| 707. 设计链表 | Easy | 设计 |
| 712. 两个字符串的最小ASCII删除和 | Medium | 动态规划 |
| 714. 买卖股票的最佳时机含手续费 | Medium | 动态规划 |
| 718. 最长重复子数组 | Medium | 动态规划 |
| 720. 词典中最长的单词 | Easy | 字典树 |
| 721. 账户合并 | Medium | 并查集+Hash |
| 725. 分隔链表 | Medium | 链表 |
| 733. 图像渲染 | Easy | 深搜 |
| 735. 行星碰撞 | Medium | 栈 |
| 738. 单调递增的数字 | Medium | 贪心 |
| 739. 每日温度 | Medium | 栈 |
| 740. 删除与获得点数 | Medium | 动态规划 |
| 743. 网络延迟时间 | Medium | 最短路径 |
| 744. 寻找比目标字母大的最小字母 | Easy | 二分查找 |
| 746. 使用最小花费爬楼梯 | Easy | 动态规划 |
| 752. 打开转盘锁 | Medium | 广搜 |
| 756. 金字塔转换矩阵 | Medium | 位运算+深搜 |
| 762. 二进制表示中质数个计算置位 | Easy | 位运算 |
| 763. 划分字母区间 | Medium | 贪心 |
| 764. 最大加号标志 | Medium | 动态规划 |
| 767. 重构字符串 | Medium | 贪心+桶排序 |
| 775. 全局倒置与局部倒置 | Medium | 数学/树状数组 |
| 784. 字母大小写全排列 | Easy | 位运算 |
| 785. 判断二分图 | Medium | 广搜、并查集 |
| 787. K 站中转内最便宜的航班 | Medium | 动态规划 |
| 789. 逃脱阻碍者 | Medium | 数学 |
| 790. 多米诺和托米诺平铺 | Medium | 动态规划 |
| 797. 所有可能的路径 | Medium | 回溯 |
| 799. 香槟塔 | Medium | 动态规划 |
| 801. 使序列递增的最小交换次数 | Medium | 动态规划 |
| 808. 分汤 | Medium | 动态规划 |
| 813. 最大平均值和的分组 | Medium | 动态规划 |
| 820. 单词的压缩编码 | Medium | 后缀+字典树 |
| 826. 安排工作以达到最大收益 | Medium | 双指针/二分 |
| 834. 树中距离之和 | Hard | 树形DP |
| 837. 新21点 | Medium | 概率DP |
| 838. 推多米诺 | Medium | 动态规划 |
| 841. 钥匙和房间 | Medium | 深搜 |
| 842. 将数组拆分成斐波那契序列 | Medium | DFS |
| 843. 猜猜这个单词 | Hard | 极大极小化 |
| 844. 比较含退格的字符串 | Easy | 栈 |
| 845. 数组中的最长山脉 | Medium | 动态规划 |
| 851. 喧闹和富有 | Medium | 记忆化搜索/拓扑排序 |
| 852. 山脉数组的峰顶索引 | Easy | 二分查找 |
| 853. 车队 | Medium | 排序+单调栈 |
| 856. 括号的分数 | Medium | 栈 |
| 867. 转置矩阵 | Easy | 数组 |
| 860. 柠檬水找零 | Easy | 贪心 |
| 861. 翻转矩阵后的得分 | Medium | 贪心 |
| 863. 二叉树中所有距离为 K 的结点 | Medium | 坐标化 |
| 868. 二进制间距 | Easy | 数学 |
| 869. 重新排序得到 2 的幂 | Medium | 数学 |
| 870. 优势洗牌 | Medium | 贪心 |
| 873. 最长的斐波那契子序列的长度 | Medium | 动态规划 |
| 874. 模拟行走机器人 | Easy | 贪心 |
| 875. 爱吃香蕉的珂珂 | Medium | 二分查找 |
| 876. 链表的中间结点 | Easy | 链表 |
| 877. 石子游戏 | Medium | 动态规划/记忆化搜索/前缀和 |
| 880. 索引处的解码字符串 | Medium | 字符串 |
| 881. 救生艇 | Medium | 贪心 |
| 885. 螺旋矩阵 III | Medium | 数学/数组 |
| 887. 鸡蛋掉落 | Hard | 动规 |
| 892. 三维形体的表面积 | Easy | 数学 |
| 894. 所有可能的满二叉树 | Medium | 树/递归 |
| 898. 子数组按位或操作 | Medium | 位运算+unordered_set |
| 901. 股票价格跨度 | Medium | 栈 |
| 907. 子数组的最小值之和 | Medium | 栈 |
| 908. 最小差值 I | Easy | 数学 |
| 909. 蛇梯棋 | Medium | 广搜 |
| 910. 最小差值 II | Medium | 贪心 |
| 911. 在线选举 | Medium | 二分查找 |
| 913. 猫和老鼠 | Hard | 极大极小化 |
| 914. 卡牌分组 | Easy | 最大公约数 |
| 919. 完全二叉树插入器 | Medium | 树 |
| 921. 使括号有效的最少添加 | Medium | 贪心 |
| 922. 按奇偶排序数组 II | Easy | 排序 |
| 930. 和相同的二元子数组 | Medium | 前缀和 |
| 931. 下降路径最小和 | Medium | 动态规划 |
| 932. 漂亮数组 | Medium | 分治 |
| 933. 最近的请求次数 | Easy | 队列 |
| 934. 最短的桥 | Medium | 广搜 |
| 935. 骑士拨号器 | Medium | 动态规划 |
| 944. 删列造序 | Easy | 贪心 |
| 946. 验证栈序列 | Medium | 栈 |
| 947. 移除最多的同行或同列石头 | Medium | 并查集+Hash |
| 948. 令牌放置 | Medium | 贪心 |
| 955. 删列造序 II | Medium | 贪心 |
| 956. 最高的广告牌 | Hard | 动态规划 |
| 959. 由斜杠划分区域 | Medium | 并查集 |
| 967. 连续差相同的数字 | Medium | 动态规划 |
| 968. 监控二叉树 | Hard | 树 |
| 969. 煎饼排序 | Medium | 排序 |
| 970. 强整数 | Easy | 数学 |
| 973. 最接近原点的 K 个点 | Medium | 分治 |
| 976. 三角形的最大周长 | Easy | 数学 |
| 978. 最长湍流子数组 | Medium | 动态规划 |
| 979. 在二叉树中分配硬币 | Medium | 树 |
| 980. 不同路径 III | Hard | 回溯 |
| 981. 基于时间的键值存储 | Medium | 设计/二分 |
| 983. 最低票价 | Medium | 动态规划 |
| 984. 不含 AAA 或 BBB 的字符串 | Medium | 贪心 |
| 987. 二叉树的垂序遍历 | Medium | 坐标+排序 |
| 990. 等式方程的可满足性 | Medium | 并查集 |
| 991. 坏了的计算器 | Medium | 贪心 |
| 992. K 个不同整数的子数组 | Hard | 滑窗 |
| 993. 二叉树的堂兄弟节点 | Easy | 坐标化 |
| 994. 腐烂的橘子 | Medium | 广搜 |
| 996. 正方形数组的数目 | Hard | 回溯 |
| 1002. 查找常用字符 | Easy | 字符串/数组 |
| 1003. 检查替换后的词是否有效 | Medium | 栈 |
| 1004. 最大连续1的个数 III | Medium | 滑动窗口 |
| 1005. K 次取反后最大化的数组和 | Easy | 贪心 |
| 1006. 笨阶乘 | Medium | 数学/模拟 |
| 1008. 前序遍历构造二叉搜索树 | Medium | 树 |
| 1009. 十进制整数的反码 | Easy | 数学 |
| 1011. 在 D 天内送达包裹的能力 | Medium | 二分查找 |
| 1015. 可被 K 整除的最小整数 | Medium | 数学 |
| 1017. 负二进制转换 | Medium | 数学 |
| 1019. 链表中的下一个更大节点 | Medium | 单调栈 |
| 1021. 删除最外层的括号 | Easy | 字符串 |
| 1022. 从根到叶的二进制数之和 | Easy | 树 |
| 1023. 驼峰式匹配 | Easy | 字符串 |
| 1024. 视频拼接 | Medium | 动态规划 |
| 1025. 除数博弈 | Easy | 数学/动态规划 |
| 1027. 最长等差数列 | Medium | 动态规划 |
| 1029. 两地调度 | Easy | 贪心 |
| 1030. 距离顺序排列矩阵单元格 | Easy | 排序 |
| 1033. 移动石子直到连续 | Easy | 脑筋急转弯 |
| 1037. 有效的回旋镖 | Easy | 数学 |
| 1039. 多边形三角剖分的最低得分 | Medium | 动态规划 |
| 1040. 移动石子直到连续 II | Medium | 滑动窗口 |
| 1043. 分隔数组以得到最大和 | Medium | 动态规划 |
| 1046. 最后一块石头的重量 | Easy | 贪心 |
| 1047. 删除字符串中的所有相邻重复项 | Easy | 栈 |
| 1048. 最长字符串链 | Medium | 动态规划 |
| 1049. 最后一块石头的重量 II | Medium | 动态规划 |
| 1052. 爱生气的书店老板 | Medium | 滑动窗口 |
| 1053. 交换一次的先前排列 | Medium | 贪心 |
| 1064. 不动点 | Easy | 二分查找 |
| 1079. 活字印刷 | Medium | 回溯+剪枝 |
| 1081. 不同字符的最小子序列 | Medium | 单调栈 |
| 1090. 受标签影响的最大值 | Medium | 贪心 |
| 1091. 二进制矩阵中的最短路径 | Medium | 广搜 |
| 1093. 大样本统计 | Medium | 数学 |
| 1094. 拼车 | Medium | 贪心 |
| 1104. 二叉树寻路 | Medium | 树 |
| 1105. 填充书架 | Medium | 动态规划 |
| 1111. 有效括号的嵌套深度 | Medium | 贪心 |
| 1122. 数组的相对排序 | Easy | 排序 |
| 1124. 表现良好的最长时间段 | Medium | 栈 |
| 1129. 颜色交替的最短路径 | Medium | 广搜 |
| 1130. 叶值的最小代价生成树 | Medium | 动态规划 |
| 1131. 绝对值表达式的最大值 | Medium | 位运算+数学 |
| 1139. 最大的以 1 为边界的正方形 | Medium | 动态规划 |
| 1140. 石子游戏 II | Medium | 动态规划 |
| 1143. 最长公共子序列 | Medium | 动态规划 |
| 1150. 检查一个数是否在数组中占绝大多数 | Easy | 二分查找 |
| 1154. 一年中的第几天 | Easy | 数学 |
| 1155. 掷骰子的N种方法 | Medium | 动态规划 |
| 1171. 从链表中删去总和值为零的连续节点 | Medium | 链表 |
| 1175. 质数排列 | Easy | 数学 |
| 1186. 删除一次得到子数组最大和 | Medium | 动态规划 |
| 1190. 反转每对括号间的子串 | Medium | 栈 |
| 1191. K 次串联后最大子数组之和 | Medium | 动态规划 |
| 1201. 丑数 III | Medium | 数学+容斥原理+二分查找 |
| 1202. 交换字符串中的元素 | Medium | 并查集 |
| 1208. 尽可能使字符串相等 | Medium | 滑动窗口 |
| 1209. 删除字符串中的所有相邻重复项 II | Medium | 栈 |
| 1217. 玩筹码 | Medium | 贪心 |
| 1218. 最长定差子序列 | Medium | 动态规划变体 |
| 1219. 黄金矿工 | Medium | 回溯 |
| 1221. 分割平衡字符串 | Easy | 贪心 |
| 1223. 掷骰子模拟 | Medium | 动态规划 |
| 1227. 飞机座位分配概率 | Medium | 动态规划 |
| 1234. 替换子串得到平衡字符串 | Medium | 滑动窗口 |
| 1237. 找出给定方程的正整数解 | Easy | 数学 |
| 1239. 串联字符串的最大长度 | Medium | 位运算+暴力 |
| 1240. 铺瓷砖 | Hard | 动态规划 |
| 1247. 交换字符使得字符串相同 | Medium | 贪心 |
| 1249. 移除无效的括号 | Medium | 栈 |
| 1253. 重构 2 行二进制矩阵 | Medium | 贪心 |
| 1261. 在受污染的二叉树中查找元素 | Medium | 树 |
| 1262. 可被三整除的最大和 | Medium | 动态规划 |
| 1269. 停在原地的方案数 | Hard | 动规 |
| 1276. 不浪费原料的汉堡制作方案 | Medium | 贪心 |
| 1277. 统计全为 1 的正方形子矩阵 | Medium | 动态规划 |
| 1282. 用户分组 | Medium | 贪心 |
| 1283. 使结果不超过阈值的最小除数 | Medium | 二分查找 |
| 1286. 字母组合迭代器 | Medium | 设计 |
| 1290. 二进制链表转整数 | Easy | 位运算 |
| 1291. 顺次数 | Medium | 枚举 |
| 1292. 元素和小于等于阈值的正方形的最大边长 | Medium | 前缀和+二分 |
| 1296. 划分数组为连续数字的集合 | Medium | 贪心+Hash+模拟 |
| 1297. 子串的最大出现次数 | Medium | 位运算 |
| 1300. 转变数组后最接近目标值的数组和 | Medium | 二分 |
| 1305. 两棵二叉搜索树中的所有元素 | Medium | 排序 |
| 1306. 跳跃游戏 III | Medium | 广搜 |
| 1310. 子数组异或查询 | Medium | 位运算+前缀和 |
| 1311. 获取你好友已观看的视频 | Medium | 广搜 |
| 1314. 矩阵区域和 | Medium | 动态规划 |
| 1317. 将整数转换为两个无零整数的和 | Easy | 数学 |
| 1318. 或运算的最小翻转次数 | Medium | 位运算 |
| 1319. 连通网络的操作次数 | Medium | 并查集 |
| 1329. 将矩阵按对角线排序 | Medium | 排序 |
| 1337. 方阵中战斗力最弱的 K 行 | Easy | 排序 |
| 1338. 数组大小减半 | Medium | 贪心 |
| 1339. 分裂二叉树的最大乘积 | Medium | 动态规划/数学 |
| 1351. 统计有序矩阵中的负数 | Easy | 二分查找 |
| 1353. 最多可以参加的会议数目 | Medium | 贪心 |
| 1356. 根据数字二进制下 1 的数目排序 | Easy | 位运算 |
| 1362. 最接近的因数 | Medium | 数学 |
| 1366. 通过投票对团队排名 | Medium | 排序 |
| 1367. 二叉树中的列表 | Medium | 动态规划/链表/二叉树 |
| 1370. 上升下降字符串 | Easy | 字符串 |
| 1372. 二叉树中的最长交错路径 | Medium | 动态规划/二叉树/深搜 |
| 1381. 设计一个支持增量操作的栈 | Medium | 栈 |
| 1386. 安排电影院座位 | Medium | 贪心 |
| 1387. 将整数按权重排序 | Medium | 排序 |
| 1390. 四因数 | Medium | 数学 |
| 1391. 检查网格中是否存在有效路径 | Medium | 广搜 |
| 1400. 构造 K 个回文字符串 | Medium | 贪心 |
| 1403. 非递增顺序的最小子序列 | Easy | 贪心 |
| 1405. 最长快乐字符串 | Medium | 贪心 |
| 1410. HTML 实体解析器 | Medium | 字符串 |
| 1414. 和为 K 的最少斐波那契数字数目 | Medium | 贪心 |
| 1415. 长度为 n 的开心字符串中字典序第 k 小的字符串 | Medium | 回溯 |
| 1423. 可获得的最大点数 | Medium | 动态规划 |
| 1424. 对角线遍历 II | Medium | 排序 |
| 1433. 检查一个字符串是否可以打破另一个字符串 | Medium | 贪心 |
| 1438. 绝对差不超过限制的最长连续子数组 | Medium | 滑动窗口 |
| 1441. 用栈操作构建数组 | Easy | 栈 |
| 1447. 最简分数 | Medium | 数学 |
| 1452. 收藏清单 | Medium | 排序 |
| 1456. 定长子串中元音的最大数目 | Medium | 滑动窗口 |
| 1471. 数组中的 k 个最强值 | Medium | 排序 |
| 1473. 粉刷房子 III | Hard | 动规 |
| 1477. 找两个和为目标值且不重叠的子数组 | Medium | 动态规划 |
| 1481. 不同整数的最少数目 | Medium | 排序 |
| 1482. 制作 m 束花所需的最少天数 | Medium | 二分查找 |
| 1491. 去掉最低工资和最高工资后的工资平均值 | Easy | 排序 |
| 1498. 满足条件的子序列数目 | Medium | 滑动窗口 |
| 1502. 判断能否形成等差数列 | Easy | 排序 |
| 1504. 统计全 1 子矩形 | Medium | 动态规划 |
| 1508. 子数组和排序后的区间和 | Medium | 排序 |
| 1528. 重新排列字符串 | Easy | 排序 |
| 1530. 好叶子节点对的数量 | Medium | 树 |
| 1544. 整理字符串 | Easy | 栈 |
| 1561. 你可以获得的最大硬币数目 | Medium | 排序 |
| 1621. 大小为 K 的不重叠线段的数目 | Medium | 动态规划 |
| 1626. 无矛盾的最佳球队 | Medium | 动态规划 |
| 1631. 最小体力消耗路径 | Medium | 优先队列+DP |
| 1636. 按照频率将数组升序排序 | Easy | 排序 |
| 1637. 两点之间不包含任何点的最宽垂直面积 | Medium | 排序 |
| 1641. 统计字典序元音字符串的数目 | Medium | 动态规划 |
| 1658. 将 x 减到 0 的最小操作数 | Medium | 哈希表/滑动窗口 |
| 1664. 生成平衡数组的方案数 | Medium | 动态规划/前缀和 |
| 1674. 使数组互补的最少操作次数 | Medium | 差分数组 |
| 1705. 吃苹果的最大数目 | Medium | 优先队列 |
| 1706. 球会落何处 | Medium | 模拟 |
| 1707. 与数组中元素的最大异或值 | Hard | 字典树 |
| 1723. 完成所有工作的最短时间 | Hard | 动规 |
| 5471. 和为目标值的最大数目不重叠非空子数组数目 | Medium | 动态规划 |
| 5520. 拆分字符串使唯一子字符串的数目最大 | Medium | 回溯 |
| 5631. 跳跃游戏 VI | Medium | 动态规划/优先队列/单调队列 |
| 5642. 大餐计数 | Medium | 贪心 |
| 5643. 将数组分成三个子数组的方案数 | Medium | 前缀和+二分 |
| 5644. 得到子序列的最少操作次数 | Hard | 哈希+二分/LCS |
| 面试题 01.05. 一次编辑 | Medium | 字符串 |
| 面试题 02.01. 移除重复节点 | Easy | 链表 |
| 面试题 02.08. 环路检测 | Medium | 链表 |
| 面试题 03.01. 三合一 | Easy | 设计 |
| 面试题 03.02. 栈的最小值 | Easy | |
| 面试题 03.04. 化栈为队 | Easy | 栈 |
| 面试题 03.06. 动物收容所 | Easy | 设计 |
| 面试题 04.03. 特定深度节点链表 | Medium | 广搜+链表 |
| 面试题32 - I. 从上到下打印二叉树 II | Medium | 广搜 |
| 面试题32 - II. 从上到下打印二叉树 II | Easy | 广搜 |
| 面试题32 - III. 从上到下打印二叉树 III | Medium | 广搜 |
| 面试题14- I. 剪绳子 | Medium | 数学 |
| 面试题14- II. 剪绳子 II | Medium | 数学 |
| 面试题 08.01. 三步问题 | Easy | 动态规划 |
| 面试题 08.02. 迷路的机器人 | Medium | 动态规划 |
| 面试题 08.03. 魔术索引 | Easy | 二分查找 |
| 面试题 08.04. 幂集 | Medium | 回溯 |
| 面试题 08.07. 无重复字符串的排列组合 | Medium | 回溯 |
| 面试题 08.08. 有重复字符串的排列组合 | Medium | 回溯 |
| 面试题 08.09. 括号 | Medium | 回溯 |
| 面试题 08.11. 硬币 | Medium | 动态规划 |
| 面试题 08.12. 八皇后 | Hard | 回溯 |
| 面试题 08.14. 布尔运算 | Medium | 动态规划 |
| 面试题 10.03. 搜索旋转数组 | Medium | 二分查找 |
| 面试题 10.05. 稀疏数组搜索 | Easy | 二分查找 |
| 面试题 10.09. 排序矩阵查找 | Medium | 二分查找 |
| 面试题 16.05. 阶乘尾数 | Easy | 数学 |
| 面试题 16.06. 最小差 | Medium | 双指针 |
| 面试题 16.07. 最大数值 | Easy | 数学 |
| 面试题 16.11. 跳水板 | Medium | 数学 |
| 面试题 16.17. 连续数列 | Easy | 动态规划 |
| 面试题 16.19. 水域大小 | Medium | 广搜 |
| 面试题 16.25. LRU缓存 | Medium | 设计 |
| 面试题17. 打印从1到最大的n位数 | Easy | 数学 |
| 面试题 17.06. 2出现的次数 | Medium | 数学 |
| 面试题 17.07. 婴儿名字 | Medium | 并查集 |
| 面试题 17.08. 马戏团人塔 | Medium | 二分/动态规划 |
| 面试题 17.09. 第 k 个数 | Medium | 数学 |
| 面试题 17.10. 主要元素 | Easy | 分治/数组 |
| 面试题 17.11. 单词距离 | Medium | 哈希+双指针 |
| 面试题 17.13. 恢复空格 | Medium | 动态规划+Trie |
| 面试题 17.14. 最小K个数 | Medium | 分治 |
| 面试题 17.16. 按摩师 | Easy | 动态规划 |
| 面试题 17.17. 多次搜索 | Medium | KMP/AC自动机 |
| 面试题 17.18. 最短超串 | Medium | 滑动窗口 |
| 面试题 17.22. 单词转换 | Medium | 双向广搜 |
| 面试题 17.23. 最大黑方阵 | Medium | 动态规划 |
| 面试题20. 表示数值的字符串 | Medium | 数学/确定有限状态自动机 |
| 面试题42. 连续子数组的最大和 | Easy | 动规 |
| 面试题47. 礼物的最大价值 | Medium | 动态规划 |
| 面试题49. 丑数 | Medium | 丑数 |
| 面试题62. 圆圈中最后剩下的数字 | Easy | 数学+迭代 |
| 面试题67. 把字符串转换成整数 | Medium | 数学 |
| 剑指 Offer 09. 用两个栈实现队列 | Easy | 设计/队列/栈 |
| 剑指 Offer 11. 旋转数组的最小数字 | Easy | 二分查找 |
| 剑指 Offer 25. 合并两个排序的链表 | Easy | 分治 |
| 剑指 Offer 30. 包含min函数的栈 | Easy | 栈 |
| 剑指 Offer 36. 二叉搜索树与双向链表 | Medium | 分治 |
| 剑指 Offer 38. 字符串的排列 | Medium | 回溯+剪枝 |
| 剑指 Offer 39. 数组中出现次数超过一半的数字 | Easy | 位运算/分治 |
| 剑指 Offer 40. 最小的k个数 | Easy | 分治 |
| 剑指 Offer 48. 最长不含重复字符的子字符串 | Medium | 滑动窗口 |
| 剑指 Offer 52. 两个链表的第一个公共节点 | Easy | 链表 |
| 剑指 Offer 53 - I. 在排序数组中查找数字 I | Easy | 二分查找 |
| 剑指 Offer 53 - II. 0~n-1中缺失的数字 | Easy | 二分查找 |
| 剑指 Offer 59 - I. 滑动窗口的最大值 | Easy | 滑动窗口 |
| 剑指 Offer 59 - II. 队列的最大值 | Medium | 滑动窗口 |
| 剑指 Offer 63. 股票的最大利润 | Medium | 动态规划 |
| 剑指 Offer 68 - II. 二叉树的最近公共祖先 | Easy | 树 |
| LCP 13. 寻宝 | Hard | 动态规划 |
| LCP 17. 速算机器人 | Easy | 数学 |
| LCP 18. 早餐组合 | Easy | 二分 |
| LCP 19. 秋叶收藏集 | Medium | 动态规划 |
| LCP 22. 黑白方格画 | Easy | 暴力 |
技巧
992. K 个不同整数的子数组
Description
给定一个正整数数组 A,如果 A 的某个子数组中不同整数的个数恰好为 K,则称 A 的这个连续、不一定独立的子数组为好子数组。
(例如,[1,2,3,1,2] 中有 3 个不同的整数:1,2,以及 3。)
返回 A 中好子数组的数目。
Example
示例 1:
输入:A = [1,2,1,2,3], K = 2
输出:7
解释:恰好由 2 个不同整数组成的子数组:[1,2], [2,1], [1,2], [2,3], [1,2,1], [2,1,2], [1,2,1,2].
示例 2:
输入:A = [1,2,1,3,4], K = 3
输出:3
解释:恰好由 3 个不同整数组成的子数组:[1,2,1,3], [2,1,3], [1,3,4].
提示:
1 <= A.length <= 20000
1 <= A[i] <= A.length
1 <= K <= A.length
Program
滑窗
错误代码
样例一就有问题[1,2,1,2]中的{2,1,2}无法识别orz。
1 | class Solution { |
详见官方题解
K个不同整数的子数组个数=最多包含K种不同整数的子数组个数-最多包含K-1种不同整数的子数组个数,妙啊!
1 | class Solution { |
LCP
LCP 17. 速算机器人
Description
小扣在秋日市集发现了一款速算机器人。店家对机器人说出两个数字(记作 x 和 y),请小扣说出计算指令:
“A” 运算:使 x = 2 * x + y;
“B” 运算:使 y = 2 * y + x。
在本次游戏中,店家说出的数字为 x = 1 和 y = 0,小扣说出的计算指令记作仅由大写字母 A、B 组成的字符串 s,字符串中字符的顺序表示计算顺序,请返回最终 x 与 y 的和为多少。
Example
示例 1:
输入:s = “AB”
输出:4
解释:
经过一次 A 运算后,x = 2, y = 0。
再经过一次 B 运算,x = 2, y = 2。
最终 x 与 y 之和为 4。
提示:
0 <= s.length <= 10
s 由 ‘A’ 和 ‘B’ 组成
Program
1 | class Solution { |
LCP 18. 早餐组合
Description
小扣在秋日市集选择了一家早餐摊位,一维整型数组 staple 中记录了每种主食的价格,一维整型数组 drinks 中记录了每种饮料的价格。小扣的计划选择一份主食和一款饮料,且花费不超过 x 元。请返回小扣共有多少种购买方案。
注意:答案需要以 1e9 + 7 (1000000007) 为底取模,如:计算初始结果为:1000000008,请返回 1
Example
示例 1:
输入:staple = [10,20,5], drinks = [5,5,2], x = 15
输出:6
解释:小扣有 6 种购买方案,所选主食与所选饮料在数组中对应的下标分别是:
第 1 种方案:staple[0] + drinks[0] = 10 + 5 = 15;
第 2 种方案:staple[0] + drinks[1] = 10 + 5 = 15;
第 3 种方案:staple[0] + drinks[2] = 10 + 2 = 12;
第 4 种方案:staple[2] + drinks[0] = 5 + 5 = 10;
第 5 种方案:staple[2] + drinks[1] = 5 + 5 = 10;
第 6 种方案:staple[2] + drinks[2] = 5 + 2 = 7。
示例 2:
输入:staple = [2,1,1], drinks = [8,9,5,1], x = 9
输出:8
解释:小扣有 8 种购买方案,所选主食与所选饮料在数组中对应的下标分别是:
第 1 种方案:staple[0] + drinks[2] = 2 + 5 = 7;
第 2 种方案:staple[0] + drinks[3] = 2 + 1 = 3;
第 3 种方案:staple[1] + drinks[0] = 1 + 8 = 9;
第 4 种方案:staple[1] + drinks[2] = 1 + 5 = 6;
第 5 种方案:staple[1] + drinks[3] = 1 + 1 = 2;
第 6 种方案:staple[2] + drinks[0] = 1 + 8 = 9;
第 7 种方案:staple[2] + drinks[2] = 1 + 5 = 6;
第 8 种方案:staple[2] + drinks[3] = 1 + 1 = 2;
提示:
1 <= staple.length <= 10^5
1 <= drinks.length <= 10^5
1 <= staple[i],drinks[i] <= 10^5
1 <= x <= 210^5
*Program**
二分
1 | class Solution { |
LCP 19. 秋叶收藏集
Description
小扣出去秋游,途中收集了一些红叶和黄叶,他利用这些叶子初步整理了一份秋叶收藏集 leaves, 字符串 leaves 仅包含小写字符 r 和 y, 其中字符 r 表示一片红叶,字符 y 表示一片黄叶。
出于美观整齐的考虑,小扣想要将收藏集中树叶的排列调整成「红、黄、红」三部分。每部分树叶数量可以不相等,但均需大于等于 1。每次调整操作,小扣可以将一片红叶替换成黄叶或者将一片黄叶替换成红叶。请问小扣最少需要多少次调整操作才能将秋叶收藏集调整完毕。
Example
示例 1:
输入:leaves = “rrryyyrryyyrr”
输出:2
解释:调整两次,将中间的两片红叶替换成黄叶,得到 “rrryyyyyyyyrr”
示例 2:
输入:leaves = “ryr”
输出:0
解释:已符合要求,不需要额外操作
提示:
3 <= leaves.length <= 10^5
leaves 中只包含字符 ‘r’ 和字符 ‘y’
Program
动态规划
(1)DP[0][i]表示从头到尾全变红的最少次数;
(2)DP[1][i]表示从头变红,当前变黄(红黄)的最少次数;
(3)DP[2][i]表示之前是红黄,现在变成红黄红的最少次数;
时间复杂度:$O(n)$
1 | class Solution { |
LCP 22. 黑白方格画
Description
小扣注意到秋日市集上有一个创作黑白方格画的摊位。摊主给每个顾客提供一个固定在墙上的白色画板,画板不能转动。画板上有 n * n 的网格。绘画规则为,小扣可以选择任意多行以及任意多列的格子涂成黑色,所选行数、列数均可为 0。
小扣希望最终的成品上需要有 k 个黑色格子,请返回小扣共有多少种涂色方案。
注意:两个方案中任意一个相同位置的格子颜色不同,就视为不同的方案。
Example
示例 1:
输入:n = 2, k = 2
输出:4
解释:一共有四种不同的方案:
第一种方案:涂第一列;
第二种方案:涂第二列;
第三种方案:涂第一行;
第四种方案:涂第二行。
示例 2:
输入:n = 2, k = 1
输出:0
解释:不可行,因为第一次涂色至少会涂两个黑格。
示例 3:
输入:n = 2, k = 4
输出:1
解释:共有 2*2=4 个格子,仅有一种涂色方案。
限制:
1 <= n <= 6
0 <= k <= n * n
Program
暴力
取i行j列,所得黑格数为$i * n + j *(n - i)$,注意i,j从0开始,且$k=n * n$时答案为1!
1 | class Solution { |
单调队列
239. 滑动窗口最大值
Description
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
进阶:
你能在线性时间复杂度内解决此题吗?
Example
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
1 | 滑动窗口的位置 最大值 |
提示:
1 <= nums.length <= 10^5
-10^4 <= nums[i] <= 10^4
1 <= k <= nums.length
Program
滑动窗口
一个很自然的思路就是维护一个保有索引的优先队列,然而时间复杂度为$O(n\log{k})$
线性复杂度的做法:
维护一个双端队列window:
(1)变量的最前端(也就是 window.front())是此次遍历的最大值的下标
(2)当我们遇到新的数时,将新的数和双项队列的末尾(也就是window.back())比较,如果末尾比新数小,则把末尾扔掉,直到该队列的末尾比新数大或者队列为空的时候才停止。
(3)双项队列中的所有值都要在窗口范围内
特点1:队列头尾当前最大元素下标
特点2:队列降序排列,最大值、次大值…下标
例如
1 | [1,3,1,2,0,5] |
[[1,3,1],2,0,5],队列3,1
[1,[3,1,2],0,5],队列3,2
[1,3,[1,2,0],5],剔除3,新进0,队列2,0
[1,3,1,[2,0,5]],队列5
1 | class Solution { |
传统思路
超时
1 | class Solution { |
1438. 绝对差不超过限制的最长连续子数组
Description
给你一个整数数组 nums ,和一个表示限制的整数 limit,请你返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 limit 。
如果不存在满足条件的子数组,则返回 0 。
Example
示例 1:
输入:nums = [8,2,4,7], limit = 4
输出:2
解释:所有子数组如下:
[8] 最大绝对差 |8-8| = 0 <= 4.
[8,2] 最大绝对差 |8-2| = 6 > 4.
[8,2,4] 最大绝对差 |8-2| = 6 > 4.
[8,2,4,7] 最大绝对差 |8-2| = 6 > 4.
[2] 最大绝对差 |2-2| = 0 <= 4.
[2,4] 最大绝对差 |2-4| = 2 <= 4.
[2,4,7] 最大绝对差 |2-7| = 5 > 4.
[4] 最大绝对差 |4-4| = 0 <= 4.
[4,7] 最大绝对差 |4-7| = 3 <= 4.
[7] 最大绝对差 |7-7| = 0 <= 4.
因此,满足题意的最长子数组的长度为 2 。
示例 2:
输入:nums = [10,1,2,4,7,2], limit = 5
输出:4
解释:满足题意的最长子数组是 [2,4,7,2],其最大绝对差 |2-7| = 5 <= 5 。
示例 3:
输入:nums = [4,2,2,2,4,4,2,2], limit = 0
输出:3
提示:
1 <= nums.length <= 10^5
1 <= nums[i] <= 10^9
0 <= limit <= 10^9
Program
滑动窗口最大值变型题,所不同的是需要维护两个双端队列,分别保存窗口最大值和最小值(其实是窗口最值排序)
1 | class Solution { |
5631. 跳跃游戏 VI
Description
给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。
一开始你在下标 0 处。每一步,你最多可以往前跳 k 步,但你不能跳出数组的边界。也就是说,你可以从下标 i 跳到 [i + 1, min(n - 1, i + k)] 包含 两个端点的任意位置。
你的目标是到达数组最后一个位置(下标为 n - 1 ),你的 得分 为经过的所有数字之和。
请你返回你能得到的 最大得分 。
Example
示例 1:
输入:nums = [1,-1,-2,4,-7,3], k = 2
输出:7
解释:你可以选择子序列 [1,-1,4,3] (上面加粗的数字),和为 7 。
示例 2:
输入:nums = [10,-5,-2,4,0,3], k = 3
输出:17
解释:你可以选择子序列 [10,4,3] (上面加粗数字),和为 17 。
示例 3:
输入:nums = [1,-5,-20,4,-1,3,-6,-3], k = 2
输出:0
提示:
$1 <= nums.length, k <= 10^5$
$-10^4 <= nums[i] <= 10^4$
Program
设DP[i]=max(DP[j])+nums[i],其中i-k<=j<i,时间复杂度:$O(n^2)$
优化如下
优先队列
max(DP[j])通过优先队列查找,且窗口外的dp值全部抛出
时间复杂度:$O(n\log{n})$
1 | class Solution { |
单调队列
窗口内的dp值保持单调递减,因为对于i-k<=j1,j2<i来说,如果dp[j1]<dp[j2],那么j1就应当永久剔除,因为不影响后续结果;
时间复杂度:$O(n)$
1 | class Solution { |
剑指 Offer 59 - I. 滑动窗口的最大值
Description
给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
Example
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
1 | 滑动窗口的位置 最大值 |
提示:
你可以假设 k 总是有效的,在输入数组不为空的情况下,1 ≤ k ≤ 输入数组的大小。
Program
保持双端队列首位为最大值,队列降序排列!
一个窗口中,较小的数在前面可以剔除,因为后续窗口移动过程中,一定不会是它为窗口最大值。
1 | class Solution { |
剑指 Offer 59 - II. 队列的最大值
Description
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
Example
示例 1:
输入:
[“MaxQueue”,”push_back”,”push_back”,”max_value”,”pop_front”,”max_value”]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]
示例 2:
输入:
[“MaxQueue”,”pop_front”,”max_value”]
[[],[],[]]
输出: [null,-1,-1]
限制:
1 <= push_back,pop_front,max_value的总操作数 <= 10000
1 <= value <= 10^5
Program
双端队列保留队列最大值,思路与滑动窗口最大值相同。
1 | class MaxQueue { |
树状数组/差分数组
307. 区域和检索 - 数组可修改
Description
给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
update(i, val) 函数可以通过将下标为 i 的数值更新为 val,从而对数列进行修改。
Example
示例:
Given nums = [1, 3, 5]
sumRange(0, 2) -> 9
update(1, 2)
sumRange(0, 2) -> 8
说明:
数组仅可以在 update 函数下进行修改。
你可以假设 update 函数与 sumRange 函数的调用次数是均匀分布的。
Program
1 | class NumArray { |
327. 区间和的个数
Description
给定一个整数数组 nums,返回区间和在 [lower, upper] 之间的个数,包含 lower 和 upper。
区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
说明:
最直观的算法复杂度是 $O(n^2)$ ,请在此基础上优化你的算法。
Example
示例:
输入: nums = [-2,5,-1], lower = -2, upper = 2,
输出: 3
解释: 3个区间分别是: [0,0], [2,2], [0,2],它们表示的和分别为: -2, -1, 2。
Program
树状数组
树状数组与线段树基于类似的思想,不过树状数组支持的基本查询为求出 [0, \textit{val}][0,val] 之间的整数数量。为了查询区间 [\textit{preSum}[j]-\textit{upper}, \textit{preSum}[j]-\textit{lower}][preSum[j]−upper,preSum[j]−lower] 内的整数数量,需要执行两次查询,即分别查询 [0, \textit{preSum}[j]-\textit{upper}-1][0,preSum[j]−upper−1] 区间的整数数量 LL 和[0,\textit{preSum}[j]-\textit{lower}][0,preSum[j]−lower]
1 | class Solution { |
1674. 使数组互补的最少操作次数
Description
给你一个长度为 偶数 n 的整数数组 nums 和一个整数 limit 。每一次操作,你可以将 nums 中的任何整数替换为 1 到 limit 之间的另一个整数。
如果对于所有下标 i(下标从 0 开始),nums[i] + nums[n - 1 - i] 都等于同一个数,则数组 nums 是 互补的 。例如,数组 [1,2,3,4] 是互补的,因为对于所有下标 i ,nums[i] + nums[n - 1 - i] = 5 。
返回使数组 互补 的 最少 操作次数。
Example
示例 1:
输入:nums = [1,2,4,3], limit = 4
输出:1
解释:经过 1 次操作,你可以将数组 nums 变成 [1,2,2,3](加粗元素是变更的数字):
nums[0] + nums[3] = 1 + 3 = 4.
nums[1] + nums[2] = 2 + 2 = 4.
nums[2] + nums[1] = 2 + 2 = 4.
nums[3] + nums[0] = 3 + 1 = 4.
对于每个 i ,nums[i] + nums[n-1-i] = 4 ,所以 nums 是互补的。
示例 2:
输入:nums = [1,2,2,1], limit = 2
输出:2
解释:经过 2 次操作,你可以将数组 nums 变成 [2,2,2,2] 。你不能将任何数字变更为 3 ,因为 3 > limit 。
示例 3:
输入:nums = [1,2,1,2], limit = 2
输出:0
解释:nums 已经是互补的。
提示:
n == nums.length
$2 <= n <= 10^5$
$1 <= nums[i] <= limit <= 10^5$
n 是偶数。
Program
差分数组
假设 res[x] 表示的是,nums[i] + nums[n - 1 - i] 为 x 的时候,需要多少次操作。
我们只需要计算出所有的 x 对应的 res[x], 取最小值就好了。
根据题意,nums[i] + nums[n - 1 - i] 最小是 2,即将两个数都修改为 1;最大是 2 * limit,即将两个数都修改成 limit。
所以,res[x] 中 x 的取值范围是 [2, 2 * limit]。我们用一个 res[2 * limit + 1] 的数组就好。
关键是,如何求出每一个 res[x] 位置的值,即修改后互补的数字和为 x,需要多少操作?
为了叙述方便,假设 nums[i] 为 A;nums[n - 1 - i] 为 B。
显然有:
如果修改后两个数字的和是 A + B,我们使用的操作数是 0 (没有修改));
否则的话,如果修改后两个数字和在 [1 + min(A, B), limit + max(A, B)] 的范围,我们使用的操作数是 1 (只需要修改 A 或者 B 就好);
否则的话,如果修改后两个数字和在 [2, 2 * limit] 的范围,我们使用的操作数是 2(两个数字都要修改));
所以,我们的算法是遍历每一组 nums[i] 和 nums[n - 1 - i],然后:
先将 [2, 2 * limit] 的范围需要的操作数 + 2;
之后,将 [1 + min(A, B), limit + max(A, B)] 的范围需要的操作数 - 1(即 2 - 1 = 1,操作 1 次);
之后,将 [A + B] 位置的值再 -1(即 1 - 1 = 0,操作 0 次)。
可以看出,整个过程都是在做区间更新。最后,我们查询每一个位置的值,取最小值就好。
对于这个需求,我们当然可以使用线段树或者树状数组解决,但代码量稍大,且复杂度也是 O(nlogn) 的。
但是仔细观察,我们发现,我们只需要作区间更新,和单点查询。
对于这个需求,有一种非常常规的”数据结构“,叫差分数组,完全满足需求,并且编程极其简单,整体可以在 O(n) 的时间解决。
打上引号,是因为差分数组就是一个数组而已。
简单来说,差分数组 diff[i],存储的是 res[i] - res[i - 1];而差分数组 diff[0…i] 的和,就是 res[i] 的值。
大家可以用一个小数据试验一下,很好理解。
如果我们想给 [l, r] 的区间加上一个数字 a, 只需要 diff[l] += a,diff[r + 1] -= a。
这样做,diff[0…i] 的和,就是更新后 res[i] 的值。
1 | class Solution { |
前缀和
技巧:
(1)与和k相关,哈希表记录前缀和;找区间[i + 1, j]的和为k, 即preSum[j] - preSum[i] = k
(2)与倍数k相关,哈希表记录取模后的余数;找区间[i + 1, j]的和为k的倍数,即preSum[j] - preSum[i] = n * k
面试题 17.05. 字母与数字
Description
给定一个放有字符和数字的数组,找到最长的子数组,且包含的字符和数字的个数相同。
返回该子数组,若存在多个最长子数组,返回左端点下标值最小的子数组。若不存在这样的数组,返回一个空数组。
Example
示例 1:
输入: [“A”,”1”,”B”,”C”,”D”,”2”,”3”,”4”,”E”,”5”,”F”,”G”,”6”,”7”,”H”,”I”,”J”,”K”,”L”,”M”]
输出: [“A”,”1”,”B”,”C”,”D”,”2”,”3”,”4”,”E”,”5”,”F”,”G”,”6”,”7”]
示例 2:
输入: [“A”,”A”]
输出: []
提示:
array.length <= 100000
Program
digitCnt - charCnt = diff
如果哈希表中找到diff说明[m[diff] + 1, i]是一个结果
1 | class Solution { |
1590. 使数组和能被 P 整除
Description
给你一个正整数数组 nums,请你移除 最短 子数组(可以为 空),使得剩余元素的 和 能被 p 整除。 不允许 将整个数组都移除。
请你返回你需要移除的最短子数组的长度,如果无法满足题目要求,返回 -1 。
子数组 定义为原数组中连续的一组元素。
Example
示例 1:
输入:nums = [3,1,4,2], p = 6
输出:1
解释:nums 中元素和为 10,不能被 p 整除。我们可以移除子数组 [4] ,剩余元素的和为 6 。
示例 2:
输入:nums = [6,3,5,2], p = 9
输出:2
解释:我们无法移除任何一个元素使得和被 9 整除,最优方案是移除子数组 [5,2] ,剩余元素为 [6,3],和为 9 。
示例 3:
输入:nums = [1,2,3], p = 3
输出:0
解释:和恰好为 6 ,已经能被 3 整除了。所以我们不需要移除任何元素。
示例 4:
输入:nums = [1,2,3], p = 7
输出:-1
解释:没有任何方案使得移除子数组后剩余元素的和被 7 整除。
示例 5:
输入:nums = [1000000000,1000000000,1000000000], p = 3
输出:0
提示:
1 <= nums.length <= 105
1 <= nums[i] <= 109
1 <= p <= 109
Program
记录同一个余数最后出现的位置,M为整个数组对p取模的余数
前缀数组A的余数为x,前缀数组B(B>A)的余数为y=M+x,那么B-A的子数组为所求
1 | class Solution { |
930. 和相同的二元子数组
Description
在由若干 0 和 1 组成的数组 A 中,有多少个和为 S 的非空子数组。
Example
示例:
输入:A = [1,0,1,0,1], S = 2
输出:4
解释:
如下面黑体所示,有 4 个满足题目要求的子数组:
[1,0,1,0,1]
[1,0,1,0,1]
[1,0,1,0,1]
[1,0,1,0,1]
提示:
A.length <= 30000
0 <= S <= A.length
A[i] 为 0 或 1
Program
记录每个前缀和出现的次数,dp思想求解
1 | class Solution { |
1497. 检查数组对是否可以被 k 整除
Description
给你一个整数数组 arr 和一个整数 k ,其中数组长度是偶数,值为 n 。
现在需要把数组恰好分成 n / 2 对,以使每对数字的和都能够被 k 整除。
如果存在这样的分法,请返回 True ;否则,返回 False 。
Example
示例 1:
输入:arr = [1,2,3,4,5,10,6,7,8,9], k = 5
输出:true
解释:划分后的数字对为 (1,9),(2,8),(3,7),(4,6) 以及 (5,10) 。
示例 2:
输入:arr = [1,2,3,4,5,6], k = 7
输出:true
解释:划分后的数字对为 (1,6),(2,5) 以及 (3,4) 。
示例 3:
输入:arr = [1,2,3,4,5,6], k = 10
输出:false
解释:无法在将数组中的数字分为三对的同时满足每对数字和能够被 10 整除的条件。
示例 4:
输入:arr = [-10,10], k = 2
输出:true
示例 5:
输入:arr = [-1,1,-2,2,-3,3,-4,4], k = 3
输出:true
提示:
arr.length == n
1 <= n <= 10^5
n 为偶数
-10^9 <= arr[i] <= 10^9
1 <= k <= 10^5
Program
1 | class Solution { |
1010. 总持续时间可被 60 整除的歌曲
Description
在歌曲列表中,第 i 首歌曲的持续时间为 time[i] 秒。
返回其总持续时间(以秒为单位)可被 60 整除的歌曲对的数量。形式上,我们希望索引的数字 i 和 j 满足 i < j 且有 (time[i] + time[j]) % 60 == 0。
Example
示例 1:
输入:[30,20,150,100,40]
输出:3
解释:这三对的总持续时间可被 60 整数:
(time[0] = 30, time[2] = 150): 总持续时间 180
(time[1] = 20, time[3] = 100): 总持续时间 120
(time[1] = 20, time[4] = 40): 总持续时间 60
示例 2:
输入:[60,60,60]
输出:3
解释:所有三对的总持续时间都是 120,可以被 60 整数。
提示:
1 <= time.length <= 60000
1 <= time[i] <= 500
Program
同上一题,记录余数,然后统计。
1 | class Solution { |
523. 连续的子数组和
Description
给定一个包含 非负数 的数组和一个目标 整数 k ,编写一个函数来判断该数组是否含有连续的子数组,其大小至少为 2,且总和为 k 的倍数,即总和为 n * k ,其中 n 也是一个整数。
Example
示例 1:
输入:[23,2,4,6,7], k = 6
输出:True
解释:[2,4] 是一个大小为 2 的子数组,并且和为 6。
示例 2:
输入:[23,2,6,4,7], k = 6
输出:True
解释:[23,2,6,4,7]是大小为 5 的子数组,并且和为 42。
说明:
数组的长度不会超过 10,000 。
你可以认为所有数字总和在 32 位有符号整数范围内。
Program
哈希表记录每个位置前缀和模k的结果对应的下标;
如果两个下标对应的模k结果相同,即[0, i]与[0,j]的前缀和模k结果相同,那么[i + 1, j]的和一定为k的倍数!
时间复杂度:$O(n)$
空间复杂度:$O(min(n, k))$
1 | class Solution { |
560. 和为K的子数组
Description
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
Example
示例 1 :
输入:nums = [1,1,1], k = 2
输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。
说明 :
数组的长度为 [1, 20,000]。
数组中元素的范围是 [-1000, 1000] ,且整数 k 的范围是 [-1e7, 1e7]。
Program
哈希表记录前缀和出现的次数
preSum[j] - preSum[i] == k说明[i + 1, j]子数组的和为k!
m[preSum]记录同一个前缀和出现的次数;
时间复杂度:$O(n)$
空间复杂度:$O(n)$
1 | class Solution { |
字典树
648. 单词替换
Description
在英语中,我们有一个叫做 词根(root)的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典和一个句子。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
Example
示例 1:
输入:dictionary = [“cat”,”bat”,”rat”], sentence = “the cattle was rattled by the battery”
输出:”the cat was rat by the bat”
示例 2:
输入:dictionary = [“a”,”b”,”c”], sentence = “aadsfasf absbs bbab cadsfafs”
输出:”a a b c”
示例 3:
输入:dictionary = [“a”, “aa”, “aaa”, “aaaa”], sentence = “a aa a aaaa aaa aaa aaa aaaaaa bbb baba ababa”
输出:”a a a a a a a a bbb baba a”
示例 4:
输入:dictionary = [“catt”,”cat”,”bat”,”rat”], sentence = “the cattle was rattled by the battery”
输出:”the cat was rat by the bat”
示例 5:
输入:dictionary = [“ac”,”ab”], sentence = “it is abnormal that this solution is accepted”
输出:”it is ab that this solution is ac”
提示:
1 <= dictionary.length <= 1000
1 <= dictionary[i].length <= 100
dictionary[i] 仅由小写字母组成。
1 <= sentence.length <= 10^6
sentence 仅由小写字母和空格组成。
sentence 中单词的总量在范围 [1, 1000] 内。
sentence 中每个单词的长度在范围 [1, 1000] 内。
sentence 中单词之间由一个空格隔开。
sentence 没有前导或尾随空格。
Program
思路
(1)根据字典进行前缀字典树构造,注意判断词根结尾;
(2)对句子中每个单词进行前缀判断即可,详见代码;
时间复杂度:$O(m+n)$,$m、n$分别是字典和句子的字母总数
1 | class Solution { |
676. 实现一个魔法字典
Description
实现一个带有buildDict, 以及 search方法的魔法字典。
对于buildDict方法,你将被给定一串不重复的单词来构建一个字典。
对于search方法,你将被给定一个单词,并且判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于你构建的字典中。
Example
示例 1:
Input: buildDict([“hello”, “leetcode”]), Output: Null
Input: search(“hello”), Output: False
Input: search(“hhllo”), Output: True
Input: search(“hell”), Output: False
Input: search(“leetcoded”), Output: False
注意:
你可以假设所有输入都是小写字母 a-z。
为了便于竞赛,测试所用的数据量很小。你可以在竞赛结束后,考虑更高效的算法。
请记住重置MagicDictionary类中声明的类变量,因为静态/类变量会在多个测试用例中保留。 请参阅这里了解更多详情。
Program
错误思路:直接字典树递归
对于无需任何转换就能走通的搜索单词,将不能得到正确答案。
1 | class MagicDictionary { |
正确思路
对于搜索单词的每个字母进行递归深搜
1 | class MagicDictionary { |
720. 词典中最长的单词
Description
给出一个字符串数组words组成的一本英语词典。从中找出最长的一个单词,该单词是由words词典中其他单词逐步添加一个字母组成。若其中有多个可行的答案,则返回答案中字典序最小的单词。
若无答案,则返回空字符串。
Example
示例 1:
输入:
words = [“w”,”wo”,”wor”,”worl”, “world”]
输出:”world”
解释:
单词”world”可由”w”, “wo”, “wor”, 和 “worl”添加一个字母组成。
示例 2:
输入:
words = [“a”, “banana”, “app”, “appl”, “ap”, “apply”, “apple”]
输出:”apple”
解释:
“apply”和”apple”都能由词典中的单词组成。但是”apple”的字典序小于”apply”。
提示:
所有输入的字符串都只包含小写字母。
words数组长度范围为[1,1000]。
words[i]的长度范围为[1,30]。
Program
1 | class Solution { |
421. 数组中两个数的最大异或值
Description
给定一个非空数组,数组中元素为 a0, a1, a2, … , an-1,其中 0 ≤ ai < 231 。
找到 ai 和aj 最大的异或 (XOR) 运算结果,其中0 ≤ i, j < n 。
你能在O(n)的时间解决这个问题吗?
Example
示例:
输入: [3, 10, 5, 25, 2, 8]
输出: 28
解释: 最大的结果是 5 ^ 25 = 28.
Program
参考大佬们的题解。
异或性质
1 | class Solution { |
前缀字典树
(1)对于数组的每个元素x,进行字典树构造;
(1)对于数组的每个元素x的每个高位bit,找其互补位,如果bit为1,找0,如果不存在找1;
1 | class Solution { |
1707. 与数组中元素的最大异或值
Description
给你一个由非负整数组成的数组 nums 。另有一个查询数组 queries ,其中 queries[i] = [xi, mi] 。
第 i 个查询的答案是 xi 和任何 nums 数组中不超过 mi 的元素按位异或(XOR)得到的最大值。换句话说,答案是 max(nums[j] XOR xi) ,其中所有 j 均满足 nums[j] <= mi 。如果 nums 中的所有元素都大于 mi,最终答案就是 -1 。
返回一个整数数组 answer 作为查询的答案,其中 answer.length == queries.length 且 answer[i] 是第 i 个查询的答案。
Example
示例 1:
输入:nums = [0,1,2,3,4], queries = [[3,1],[1,3],[5,6]]
输出:[3,3,7]
解释:
1) 0 和 1 是仅有的两个不超过 1 的整数。0 XOR 3 = 3 而 1 XOR 3 = 2 。二者中的更大值是 3 。
2) 1 XOR 2 = 3.
3) 5 XOR 2 = 7.
示例 2:
输入:nums = [5,2,4,6,6,3], queries = [[12,4],[8,1],[6,3]]
输出:[15,-1,5]
提示:
1 <= nums.length, queries.length <= 10^5
queries[i].length == 2
0 <= nums[j], xi, mi <= 10^9
Program
思路
0-1字典树优化,取互补操作
1 | class Solution { |
并查集
684. 冗余连接
Description
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
Example
示例 1:
输入: [[1,2], [1,3], [2,3]]
输出: [2,3]
解释: 给定的无向图为:
1 | 1 |
示例 2:
输入: [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
解释: 给定的无向图为:
1 | 5 - 1 - 2 |
注意:
输入的二维数组大小在 3 到 1000。
二维数组中的整数在1到N之间,其中N是输入数组的大小。
Program
1 | class Solution { |
685. 冗余连接 II
Description
在本问题中,有根树指满足以下条件的有向图。该树只有一个根节点,所有其他节点都是该根节点的后继。每一个节点只有一个父节点,除了根节点没有父节点。
输入一个有向图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。 每一个边 的元素是一对 [u, v],用以表示有向图中连接顶点 u 和顶点 v 的边,其中 u 是 v 的一个父节点。
返回一条能删除的边,使得剩下的图是有N个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
Example
示例 1:
输入: [[1,2], [1,3], [2,3]]
输出: [2,3]
解释: 给定的有向图如下:
1
/
v v
2–>3
示例 2:
输入: [[1,2], [2,3], [3,4], [4,1], [1,5]]
输出: [4,1]
解释: 给定的有向图如下:
5 <- 1 -> 2
^ |
| v
4 <- 3
注意:
二维数组大小的在3到1000范围内。
二维数组中的每个整数在1到N之间,其中 N 是二维数组的大小。
Program
并查集
(1)有根树性质:
- 无有向环
- 无入度为2的节点,因为题目是有根树附加另一条边,这条边使得有根树不成立,所以入度最多为2
(2)首先统计入度,判断是否入度为2;
(3)如果入度为2,那么可以发现两条边(u1,v),(u2,v)使得v的入度为2,那么依次删掉这两条边,判断是否构成有根树即可;注意逆序遍历边
(4)如果没有入度为2,那么说明存在有向环,那么只要正序构建并查集,判断是否构成有向环的边即可,找到第一个构成环的边就是答案;
时间复杂度:$O(n)$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65class Solution {
public:
int n;
vector<int> father;
void init(){
father.resize(n+1, 0);
for(int i=0;i<=n;i++) father[i]=i;
}
int findFather(int x){
if(father[x]!=x){
father[x]=findFather(father[x]);
}
return father[x];
}
void unionSet(int x, int y){ //x为父节点,y为子节点
int fa=findFather(x);
int fb=findFather(y);
if(fa!=fb){
father[fb]=fa;
}
}
bool isSame(int u, int v){
int fa=findFather(u);
int fb=findFather(v);
return fa==fb;
}
//在有向图里找到删除的那条边,使其变成树
vector<int> getRemoveEdge(const vector<vector<int>>& edges){
init(); //初始化并查集
for(int i=0;i<n;i++){ //遍历所有边
if(isSame(edges[i][0], edges[i][1])){ //构成有向环
return edges[i];
}
unionSet(edges[i][0], edges[i][1]);
}
return {}; //无环
}
bool isTreeAfterRemoveEdge(const vector<vector<int>>& edges, int deletEdge){
init(); //初始化并查集
for(int i=0;i<n;i++){
if(i==deletEdge) continue;
if(isSame(edges[i][0], edges[i][1])) return false; //构成有向环
unionSet(edges[i][0], edges[i][1]);
}
return true;
}
vector<int> findRedundantDirectedConnection(vector<vector<int>>& edges) {
n=edges.size();
father.resize(n+1, 0);
vector<int> inDegree(n+1, 0);
for(int i=0;i<n;i++){
inDegree[edges[i][1]]++;
}
vector<int> vec;
for(int i=n-1;i>=0;i--){
if(inDegree[edges[i][1]]==2) vec.push_back(i);
}
//如果有入度为2的节点,那么一定是两条边中的一个
if(vec.size()>0){
if(isTreeAfterRemoveEdge(edges, vec[0])) return edges[vec[0]];
else return edges[vec[1]];
}
return getRemoveEdge(edges);
}
};队列
933. 最近的请求次数
Description
写一个 RecentCounter 类来计算最近的请求。
它只有一个方法:ping(int t),其中 t 代表以毫秒为单位的某个时间。
返回从 3000 毫秒前到现在的 ping 数。
任何处于 [t - 3000, t] 时间范围之内的 ping 都将会被计算在内,包括当前(指 t 时刻)的 ping。
保证每次对 ping 的调用都使用比之前更大的 t 值。
Example
示例:
输入:inputs = [“RecentCounter”,”ping”,”ping”,”ping”,”ping”], inputs = [[],[1],[100],[3001],[3002]]
输出:[null,1,2,3,3]
提示:
每个测试用例最多调用 10000 次 ping。
每个测试用例会使用严格递增的 t 值来调用 ping。
每次调用 ping 都有 1 <= t <= 10^9。
Program
1 | class RecentCounter { |
状态压缩
691. 贴纸拼词
Description
我们给出了 N 种不同类型的贴纸。每个贴纸上都有一个小写的英文单词。
你希望从自己的贴纸集合中裁剪单个字母并重新排列它们,从而拼写出给定的目标字符串 target。
如果你愿意的话,你可以不止一次地使用每一张贴纸,而且每一张贴纸的数量都是无限的。
拼出目标 target 所需的最小贴纸数量是多少?如果任务不可能,则返回 -1。
Example
示例 1:
输入:
[“with”, “example”, “science”], “thehat”
输出:
3
解释:
我们可以使用 2 个 “with” 贴纸,和 1 个 “example” 贴纸。
把贴纸上的字母剪下来并重新排列后,就可以形成目标 “thehat“ 了。
此外,这是形成目标字符串所需的最小贴纸数量。
示例 2:
输入:
[“notice”, “possible”], “basicbasic”
输出:
-1
解释:
我们不能通过剪切给定贴纸的字母来形成目标“basicbasic”。
提示:
stickers 长度范围是 [1, 50]。
stickers 由小写英文单词组成(不带撇号)。
target 的长度在 [1, 15] 范围内,由小写字母组成。
在所有的测试案例中,所有的单词都是从 1000 个最常见的美国英语单词中随机选取的,目标是两个随机单词的串联。
时间限制可能比平时更具挑战性。预计 50 个贴纸的测试案例平均可在35ms内解决。
Program
BFS+状态压缩
(1)step[i]表示i(二进制1的位置表示与target的对应匹配)状态下的最少贴纸数量;
(2)BFS从0状态(无一个匹配)搜索,肯定是最短,即step[i]更新了一次,下次搜索到就不用更新了,之后的更新肯定不是最优;
(3)从长的单词开始搜索;
1 | class Solution { |
欧拉回路
332. 重新安排行程
Description
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 出发。
说明:
- 如果存在多种有效的行程,你可以按字符自然排序返回最小的行程组合。例如,行程 [“JFK”, “LGA”] 与 [“JFK”, “LGB”] 相比就更小,排序更靠前
- 所有的机场都用三个大写字母表示(机场代码)。
- 假定所有机票至少存在一种合理的行程。
Example
示例 1:
输入: [[“MUC”, “LHR”], [“JFK”, “MUC”], [“SFO”, “SJC”], [“LHR”, “SFO”]]
输出: [“JFK”, “MUC”, “LHR”, “SFO”, “SJC”]
示例 2:
输入: [[“JFK”,”SFO”],[“JFK”,”ATL”],[“SFO”,”ATL”],[“ATL”,”JFK”],[“ATL”,”SFO”]]
输出: [“JFK”,”ATL”,”JFK”,”SFO”,”ATL”,”SFO”]
解释: 另一种有效的行程是 [“JFK”,”SFO”,”ATL”,”JFK”,”ATL”,”SFO”]。但是它自然排序更大更靠后。
Program
1 | class Solution { |
排序
56. 合并区间
Description
给出一个区间的集合,请合并所有重叠的区间。
Example
示例 1:
输入: intervals = [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入: intervals = [[1,4],[4,5]]
输出: [[1,5]]
解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
注意:输入类型已于2019年4月15日更改。 请重置默认代码定义以获取新方法签名。
提示:
intervals[i][0] <= intervals[i][1]
program
1 | class Solution { |
57. 插入区间
Description
给出一个无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
Example
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5]
输出:[[1,5],[6,9]]
示例 2:
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
注意:输入类型已在 2019 年 4 月 15 日更改。请重置为默认代码定义以获取新的方法签名。
Program
1 | class Solution { |
75. 颜色分类
Description
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
注意:
不能使用代码库中的排序函数来解决这道题。
Example
示例:
输入: [2,0,2,1,1,0]
输出: [0,0,1,1,2,2]
进阶:
一个直观的解决方案是使用计数排序的两趟扫描算法。
首先,迭代计算出0、1 和 2 元素的个数,然后按照0、1、2的排序,重写当前数组。
你能想出一个仅使用常数空间的一趟扫描算法吗?
Program
1 | class Solution { |
147. 对链表进行插入排序
Description
对链表进行插入排序。
插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。
每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。
插入排序算法:
插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
重复直到所有输入数据插入完为止。
Example
示例 1:
输入: 4->2->1->3
输出: 1->2->3->4
示例 2:
输入: -1->5->3->4->0
输出: -1->0->3->4->5
Progam
- 维护一个标兵节点,便于访问链表头,因为在插入排序的过程中,表头可能变化;
- 维护一个已排序链表尾节点,模拟数组插入排序,这样方便对链表待排序节点前后位置进行连接!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if(head==NULL||head->next==NULL) return head;
ListNode* tHead=new ListNode(-1);
tHead->next=head;
ListNode* tail=head;// 已排序的最后一个节点
ListNode* now=head->next; //当前待排序的节点
while(now!=NULL){
ListNode* node=tHead;
while(node->next!=NULL&&node->next->val<now->val) node=node->next;
if(node==tail){
tail=now;
now=now->next;
continue;
}
tail->next=now->next;
now->next=node->next;
node->next=now;
now=tail->next;
}
return tHead->next;
}
};148. 排序链表
Description
在 $O(n\log{n})$ 时间复杂度和常数级空间复杂度下,对链表进行排序。
Example
示例 1:
输入: 4->2->1->3
输出: 1->2->3->4
示例 2:
输入: -1->5->3->4->0
输出: -1->0->3->4->5
Program
思路
(1)总体为数组版的非递归二路归并;
(2)每次选择两个长度最多为为step(最多:有的时候链表末尾元素不足)的链表进行合并;
(3)cut(p, n):表示从p开始切除n个元素的链表,并返回后面的头结点,注意切出的链表尾部应当为NULL,注意处理!;merge则表示合并两个链表
时间复杂度:$O(n\log{n})$
空间复杂度:$O(1)$
1 | /** |
179. 最大数
Description
给定一组非负整数,重新排列它们的顺序使之组成一个最大的整数。
Example
示例 1:
输入: [10,2]
输出: 210
示例 2:
输入: [3,30,34,5,9]
输出: 9534330
说明: 输出结果可能非常大,所以你需要返回一个字符串而不是整数。
Program
思路
首先整数转成字符串,然后按照字典序降序,但是类似于样例2,”34”,”30”,”3”这种情况就不行了,任何两个字符串a,b,如果a+b>b+a,那么a在前面。
1 | class Solution { |
220. 存在重复元素 III
Description
在整数数组 nums 中,是否存在两个下标 i 和 j,使得 nums [i] 和 nums [j] 的差的绝对值小于等于 t ,且满足 i 和 j 的差的绝对值也小于等于 ķ 。
如果存在则返回 true,不存在返回 false。
Example
示例 1:
输入: nums = [1,2,3,1], k = 3, t = 0
输出: true
示例 2:
输入: nums = [1,0,1,1], k = 1, t = 2
输出: true
示例 3:
输入: nums = [1,5,9,1,5,9], k = 2, t = 3
输出: false
Program
排序+暴力
时间复杂度:$O(n^2)$
1 | class Solution { |
滑动窗口
(1)$|nums[i] - nums[j]| <=t $等价于$nums[j]-t <= nums[i] <= nums[j]+t$
(2)窗口内的数有序,且找到当前窗口内大于等于$nums[j]-t$第一个数nums[i],如果$nums[i]<=nums[j]+t$成立,那么说明存在;否则不存在。
时间复杂度:$O(n\log{k})$
1 | class Solution { |
242. 有效的字母异位词
Description
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
Example
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
说明:
你可以假设字符串只包含小写字母。
进阶:
如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
Program
排序
时间复杂度:$O(n\log{n})$
1 | class Solution { |
哈希表
时间复杂度:$O(n)$
1 | class Solution { |
324. 摆动排序 II
Description
给定一个无序的数组 nums,将它重新排列成 nums[0] < nums[1] > nums[2] < nums[3]… 的顺序。
Example
示例 1:
输入: nums = [1, 5, 1, 1, 6, 4]
输出: 一个可能的答案是 [1, 4, 1, 5, 1, 6]
示例 2:
输入: nums = [1, 3, 2, 2, 3, 1]
输出: 一个可能的答案是 [2, 3, 1, 3, 1, 2]
说明:
你可以假设所有输入都会得到有效的结果。
进阶:
你能用 O(n) 时间复杂度和 / 或原地 O(1) 额外空间来实现吗?
Program
首先,我们可以很容易想到一种简单的解法:将数组进行排序,然后从中间位置进行等分(如果数组长度为奇数,则将中间的元素分到前面),然后将两个数组进行穿插。
例如:
对于数组[1, 5, 2, 4, 3],我们将其排序,得到[1, 2, 3, 4, 5],然后将其分割为[1, 2, 3]和[4, 5],对两个数组进行穿插,得到[1, 4, 2, 5, 3]。
但是这一解法有一个问题,例如,对于数组[1, 2, 2, 3],按照这种做法求得的结果仍为[1, 2, 2, 3]。如果题目不要求各元素严格大于或小于相邻元素,即,只要求nums[0] <= nums[1] >= nums[2] <= nums[3]…,那么这一解法是符合要求的,但题目要求元素相互严格大于或小于,那么需要稍微做一点改进。
为了方便阅读,我们在下文中定义较小的子数组为数组A,较大的子数组为数组B。显然,出现上述现象是因为nums中存在重复元素。实际上,由于穿插之后,相邻元素必来自不同子数组,所以A或B内部出现重复元素是不会出现上述现象的。所以,出现上述情况其实是因为数组A和数组B出现了相同元素,我们用r来表示这一元素。而且我们可以很容易发现,如果A和B都存在r,那么r一定是A的最大值,B的最小值,这意味着r一定出现在A的尾部,B的头部。其实,如果这一数字的个数较少,不会出现这一现象,只有当这一数字个数达到原数组元素总数的一半,才会在穿插后的出现在相邻位置。以下举几个例子进行形象地说明:
例如,对于数组[1,1,2,2,3,3],分割为[1,1,2]和[2,3,3],虽然A和B都出现了2,但穿插后为[1,2,1,3,2,3],满足要求。
而如果2的个数再多一些,即[1,1,2,2,2,3],分割为[1,1,2]和[2,2,3],最终结果为[1,2,1,2,2,3],来自A的2和来自B的2出现在了相邻位置。
出现这一问题是因为重复数在A和B中的位置决定的,因为r在A尾部,B头部,所以如果r个数太多(大于等于(length(nums) + 1)/2),就可能在穿插后相邻。要解决这一问题,我们需要使A的r和B的r在穿插后尽可能分开。一种可行的办法是将A和B反序:
例如,对于数组[1,1,2,2,2,3],分割为[1,1,2]和[2,2,3],分别反序后得到[2, 1, 1]和[3, 2, 2],此时2在A头部,B尾部,穿插后就不会发生相邻了。
当然,这只能解决r的个数等于(length(nums) + 1)/2的情况,如果r的个数大于(length(nums) + 1)/2,还是会出现相邻。但实际上,这种情况是不存在有效解的,也就是说,这种数组对于本题来说是非法的。
此时我们得到了第一个解法,由于需要使用排序,所以时间复杂度为O(NlogN),由于需要存储A和B,所以空间复杂度为O(N)。
1 | class Solution { |
524. 通过删除字母匹配到字典里最长单词
Description
给定一个字符串和一个字符串字典,找到字典里面最长的字符串,该字符串可以通过删除给定字符串的某些字符来得到。如果答案不止一个,返回长度最长且字典顺序最小的字符串。如果答案不存在,则返回空字符串。
Example
示例 1:
输入:
s = “abpcplea”, d = [“ale”,”apple”,”monkey”,”plea”]
输出:
“apple”
示例 2:
输入:
s = “abpcplea”, d = [“a”,”b”,”c”]
输出:
“a”
说明:
所有输入的字符串只包含小写字母。
字典的大小不会超过 1000。
所有输入的字符串长度不会超过 1000。
Program
思路
(1)题目意思“给定字符串删除某些字符”能够与字典中的字符串匹配,且要求匹配的字符最长,也就是说字典中匹配的字符串是给定字符串的子序列!且要求子序列尽可能最长!
(2)题目需要字典序小的最长匹配字符串,则需要先排序
(3)字典中每个字符串与给定字符进行比较,保留最长的那个即可
时间复杂度:$O(n^2)$
空间复杂度:$O(1)$
1 | class Solution { |
853. 车队
Description
N 辆车沿着一条车道驶向位于 target 英里之外的共同目的地。
每辆车 i 以恒定的速度 speed[i] (英里/小时),从初始位置 position[i] (英里) 沿车道驶向目的地。
一辆车永远不会超过前面的另一辆车,但它可以追上去,并与前车以相同的速度紧接着行驶。
此时,我们会忽略这两辆车之间的距离,也就是说,它们被假定处于相同的位置。
车队 是一些由行驶在相同位置、具有相同速度的车组成的非空集合。注意,一辆车也可以是一个车队。
即便一辆车在目的地才赶上了一个车队,它们仍然会被视作是同一个车队。
会有多少车队到达目的地?
Example
示例:
输入:target = 12, position = [10,8,0,5,3], speed = [2,4,1,1,3]
输出:3
解释:
从 10 和 8 开始的车会组成一个车队,它们在 12 处相遇。
从 0 处开始的车无法追上其它车,所以它自己就是一个车队。
从 5 和 3 开始的车会组成一个车队,它们在 6 处相遇。
请注意,在到达目的地之前没有其它车会遇到这些车队,所以答案是 3。
提示:
0 <= N <= 10 ^ 4
0 < target <= 10 ^ 6
0 < speed[i] <= 10 ^ 6
0 <= position[i] < target
所有车的初始位置各不相同。
Program
排序+单调栈
(1)首先,根据pos进行排序;
(2)然后计算各自的用时;
(3)从后往前实现单调递增栈:
- 因为后车追上前车时,后车将与前车同行同速,此时直接忽视后车即可;
- 如果后车和前车同样用时,忽略后车;
- 如果后车用时比前车大,则后车永远追不上前车,应当保留;
- 这个过程使用单调递增栈,注意后车追上前车,仅保留前车结果!
时间复杂度:$O(n\log{n})$,排序复杂度$O(n\log{n})$,遍历+栈总体复杂度$O(n)$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42**排序+单调栈**
(1)首先,根据pos进行排序;
(2)然后计算各自的用时;
(3)从后往前实现单调递增栈:
- 因为后车追上前车时,后车将与前车同行同速,此时直接忽视后车即可;
- 如果后车和前车同样用时,忽略后车;
- 如果后车用时比前车大,则后车永远追不上前车,应当保留;
- 这个过程使用单调递增栈,注意后车追上前车,仅保留前车结果!
时间复杂度:$O(n\log{n})$,排序复杂度$O(n\log{n})$,遍历+栈总体复杂度$O(n)$
```cpp
class Solution {
public:
struct Node{
int pos;
int speed;
Node(){}
Node(int _pos, int _speed):pos(_pos),speed(_speed){}
bool operator<(const Node& other) const{
return pos<other.pos;
}
};
int carFleet(int target, vector<int>& position, vector<int>& speed) {
int n=position.size();
vector<Node> vec;
for(int i=0;i<n;i++){
vec.push_back(Node(position[i], speed[i]));
}
sort(vec.begin(), vec.end()); //按照pos排序
vector<double> times;
for(int i=0;i<n;i++){ //计算各自用时
double time=(target-vec[i].pos)/(double)vec[i].speed;
times.push_back(time);
}
stack<double> stk;
for(int i=n-1;i>=0;i--){ //单调递增栈
if(stk.empty()||stk.top()<times[i]){
stk.push(times[i]);
} //注意后车不可能超过前车,只能与前车同速,故如果后车用时更少,忽略即可
}
return stk.size(); //栈中元素个数即最终答案
}
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35## 922. 按奇偶排序数组 II
**Description**
给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
你可以返回任何满足上述条件的数组作为答案。
**Example**
示例:
输入:[4,2,5,7]
输出:[4,5,2,7]
解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
提示:
2 <= A.length <= 20000
A.length % 2 == 0
0 <= A[i] <= 1000
**Program**
```cpp
class Solution {
public:
vector<int> sortArrayByParityII(vector<int>& A) {
vector<int> evens, odds;
for(int x:A){
if(x%2==0) evens.push_back(x);
else odds.push_back(x);
}
int p1=0,p2=0;
int n=A.size();
for(int i=0;i<n;i++){
if(i%2==0) A[i]=evens[p1++];
else A[i]=odds[p2++];
}
return A;
}
};969. 煎饼排序
Description
给定数组 A,我们可以对其进行煎饼翻转:我们选择一些正整数 k <= A.length,然后反转 A 的前 k 个元素的顺序。我们要执行零次或多次煎饼翻转(按顺序一次接一次地进行)以完成对数组 A 的排序。
返回能使 A 排序的煎饼翻转操作所对应的 k 值序列。任何将数组排序且翻转次数在 10 * A.length 范围内的有效答案都将被判断为正确。
Example
示例 1:
输入:[3,2,4,1]
输出:[4,2,4,3]
解释:
我们执行 4 次煎饼翻转,k 值分别为 4,2,4,和 3。
初始状态 A = [3, 2, 4, 1]
第一次翻转后 (k=4): A = [1, 4, 2, 3]
第二次翻转后 (k=2): A = [4, 1, 2, 3]
第三次翻转后 (k=4): A = [3, 2, 1, 4]
第四次翻转后 (k=3): A = [1, 2, 3, 4],此时已完成排序。
示例 2:
输入:[1,2,3]
输出:[]
解释:
输入已经排序,因此不需要翻转任何内容。
请注意,其他可能的答案,如[3,3],也将被接受。
提示:
1 <= A.length <= 100
A[i] 是 [1, 2, …, A.length] 的排列
Program
数学
(1)对区间[0,i],找到最大值下标j:
(2)翻转[0,j],将最大值移到第一个位置;
(3)翻转[0,i],将最大值移到最后一个位置;
时间复杂度:$O(n^2)$
1 | class Solution { |
1030. 距离顺序排列矩阵单元格
Description
给出 R 行 C 列的矩阵,其中的单元格的整数坐标为 (r, c),满足 0 <= r < R 且 0 <= c < C。
另外,我们在该矩阵中给出了一个坐标为 (r0, c0) 的单元格。
返回矩阵中的所有单元格的坐标,并按到 (r0, c0) 的距离从最小到最大的顺序排,其中,两单元格(r1, c1) 和 (r2, c2) 之间的距离是曼哈顿距离,|r1 - r2| + |c1 - c2|。(你可以按任何满足此条件的顺序返回答案。)
Example
示例 1:
输入:R = 1, C = 2, r0 = 0, c0 = 0
输出:[[0,0],[0,1]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1]
示例 2:
输入:R = 2, C = 2, r0 = 0, c0 = 1
输出:[[0,1],[0,0],[1,1],[1,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2]
[[0,1],[1,1],[0,0],[1,0]] 也会被视作正确答案。
示例 3:
输入:R = 2, C = 3, r0 = 1, c0 = 2
输出:[[1,2],[0,2],[1,1],[0,1],[1,0],[0,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2,2,3]
其他满足题目要求的答案也会被视为正确,例如 [[1,2],[1,1],[0,2],[1,0],[0,1],[0,0]]。
提示:
1 <= R <= 100
1 <= C <= 100
0 <= r0 < R
0 <= c0 < C
Program
1 | class Solution { |
1122. 数组的相对排序
Description
给你两个数组,arr1 和 arr2,
arr2 中的元素各不相同
arr2 中的每个元素都出现在 arr1 中
对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
Example
示例:
输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
输出:[2,2,2,1,4,3,3,9,6,7,19]
提示:
arr1.length, arr2.length <= 1000
0 <= arr1[i], arr2[i] <= 1000
arr2 中的元素 arr2[i] 各不相同
arr2 中的每个元素 arr2[i] 都出现在 arr1 中
Program
1 | class Solution { |
1305. 两棵二叉搜索树中的所有元素
Description
给你 root1 和 root2 这两棵二叉搜索树。
请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
Example
示例 1: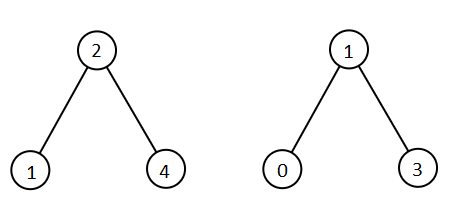
输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
示例 2:
输入:root1 = [0,-10,10], root2 = [5,1,7,0,2]
输出:[-10,0,0,1,2,5,7,10]
示例 3:
输入:root1 = [], root2 = [5,1,7,0,2]
输出:[0,1,2,5,7]
示例 4:
输入:root1 = [0,-10,10], root2 = []
输出:[-10,0,10]
示例 5: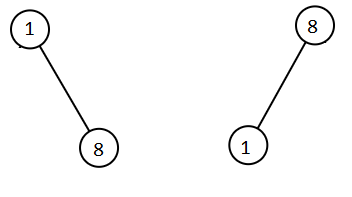
输入:root1 = [1,null,8], root2 = [8,1]
输出:[1,1,8,8]
提示:
每棵树最多有 5000 个节点。
每个节点的值在 [-10^5, 10^5] 之间。
Program
1 | /** |
1329. 将矩阵按对角线排序
Description
给你一个 m * n 的整数矩阵 mat ,请你将同一条对角线上的元素(从左上到右下)按升序排序后,返回排好序的矩阵。
Example
示例 1: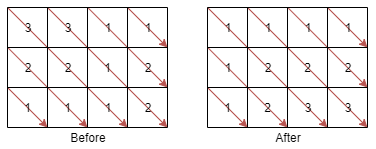
输入:mat = [[3,3,1,1],[2,2,1,2],[1,1,1,2]]
输出:[[1,1,1,1],[1,2,2,2],[1,2,3,3]]
提示:
m == mat.length
n == mat[i].length
1 <= m, n <= 100
1 <= mat[i][j] <= 100
Program
1 | class Solution { |
1366. 通过投票对团队排名
Description
现在有一个特殊的排名系统,依据参赛团队在投票人心中的次序进行排名,每个投票者都需要按从高到低的顺序对参与排名的所有团队进行排位。
排名规则如下:
参赛团队的排名次序依照其所获「排位第一」的票的多少决定。如果存在多个团队并列的情况,将继续考虑其「排位第二」的票的数量。以此类推,直到不再存在并列的情况。
如果在考虑完所有投票情况后仍然出现并列现象,则根据团队字母的字母顺序进行排名。
给你一个字符串数组 votes 代表全体投票者给出的排位情况,请你根据上述排名规则对所有参赛团队进行排名。
请你返回能表示按排名系统 排序后 的所有团队排名的字符串。
Example
示例 1:
输入:votes = [“ABC”,”ACB”,”ABC”,”ACB”,”ACB”]
输出:”ACB”
解释:A 队获得五票「排位第一」,没有其他队获得「排位第一」,所以 A 队排名第一。
B 队获得两票「排位第二」,三票「排位第三」。
C 队获得三票「排位第二」,两票「排位第三」。
由于 C 队「排位第二」的票数较多,所以 C 队排第二,B 队排第三。
示例 2:
输入:votes = [“WXYZ”,”XYZW”]
输出:”XWYZ”
解释:X 队在并列僵局打破后成为排名第一的团队。X 队和 W 队的「排位第一」票数一样,但是 X 队有一票「排位第二」,而 W 没有获得「排位第二」。
示例 3:
输入:votes = [“ZMNAGUEDSJYLBOPHRQICWFXTVK”]
输出:”ZMNAGUEDSJYLBOPHRQICWFXTVK”
解释:只有一个投票者,所以排名完全按照他的意愿。
示例 4:
输入:votes = [“BCA”,”CAB”,”CBA”,”ABC”,”ACB”,”BAC”]
输出:”ABC”
解释:
A 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。
B 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。
C 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。
完全并列,所以我们需要按照字母升序排名。
示例 5:
输入:votes = [“M”,”M”,”M”,”M”]
输出:”M”
解释:只有 M 队参赛,所以它排名第一。
提示:
1 <= votes.length <= 1000
1 <= votes[i].length <= 26
votes[i].length == votes[j].length for 0 <= i, j < votes.length
votes[i][j] 是英文 大写 字母
votes[i] 中的所有字母都是唯一的
votes[0] 中出现的所有字母 同样也 出现在 votes[j] 中,其中 1 <= j < votes.length
Program
1 | class Solution { |
1387. 将整数按权重排序
Description
我们将整数 x 的 权重 定义为按照下述规则将 x 变成 1 所需要的步数:
如果 x 是偶数,那么 x = x / 2
如果 x 是奇数,那么 x = 3 * x + 1
比方说,x=3 的权重为 7 。因为 3 需要 7 步变成 1 (3 –> 10 –> 5 –> 16 –> 8 –> 4 –> 2 –> 1)。
给你三个整数 lo, hi 和 k 。你的任务是将区间 [lo, hi] 之间的整数按照它们的权重 升序排序 ,如果大于等于 2 个整数有 相同 的权重,那么按照数字自身的数值 升序排序 。
请你返回区间 [lo, hi] 之间的整数按权重排序后的第 k 个数。
注意,题目保证对于任意整数 x (lo <= x <= hi) ,它变成 1 所需要的步数是一个 32 位有符号整数。
Example
示例 1:
输入:lo = 12, hi = 15, k = 2
输出:13
解释:12 的权重为 9(12 –> 6 –> 3 –> 10 –> 5 –> 16 –> 8 –> 4 –> 2 –> 1)
13 的权重为 9
14 的权重为 17
15 的权重为 17
区间内的数按权重排序以后的结果为 [12,13,14,15] 。对于 k = 2 ,答案是第二个整数也就是 13 。
注意,12 和 13 有相同的权重,所以我们按照它们本身升序排序。14 和 15 同理。
示例 2:
输入:lo = 1, hi = 1, k = 1
输出:1
示例 3:
输入:lo = 7, hi = 11, k = 4
输出:7
解释:区间内整数 [7, 8, 9, 10, 11] 对应的权重为 [16, 3, 19, 6, 14] 。
按权重排序后得到的结果为 [8, 10, 11, 7, 9] 。
排序后数组中第 4 个数字为 7 。
示例 4:
输入:lo = 10, hi = 20, k = 5
输出:13
示例 5:
输入:lo = 1, hi = 1000, k = 777
输出:570
提示:
1 <= lo <= hi <= 1000
1 <= k <= hi - lo + 1
Program
1 | class Solution { |
1424. 对角线遍历 II
Description
给你一个列表 nums ,里面每一个元素都是一个整数列表。请你依照下面各图的规则,按顺序返回 nums 中对角线上的整数。
Example
示例 1:
输入:nums = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,4,2,7,5,3,8,6,9]
示例 2: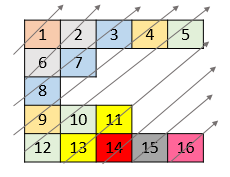
输入:nums = [[1,2,3,4,5],[6,7],[8],[9,10,11],[12,13,14,15,16]]
输出:[1,6,2,8,7,3,9,4,12,10,5,13,11,14,15,16]
示例 3:
输入:nums = [[1,2,3],[4],[5,6,7],[8],[9,10,11]]
输出:[1,4,2,5,3,8,6,9,7,10,11]
示例 4:
输入:nums = [[1,2,3,4,5,6]]
输出:[1,2,3,4,5,6]
提示:
1 <= nums.length <= 10^5
1 <= nums[i].length <= 10^5
1 <= nums[i][j] <= 10^9
nums 中最多有 10^5 个数字。
Program
1 | class Solution { |
1452. 收藏清单
Description
给你一个数组 favoriteCompanies ,其中 favoriteCompanies[i] 是第 i 名用户收藏的公司清单(下标从 0 开始)。
请找出不是其他任何人收藏的公司清单的子集的收藏清单,并返回该清单下标。下标需要按升序排列。
Example
示例 1:
输入:favoriteCompanies = [[“leetcode”,”google”,”facebook”],[“google”,”microsoft”],[“google”,”facebook”],[“google”],[“amazon”]]
输出:[0,1,4]
解释:
favoriteCompanies[2]=[“google”,”facebook”] 是 favoriteCompanies[0]=[“leetcode”,”google”,”facebook”] 的子集。
favoriteCompanies[3]=[“google”] 是 favoriteCompanies[0]=[“leetcode”,”google”,”facebook”] 和 favoriteCompanies[1]=[“google”,”microsoft”] 的子集。
其余的收藏清单均不是其他任何人收藏的公司清单的子集,因此,答案为 [0,1,4] 。
示例 2:
输入:favoriteCompanies = [[“leetcode”,”google”,”facebook”],[“leetcode”,”amazon”],[“facebook”,”google”]]
输出:[0,1]
解释:favoriteCompanies[2]=[“facebook”,”google”] 是 favoriteCompanies[0]=[“leetcode”,”google”,”facebook”] 的子集,因此,答案为 [0,1] 。
示例 3:
输入:favoriteCompanies = [[“leetcode”],[“google”],[“facebook”],[“amazon”]]
输出:[0,1,2,3]
提示:
1 <= favoriteCompanies.length <= 100
1 <= favoriteCompanies[i].length <= 500
1 <= favoriteCompanies[i][j].length <= 20
favoriteCompanies[i] 中的所有字符串 各不相同 。
用户收藏的公司清单也 各不相同 ,也就是说,即便我们按字母顺序排序每个清单, favoriteCompanies[i] != favoriteCompanies[j] 仍然成立。
所有字符串仅包含小写英文字母。
Program
1 | class Solution { |
1471. 数组中的 k 个最强值
Description
给你一个整数数组 arr 和一个整数 k 。
设 m 为数组的中位数,只要满足下述两个前提之一,就可以判定 arr[i] 的值比 arr[j] 的值更强:
1 | |arr[i] - m| > |arr[j] - m| |
请返回由数组中最强的 k 个值组成的列表。答案可以以 任意顺序 返回。
中位数 是一个有序整数列表中处于中间位置的值。形式上,如果列表的长度为 n ,那么中位数就是该有序列表(下标从 0 开始)中位于 ((n - 1) / 2) 的元素。
例如 arr = [6, -3, 7, 2, 11],n = 5:数组排序后得到 arr = [-3, 2, 6, 7, 11] ,数组的中间位置为 m = ((5 - 1) / 2) = 2 ,中位数 arr[m] 的值为 6 。
例如 arr = [-7, 22, 17, 3],n = 4:数组排序后得到 arr = [-7, 3, 17, 22] ,数组的中间位置为 m = ((4 - 1) / 2) = 1 ,中位数 arr[m] 的值为 3 。
Example
示例 1:
输入:arr = [1,2,3,4,5], k = 2
输出:[5,1]
解释:中位数为 3,按从强到弱顺序排序后,数组变为 [5,1,4,2,3]。最强的两个元素是 [5, 1]。[1, 5] 也是正确答案。
注意,尽管 |5 - 3| == |1 - 3| ,但是 5 比 1 更强,因为 5 > 1 。
示例 2:
输入:arr = [1,1,3,5,5], k = 2
输出:[5,5]
解释:中位数为 3, 按从强到弱顺序排序后,数组变为 [5,5,1,1,3]。最强的两个元素是 [5, 5]。
示例 3:
输入:arr = [6,7,11,7,6,8], k = 5
输出:[11,8,6,6,7]
解释:中位数为 7, 按从强到弱顺序排序后,数组变为 [11,8,6,6,7,7]。
[11,8,6,6,7] 的任何排列都是正确答案。
示例 4:
输入:arr = [6,-3,7,2,11], k = 3
输出:[-3,11,2]
示例 5:
输入:arr = [-7,22,17,3], k = 2
输出:[22,17]
提示:
1 <= arr.length <= 10^5
-10^5 <= arr[i] <= 10^5
1 <= k <= arr.length
Program
1 | class Solution { |
1481. 不同整数的最少数目
Description
给你一个整数数组 arr 和一个整数 k 。现需要从数组中恰好移除 k 个元素,请找出移除后数组中不同整数的最少数目。
Example
示例 1:
输入:arr = [5,5,4], k = 1
输出:1
解释:移除 1 个 4 ,数组中只剩下 5 一种整数。
示例 2:
输入:arr = [4,3,1,1,3,3,2], k = 3
输出:2
解释:先移除 4、2 ,然后再移除两个 1 中的任意 1 个或者三个 3 中的任意 1 个,最后剩下 1 和 3 两种整数。
提示:
1 <= arr.length <= 10^5
1 <= arr[i] <= 10^9
0 <= k <= arr.length
Program
1 | class Solution { |
1491. 去掉最低工资和最高工资后的工资平均值
Description
给你一个整数数组 salary ,数组里每个数都是 唯一 的,其中 salary[i] 是第 i 个员工的工资。
请你返回去掉最低工资和最高工资以后,剩下员工工资的平均值。
Example
示例 1:
输入:salary = [4000,3000,1000,2000]
输出:2500.00000
解释:最低工资和最高工资分别是 1000 和 4000 。
去掉最低工资和最高工资以后的平均工资是 (2000+3000)/2= 2500
示例 2:
输入:salary = [1000,2000,3000]
输出:2000.00000
解释:最低工资和最高工资分别是 1000 和 3000 。
去掉最低工资和最高工资以后的平均工资是 (2000)/1= 2000
示例 3:
输入:salary = [6000,5000,4000,3000,2000,1000]
输出:3500.00000
示例 4:
输入:salary = [8000,9000,2000,3000,6000,1000]
输出:4750.00000
提示:
3 <= salary.length <= 100
10^3 <= salary[i] <= 10^6
salary[i] 是唯一的。
与真实值误差在 10^-5 以内的结果都将视为正确答案。
Program
1 | class Solution { |
1502. 判断能否形成等差数列
Description
给你一个数字数组 arr 。
如果一个数列中,任意相邻两项的差总等于同一个常数,那么这个数列就称为 等差数列 。
如果可以重新排列数组形成等差数列,请返回 true ;否则,返回 false 。
Example
示例 1:
输入:arr = [3,5,1]
输出:true
解释:对数组重新排序得到 [1,3,5] 或者 [5,3,1] ,任意相邻两项的差分别为 2 或 -2 ,可以形成等差数列。
示例 2:
输入:arr = [1,2,4]
输出:false
解释:无法通过重新排序得到等差数列。
提示:
2 <= arr.length <= 1000
-10^6 <= arr[i] <= 10^6
Program
1 | class Solution { |
1508. 子数组和排序后的区间和
Description
给你一个数组 nums ,它包含 n 个正整数。你需要计算所有非空连续子数组的和,并将它们按升序排序,得到一个新的包含 n * (n + 1) / 2 个数字的数组。
请你返回在新数组中下标为 left 到 right (下标从 1 开始)的所有数字和(包括左右端点)。由于答案可能很大,请你将它对 10^9 + 7 取模后返回。
Example
示例 1:
输入:nums = [1,2,3,4], n = 4, left = 1, right = 5
输出:13
解释:所有的子数组和为 1, 3, 6, 10, 2, 5, 9, 3, 7, 4 。将它们升序排序后,我们得到新的数组 [1, 2, 3, 3, 4, 5, 6, 7, 9, 10] 。下标从 le = 1 到 ri = 5 的和为 1 + 2 + 3 + 3 + 4 = 13 。
示例 2:
输入:nums = [1,2,3,4], n = 4, left = 3, right = 4
输出:6
解释:给定数组与示例 1 一样,所以新数组为 [1, 2, 3, 3, 4, 5, 6, 7, 9, 10] 。下标从 le = 3 到 ri = 4 的和为 3 + 3 = 6 。
示例 3:
输入:nums = [1,2,3,4], n = 4, left = 1, right = 10
输出:50
提示:
1 <= nums.length <= 10^3
nums.length == n
1 <= nums[i] <= 100
1 <= left <= right <= n * (n + 1) / 2
Program
1 | class Solution { |
1528. 重新排列字符串
Description
给你一个字符串 s 和一个 长度相同 的整数数组 indices 。
请你重新排列字符串 s ,其中第 i 个字符需要移动到 indices[i] 指示的位置。
返回重新排列后的字符串。
Example
示例 1:
输入:s = “codeleet”, indices = [4,5,6,7,0,2,1,3]
输出:”leetcode”
解释:如图所示,”codeleet” 重新排列后变为 “leetcode” 。
示例 2:
输入:s = “abc”, indices = [0,1,2]
输出:”abc”
解释:重新排列后,每个字符都还留在原来的位置上。
示例 3:
输入:s = “aiohn”, indices = [3,1,4,2,0]
输出:”nihao”
示例 4:
输入:s = “aaiougrt”, indices = [4,0,2,6,7,3,1,5]
输出:”arigatou”
示例 5:
输入:s = “art”, indices = [1,0,2]
输出:”rat”
提示:
s.length == indices.length == n
1 <= n <= 100
s 仅包含小写英文字母。
0 <= indices[i] < n
indices 的所有的值都是唯一的(也就是说,indices 是整数 0 到 n - 1 形成的一组排列)。
Program
1 | class Solution { |
1561. 你可以获得的最大硬币数目
Description
有 3n 堆数目不一的硬币,你和你的朋友们打算按以下方式分硬币:
每一轮中,你将会选出 任意 3 堆硬币(不一定连续)。
Alice 将会取走硬币数量最多的那一堆。
你将会取走硬币数量第二多的那一堆。
Bob 将会取走最后一堆。
重复这个过程,直到没有更多硬币。
给你一个整数数组 piles ,其中 piles[i] 是第 i 堆中硬币的数目。
返回你可以获得的最大硬币数目。
Example
示例 1:
输入:piles = [2,4,1,2,7,8]
输出:9
解释:选出 (2, 7, 8) ,Alice 取走 8 枚硬币的那堆,你取走 7 枚硬币的那堆,Bob 取走最后一堆。
选出 (1, 2, 4) , Alice 取走 4 枚硬币的那堆,你取走 2 枚硬币的那堆,Bob 取走最后一堆。
你可以获得的最大硬币数目:7 + 2 = 9.
考虑另外一种情况,如果选出的是 (1, 2, 8) 和 (2, 4, 7) ,你就只能得到 2 + 4 = 6 枚硬币,这不是最优解。
示例 2:
输入:piles = [2,4,5]
输出:4
示例 3:
输入:piles = [9,8,7,6,5,1,2,3,4]
输出:18
提示:
3 <= piles.length <= 10^5
piles.length % 3 == 0
1 <= piles[i] <= 10^4
Program
1 | class Solution { |
1636. 按照频率将数组升序排序
Description
给你一个整数数组 nums ,请你将数组按照每个值的频率 升序 排序。如果有多个值的频率相同,请你按照数值本身将它们 降序 排序。
请你返回排序后的数组。
Example
示例 1:
输入:nums = [1,1,2,2,2,3]
输出:[3,1,1,2,2,2]
解释:’3’ 频率为 1,’1’ 频率为 2,’2’ 频率为 3 。
示例 2:
输入:nums = [2,3,1,3,2]
输出:[1,3,3,2,2]
解释:’2’ 和 ‘3’ 频率都为 2 ,所以它们之间按照数值本身降序排序。
示例 3:
输入:nums = [-1,1,-6,4,5,-6,1,4,1]
输出:[5,-1,4,4,-6,-6,1,1,1]
提示:
1 <= nums.length <= 100
-100 <= nums[i] <= 100
Program
1 | class Solution { |
1637. 两点之间不包含任何点的最宽垂直面积
Description
给你 n 个二维平面上的点 points ,其中 points[i] = [xi, yi] ,请你返回两点之间内部不包含任何点的 最宽垂直面积 的宽度。
垂直面积 的定义是固定宽度,而 y 轴上无限延伸的一块区域(也就是高度为无穷大)。 最宽垂直面积 为宽度最大的一个垂直面积。
请注意,垂直区域 边上 的点 不在 区域内。
Example
示例 1:
输入:points = [[8,7],[9,9],[7,4],[9,7]]
输出:1
解释:红色区域和蓝色区域都是最优区域。
示例 2:
输入:points = [[3,1],[9,0],[1,0],[1,4],[5,3],[8,8]]
输出:3
提示:
$n == points.length$
$2 <= n <= 10^5$
$points[i].length == 2$
$0 <= x_i, y_i <= 10^9$
Program
1 | class Solution { |
深搜
733. 图像渲染
Description
有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间。
给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的颜色值 newColor,让你重新上色这幅图像。
为了完成上色工作,从初始坐标开始,记录初始坐标的上下左右四个方向上像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应四个方向上像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为新的颜色值。
最后返回经过上色渲染后的图像。
Example
示例 1:
输入:
image = [[1,1,1],[1,1,0],[1,0,1]]
sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析:
在图像的正中间,(坐标(sr,sc)=(1,1)),
在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,
因为它不是在上下左右四个方向上与初始点相连的像素点。
注意:
image 和 image[0] 的长度在范围 [1, 50] 内。
给出的初始点将满足 0 <= sr < image.length 和 0 <= sc < image[0].length。
image[i][j] 和 newColor 表示的颜色值在范围 [0, 65535]内。
Program
1 | class Solution { |
841. 钥匙和房间
Description
有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,…,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。
在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,…,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。
最初,除 0 号房间外的其余所有房间都被锁住。
你可以自由地在房间之间来回走动。
如果能进入每个房间返回 true,否则返回 false。
Example
示例 1:
输入: [[1],[2],[3],[]]
输出: true
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。
示例 2:
输入:[[1,3],[3,0,1],[2],[0]]
输出:false
解释:我们不能进入 2 号房间。
提示:
1 <= rooms.length <= 1000
0 <= rooms[i].length <= 1000
所有房间中的钥匙数量总计不超过 3000。
Program
1 | class Solution { |
双指针
11. 盛最多水的容器
Description
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。
图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
Example
示例:
输入:[1,8,6,2,5,4,8,3,7]
输出:49
Program
思路
(1)双指针left,right分别指向数组头尾;
(2)每次高度更小的索引更新,$min(height[left],height[right])*(right-left)$,因为高度大的肯定面积更小,高度小的更新后才可能出现更大的值;
如下图所示,在一开始,我们考虑相距最远的两个柱子所能容纳水的面积。水的宽度是两根柱子之间的距离 d = 8d=8;水的高度取决于两根柱子之间较短的那个,即左边柱子的高度 h = 3。水的面积就是3×8=24。
- 如果选择固定一根柱子,另外一根变化,水的面积会有什么变化吗?稍加思考可得:
- 当前柱子是最两侧的柱子,水的宽度 dd 为最大,其他的组合,水的宽度都比这个小。
- 左边柱子较短,决定了水的高度为 3。如果移动左边的柱子,新的水面高度不确定,一定不会超过右边的柱子高度 7。
- 如果移动右边的柱子,新的水面高度一定不会超过左边的柱子高度 3,也就是不会超过现在的水面高度。
由此可见,如果固定左边的柱子,移动右边的柱子,那么水的高度一定不会增加,且宽度一定减少,所以水的面积一定减少。这个时候,左边的柱子和任意一个其他柱子的组合,其实都可以排除了。也就是我们可以排除掉左边的柱子了。
这个排除掉左边柱子的操作,就是双指针代码里的 i++。i 和 j 两个指针中间的区域都是还未排除掉的区域。随着不断的排除,i 和 j 都会往中间移动。当 i 和 j 相遇,算法就结束了
1 | class Solution { |
31. 下一个排列
Description
实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须原地修改,只允许使用额外常数空间。
以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
1 | 1,2,3 → 1,3,2 |
Program
思路
(1)我们希望下一个数比当前数大,因此需要从后面选择一个较大的数跟前面的小数交换;
(2)而我们又希望下一个数增加的幅度尽可能小
(3)从后往前遍历,查找可能的较小大数与前面的小数交换;
算法过程:
(1)从后往前查找第一个相邻升序的元素对(i, j),满足A[i]<A[j]。
(2)[j,end)从后往前找第一个满足A[i]<A[k]的k,二者交换;
(3)交换后,[j,end]肯定是降序的,所以只需要逆置就可以。
(4)注意已经是最大排列的情况。
1 | class Solution { |
344. 反转字符串
Description
写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
Example
示例 1:
输入:[“h”,”e”,”l”,”l”,”o”]
输出:[“o”,”l”,”l”,”e”,”h”]
示例 2:
输入:[“H”,”a”,”n”,”n”,”a”,”h”]
输出:[“h”,”a”,”n”,”n”,”a”,”H”]
Program
1 | class Solution { |
面试题 16.06. 最小差
Description
给定两个整数数组a和b,计算具有最小差绝对值的一对数值(每个数组中取一个值),并返回该对数值的差
Example
示例:
输入:{1, 3, 15, 11, 2}, {23, 127, 235, 19, 8}
输出: 3,即数值对(11, 8)
提示:
1 <= a.length, b.length <= 100000
-2147483648 <= a[i], b[i] <= 2147483647
正确结果在区间[-2147483648, 2147483647]内
Program
排序+双指针
详见代码
1 | class Solution { |
面试题 17.11. 单词距离
Description
有个内含单词的超大文本文件,给定任意两个单词,找出在这个文件中这两个单词的最短距离(相隔单词数)。如果寻找过程在这个文件中会重复多次,而每次寻找的单词不同,你能对此优化吗?
Example
示例:
输入:words = [“I”,”am”,”a”,”student”,”from”,”a”,”university”,”in”,”a”,”city”], word1 = “a”, word2 = “student”
输出:1
提示:
words.length <= 100000
Program
哈希+双指针
(1)哈希表建立重复单词出现的位置;
(2)双指针查找两个待查单词的索引数组(升序):
由于索引数组有序,比较两个索引的时候,A[i]<B[j]则i++,反之j++;这是因为要使得abs(A[i]-B[j])绝对值最小,较小的数组指针后移才能缩小。
时间复杂度:$O(m+n)$
1 | class Solution { |
栈/字符串
32. 最长有效括号
Description
给定一个只包含 ‘(‘ 和 ‘)’ 的字符串,找出最长的包含有效括号的子串的长度。
Example
示例 1:
输入: “(()”
输出: 2
解释: 最长有效括号子串为 “()”
示例 2:
输入: “)()())”
输出: 4
解释: 最长有效括号子串为 “()()”
Program
1 | class Solution { |
43. 字符串相乘
Description
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
Example
示例 1:
输入: num1 = “2”, num2 = “3”
输出: “6”
示例 2:
输入: num1 = “123”, num2 = “456”
输出: “56088”
说明:
num1 和 num2 的长度小于110。
num1 和 num2 只包含数字 0-9。
num1 和 num2 均不以零开头,除非是数字 0 本身。
不能使用任何标准库的大数类型(比如 BigInteger)或直接将输入转换为整数来处理。
Program
1 | class Solution { |
71. 简化路径
Description
以 Unix 风格给出一个文件的绝对路径,你需要简化它。或者换句话说,将其转换为规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。更多信息请参阅:Linux / Unix中的绝对路径 vs 相对路径
请注意,返回的规范路径必须始终以斜杠 / 开头,并且两个目录名之间必须只有一个斜杠 /。最后一个目录名(如果存在)不能以 / 结尾。此外,规范路径必须是表示绝对路径的最短字符串。
Example
示例 1:
输入:”/home/“
输出:”/home”
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:”/../“
输出:”/“
解释:从根目录向上一级是不可行的,因为根是你可以到达的最高级。
示例 3:
输入:”/home//foo/“
输出:”/home/foo”
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:”/a/./b/../../c/“
输出:”/c”
示例 5:
输入:”/a/../../b/../c//.//“
输出:”/c”
示例 6:
输入:”/a//b////c/d//././/..”
输出:”/a/b/c”
Program
思路
首先,预处理字符串,剔除‘/’,然后通过栈(这里为了方便用双端队列)进行简化操作:
- ①如果遇到’.’,不加入最终路径;
- ②如果遇到’..’,返回上一级目录,即从当前路径中删除最后一级目录(当前路径不是根目录,如果是根目录不变,这里用双端队列dq表示当前路径);
- ③如果遇到一般的字符串,加入当前路径;
最后通过加入必要的’/‘得到最终简化的路径。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
string simplifyPath(string path) {
vector<string> vec;
string str;
int n=path.length();
for(int i=0;i<n;i++){ //处理'/'之间的字符串,用str保存,如果str为空不加入数组vec
if(path[i]=='/'){
if(str!="") vec.push_back(str);
str="";
}else str+=path[i];
}
if(path[n-1]!='/'&&str!="") vec.push_back(str); //最后一个字符串
deque<string> dq;//用双端队列替换栈,方便操作
for(int i=0;i<vec.size();i++){
if(vec[i]==".") continue; //当前目录不加入栈
if(vec[i]=="..") {if(dq.size()>0)dq.pop_back();continue;} //跳至上一目录
dq.push_back(vec[i]); //加入目录
}
str="/";
for(int i=0;i<dq.size();i++){
str+=dq[i];
if(i!=dq.size()-1) str+='/';
}
return str;
}
};150. 逆波兰表达式求值
Description
根据 逆波兰表示法,求表达式的值。
有效的运算符包括 +, -, *, / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
整数除法只保留整数部分。
给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
Example
示例 1:
输入: [“2”, “1”, “+”, “3”, “*”]
输出: 9
解释: 该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
输入: [“4”, “13”, “5”, “/“, “+”]
输出: 6
解释: 该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入: [“10”, “6”, “9”, “3”, “+”, “-11”, “*”, “/“, “*”, “17”, “+”, “5”, “+”]
输出: 22
解释:
该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
Program
1 | class Solution { |
214. 最短回文串
Description
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
Example
示例 1:
输入: “aacecaaa”
输出: “aaacecaaa”
示例 2:
输入: “abcd”
输出: “dcbabcd”
Program
暴力
找前缀为最长回文的位置,然后拼接!
时间复杂度:$O(n^2)$
1 | class Solution { |
KMP的next前后缀求法
首先一个字符串与其逆串拼接肯定是回文串,问题使未必是最小!!
例如:s=abcd与rs=dcba,拼接为dcbaabcd,明显有冗余,冗余的部分为s前缀和rs后缀公共的部分!
那么需要求出这个公共部分最大的部分剔除就是答案了!
那么怎么求呢?
s+rs=abcddcba,要求最大重叠前后缀,与KMP的next数组一致!!!
但是得注意这里直接拼接s+rs会导致可能最长前后缀长度超过原本s的长度,所以中间插入”#”即可,即s+”#”+rs=abcd#dcba,再来求其最长重叠前后缀,就是next数组计算了!
时间复杂度:$O(n)$
1 | class Solution { |
316. 去除重复字母
Description
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
Example
示例 1:
输入:s = “bcabc”
输出:”abc”
示例 2:
输入:s = “cbacdcbc”
输出:”acdb”
提示:
1 <= s.length <= 104
s 由小写英文字母组成
Program
思路
题意需要三个条件:
(1)去重;
(2)相对位置不变;
(3)字典序最小;
由前两个条件只需要维护一个单调栈,遇到更小的字母,前面较大的字母出栈,即可,注意判重;
第三个条件则需要在出栈时检查即将出栈的元素是否后续没有该字母,如果是,不出栈,否则出栈。
1 | class Solution { |
321. 拼接最大数
Description
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
Example
示例 1:
输入:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
输出:
[9, 8, 6, 5, 3]
示例 2:
输入:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
输出:
[6, 7, 6, 0, 4]
示例 3:
输入:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
输出:
[9, 8, 9]
Program
单调栈
(1)老套路,与但数组下求保留k个数要求序列最大类似,这里为两个数组;
(2)分治:第一个数组保留i个,第二个数组保留k-i个,使得各自满足最大序列;
(3)合并:这里不同于归并排序的直接比较两个数组索引下的单个值,而需要考虑字典序最大!即取字典序较大的数组的头元素!
1 | class Solution { |
331. 验证二叉树的前序序列化
Description
序列化二叉树的一种方法是使用前序遍历。当我们遇到一个非空节点时,我们可以记录下这个节点的值。如果它是一个空节点,我们可以使用一个标记值记录,例如 #。
1 | _9_ |
例如,上面的二叉树可以被序列化为字符串 “9,3,4,#,#,1,#,#,2,#,6,#,#”,其中 # 代表一个空节点。
给定一串以逗号分隔的序列,验证它是否是正确的二叉树的前序序列化。编写一个在不重构树的条件下的可行算法。
每个以逗号分隔的字符或为一个整数或为一个表示 null 指针的 ‘#’ 。
你可以认为输入格式总是有效的,例如它永远不会包含两个连续的逗号,比如 “1,,3” 。
Example
示例 1:
输入: “9,3,4,#,#,1,#,#,2,#,6,#,#”
输出: true
示例 2:
输入: “1,#”
输出: false
示例 3:
输入: “9,#,#,1”
输出: false
Program
利用前序的特性,无需考虑数据
一个正确的二查数据结构,空节点数目=非空节点数目+1,其中空节点就是指”#”。
所以考虑前序遍历先跟后左右子树的特性,遇到数字就push,遇到“#”就pop,这一点与前序遍历的非递归栈实现相同(先遍历到左子树最左边的节点,当为空时就pop,这里就相当于遇到“#”就pop掉当前根结点,然后进入当前右子树)。
- 遇到“#”,如果栈为空,return i == n-1,即判断是否是最后一个,是则为正确结构,否则错误;
- 遇到数字,push即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
bool isValidSerialization(string preorder) {
int n=preorder.length();
stack<int> st;
for(int i=0;i<n;i++){
if(preorder[i]=='#'){
if(st.empty()) return i==n-1;
else{
st.pop();
i++;//跳过逗号
}
}else{
while(i<n&&preorder[i]!=',') i++; //需要跳过逗号分隔符
st.push(0);
}
}
return false;
}
};385. 迷你语法分析器
Description
给定一个用字符串表示的整数的嵌套列表,实现一个解析它的语法分析器。
列表中的每个元素只可能是整数或整数嵌套列表
提示:你可以假定这些字符串都是格式良好的:
- 字符串非空
- 字符串不包含空格
- 字符串只包含数字0-9、[、-、,、]
Example
示例 1:
给定 s = “324”,
你应该返回一个 NestedInteger 对象,其中只包含整数值 324。
示例 2:
给定 s = “[123,[456,[789]]]”,
返回一个 NestedInteger 对象包含一个有两个元素的嵌套列表:
1 | 1. 一个 integer 包含值 123 |
Program
字符串处理+栈
(1)字符串是纯数字,直接返回NestInteger的单整数版本;
(2)如果遇到“[”,则表示需要嵌套整数,即必须将默认的单整数版本通过add()转成嵌套链表,即使遇到”[]”这种也要转!,然后将其压入栈
(3)每次遇到“,”,判断当前str是否为空,不为空表示就是数字,栈顶嵌套链表add()加入该单整数版本的NestedInteger;
(4)如果遇到“]”:
①如果str非空,需要将其作为NestInteger通过add()加入栈顶嵌套链表;
②如果栈元素个数多余1,则需要将栈顶元素出栈,新的栈顶元素add()昂刚出栈的栈顶元素,完成嵌套链表合并。
因为例如”[123,456,[788,799,833],[[]],10,[]]”,在833后的第一个”]”就需要先合并两个嵌套,使得栈顶元素降维下一层。
1 | /** |
394. 字符串解码
Description
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
Example
示例 1:
输入:s = “3[a]2[bc]”
输出:”aaabcbc”
示例 2:
输入:s = “3[a2[c]]”
输出:”accaccacc”
示例 3:
输入:s = “2[abc]3[cd]ef”
输出:”abcabccdcdcdef”
示例 4:
输入:s = “abc3[cd]xyz”
输出:”abccdcdcdxyz”
Program
思路
(1)遍历字符串,遇到数字就开始处理该满足编码规则的字符串:
- 先处理数字;
- 后处理[]内的字符串,这里很容易想到递归处理,因为[]内的字符串也是一个有效的字符串,也需要解码!但是需要注意[]内可能有嵌套!
- 重复k次;
(2)输出结果
时间复杂度:$O(N+n)$,N为解码后的字符串长度,n为原字符串长度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Solution {
public:
int sToi(string str){
int ans=0;
for(int i=0;i<str.length();i++){
ans=ans*10+str[i]-'0';
}
return ans;
}
string decodeString(string s) {
int n=s.length();
string res;
for(int i=0;i<n;i++){
if(s[i]>='0'&&s[i]<='9'){
string numStr;
while(s[i]>=0&&s[i]<='9'){ //处理数字
numStr+=s[i];
i++;
}
int start=i; //[坐标
int nBracket=0;
while(i<n){ //处理数字后的第一个[],这里得注意可能有嵌套[],故需要类似栈的判断
if(s[i]=='[') nBracket++;
else if(s[i]==']') nBracket--;
if(nBracket==0) break;
i++;
}
string str=decodeString(s.substr(start+1, i-start-1));//递归
int k=sToi(numStr);
for(int j=0;j<k;j++) res+=str;
}else{
res+=s[i];
}
}
return res;
}
};456. 132模式
Description
给定一个整数序列:a1, a2, …, an,一个132模式的子序列 ai, aj, ak 被定义为:当 i < j < k 时,ai < ak < aj。设计一个算法,当给定有 n 个数字的序列时,验证这个序列中是否含有132模式的子序列。
注意:n 的值小于15000。
Example
示例1:
输入: [1, 2, 3, 4]
输出: False
解释: 序列中不存在132模式的子序列。
示例 2:
输入: [3, 1, 4, 2]
输出: True
解释: 序列中有 1 个132模式的子序列: [1, 4, 2].
示例 3:
输入: [-1, 3, 2, 0]
输出: True
解释: 序列中有 3 个132模式的的子序列: [-1, 3, 2], [-1, 3, 0] 和 [-1, 2, 0].
Program
单调递减栈
(1)维护一个数组minVec,minVec[i]表示在截止到索引i时的当前最小值,因为需要$a_i<a_k<a_j$,贪心的希望a_i越小越好;
(2)对$i<j<k$,需要$a_i<a_k<a_j$,那么考虑位置$j$,将数组分成左右两部分$[0,j-1],[j+1,n-1]$,由(1)可以找到左边小于nums[j]的值,那么只需要判断右边[j+1,n-1]这部分是否存在满足$a_i<a_k<a_j$的$k$。
(3)从左往右遍历不好操作,那么考虑从右往左遍历;
对于$j$,满足$a_i<a_k<a_j$的nums[i]就是minVec[j],即需要满足minVec[j]<nums[j]。那么右边也就是先遍历的部分nums[k]需要满足$minVec[j]<nums[k]<nums[j]$,这些nums[k]就是我们需要维护的部分,假设有这么个数据结构存储这一部分,那么只要找到一个就说明存在132模式,直接返回即可! 否则,即minVec[j]==nums[j](由于minVec的性质,不可能大于),不可能满足直接跳过。
(4)现在考虑如何维护这一部分。
- ①首先这一部分需要尽可能小,但是要先满足$minVec[j]<nums[k]$,不满足直接丢弃不满足此条件的那些nums[k];
- ②然后看是否满足$nums[k]<nums[j]$,如果满足直接返回,否则,即$nums[k]>=nums[j]$,那么nums[j]就是上一步我们所说的尽可能小的部分,需要保留,那么原本维护的nums[k]呢?我们知道从右往左遍历,minVec[j]是递增的,那么当前保留的尽可能小的nums[j]只是满足当前的$minVec[j]<nums[j]<=nums[k]$,对于下一个minVec[j-1]就不一定满足$minVec[j]<nums[j]$了!所以也需要保留满足①的那部分nums[k]。
(5)好了,现在我们知道需要维护相对于j的哪一部分nums[k]了,其实已经基本出来了数据结构了——单调递减栈!
时间复杂度:$O(n)$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
bool find132pattern(vector<int>& nums) {
if(nums.size()==0) return false;
vector<int> minVec;//minVec[i]为截止目前i索引所得最小值
int n=nums.size();
minVec.push_back(nums[0]);
for(int i=1;i<n;i++) minVec.push_back(min(minVec.back(), nums[i]));
stack<int> desSt;//单调递减栈
for(int i=n-1;i>=0;i--){
if(minVec[i]<nums[i]){
while(!desSt.empty()&&minVec[i]>=desSt.top()) desSt.pop();//所有小于等于minVec[i]的都出栈
if(!desSt.empty()&&desSt.top()<nums[i]) return true;
desSt.push(nums[i]);
}
}
return false;
}
};459. 重复的子字符串
Description
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
Example
示例 1:
输入: “abab”
输出: True
解释: 可由子字符串 “ab” 重复两次构成。
示例 2:
输入: “aba”
输出: False
示例 3:
输入: “abcabcabcabc”
输出: True
解释: 可由子字符串 “abc” 重复四次构成。 (或者子字符串 “abcabc” 重复两次构成。)
Program
思路
如果s满足题目要求,那么s至少由其子串重复两次,那么两个s拼接后出去首尾各一个字符,如果该字符串中能够找到s,说明s满足题意。
时间复杂度:$O(mn)$。
- KMP 算法虽然有着良好的理论时间复杂度上限,但大部分语言自带的字符串查找函数并不是用 KMP 算法实现的。这是因为在实现 API 时,我们需要在平均时间复杂度和最坏时间复杂度二者之间权衡。普通的暴力匹配算法以及优化的 BM 算法拥有比 KMP 算法更为优秀的平均时间复杂度;
1
2
3
4
5
6
7
8
9class Solution {
public:
bool repeatedSubstringPattern(string s) {
int n=s.length();
string str=s+s;
str=str.substr(1, 2*n-2);
return str.find(s)!=string::npos;
}
};
KMP
1 | class Solution { |
496. 下一个更大元素 I
Description
给定两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。找到 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
Example
示例 1:
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
对于num1中的数字4,你无法在第二个数组中找到下一个更大的数字,因此输出 -1。
对于num1中的数字1,第二个数组中数字1右边的下一个较大数字是 3。
对于num1中的数字2,第二个数组中没有下一个更大的数字,因此输出 -1。
示例 2:
输入: nums1 = [2,4], nums2 = [1,2,3,4].
输出: [3,-1]
解释:
对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。
对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
提示:
nums1和nums2中所有元素是唯一的。
nums1和nums2 的数组大小都不超过1000。
Program
暴力
时间复杂度:$O(n^2)$
1 | class Solution { |
单调栈
Next Greater Element问题模板。
时间复杂度:$O(m+n)$
1 | class Solution { |
503. 下一个更大元素 II
Description
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
Example
示例 1:
输入: [1,2,1]
输出: [2,-1,2]
解释: 第一个 1 的下一个更大的数是 2;
数字 2 找不到下一个更大的数;
第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
注意: 输入数组的长度不会超过 10000。
Program
1 | class Solution { |
1 | class Solution { |
557. 反转字符串中的单词 III
Description
给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
Example
示例:
输入:”Let’s take LeetCode contest”
输出:”s’teL ekat edoCteeL tsetnoc”
提示:
在字符串中,每个单词由单个空格分隔,并且字符串中不会有任何额外的空格。
Program
1 | class Solution { |
636. 函数的独占时间
Description
给出一个非抢占单线程CPU的 n 个函数运行日志,找到函数的独占时间。
每个函数都有一个唯一的 Id,从 0 到 n-1,函数可能会递归调用或者被其他函数调用。
日志是具有以下格式的字符串:function_id:start_or_end:timestamp。例如:”0:start:0” 表示函数 0 从 0 时刻开始运行。”0🔚0” 表示函数 0 在 0 时刻结束。
函数的独占时间定义是在该方法中花费的时间,调用其他函数花费的时间不算该函数的独占时间。你需要根据函数的 Id 有序地返回每个函数的独占时间。
Example
示例 1:
输入:
n = 2
logs =
[“0:start:0”,
“1:start:2”,
“1🔚5”,
“0🔚6”]
输出:[3, 4]
说明:
函数 0 在时刻 0 开始,在执行了 2个时间单位结束于时刻 1。
现在函数 0 调用函数 1,函数 1 在时刻 2 开始,执行 4 个时间单位后结束于时刻 5。
函数 0 再次在时刻 6 开始执行,并在时刻 6 结束运行,从而执行了 1 个时间单位。
所以函数 0 总共的执行了 2 +1 =3 个时间单位,函数 1 总共执行了 4 个时间单位。
说明:
输入的日志会根据时间戳排序,而不是根据日志Id排序。
你的输出会根据函数Id排序,也就意味着你的输出数组中序号为 0 的元素相当于函数 0 的执行时间。
两个函数不会在同时开始或结束。
函数允许被递归调用,直到运行结束。
1 <= n <= 100
Program
栈
(1)首先,整体思路肯定是栈,遇到start就入栈,遇到end就出栈,计算时间;
(2)关键问题在于同一个id的开始结束之中有其他id(可能与自己相同)的函数,且有可能是顺序的也可能是嵌套的;
(3)形象的用括号表示“[[[[], []]],[],[]]”,其中每一对“[]”表示函数调用开始和结束,例如我们计算最外层的函数所学时间,必须记录其中顺序包含的每个子“[]”所独占时间,最终最外层独占时间是其起始结束之差再减去子函数所占时间,同理,每个子函数所独占时间也是这么算的!
(4)除了栈外,我们需要记录子函数占用时间:用一个结构体记录id,起始时间戳,子函数占用时间。同时用数组记录每次一个函数独占时间
(5)算法过程:
①遇到start入栈;
②遇到end出栈:
- 如果栈非空,刚出栈的调用时间加入栈顶元素的substime中,表示栈顶函数调用了刚刚出栈的函数,需要记录其所占时间(非独占);
- 无论栈空否,刚出栈的函数调用完毕,计算其独占时间:end-start+1-subtime,即自身函数占用时间-其调用子函数调用的时间,将其通过数组进行累加(因为可能会递归调用自身)。
时间复杂度:$O(n)$
1 | class Solution { |
657. 机器人能否返回原点
Description
在二维平面上,有一个机器人从原点 (0, 0) 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 (0, 0) 处结束。
移动顺序由字符串表示。字符 move[i] 表示其第 i 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。如果机器人在完成所有动作后返回原点,则返回 true。否则,返回 false。
注意:机器人“面朝”的方向无关紧要。 “R” 将始终使机器人向右移动一次,“L” 将始终向左移动等。此外,假设每次移动机器人的移动幅度相同。
Example
示例 1:
输入: “UD”
输出: true
解释:机器人向上移动一次,然后向下移动一次。所有动作都具有相同的幅度,因此它最终回到它开始的原点。因此,我们返回 true。
示例 2:
输入: “LL”
输出: false
解释:机器人向左移动两次。它最终位于原点的左侧,距原点有两次 “移动” 的距离。我们返回 false,因为它在移动结束时没有返回原点。
Program
1 | class Solution { |
682. 棒球比赛
Description
你现在是棒球比赛记录员。
给定一个字符串列表,每个字符串可以是以下四种类型之一:
1.整数(一轮的得分):直接表示您在本轮中获得的积分数。
2. “+”(一轮的得分):表示本轮获得的得分是前两轮有效 回合得分的总和。
3. “D”(一轮的得分):表示本轮获得的得分是前一轮有效 回合得分的两倍。
4. “C”(一个操作,这不是一个回合的分数):表示您获得的最后一个有效 回合的分数是无效的,应该被移除。
每一轮的操作都是永久性的,可能会对前一轮和后一轮产生影响。
你需要返回你在所有回合中得分的总和。
Example
示例 1:
输入: [“5”,”2”,”C”,”D”,”+”]
输出: 30
解释:
第1轮:你可以得到5分。总和是:5。
第2轮:你可以得到2分。总和是:7。
操作1:第2轮的数据无效。总和是:5。
第3轮:你可以得到10分(第2轮的数据已被删除)。总数是:15。
第4轮:你可以得到5 + 10 = 15分。总数是:30。
示例 2:
输入: [“5”,”-2”,”4”,”C”,”D”,”9”,”+”,”+”]
输出: 27
解释:
第1轮:你可以得到5分。总和是:5。
第2轮:你可以得到-2分。总数是:3。
第3轮:你可以得到4分。总和是:7。
操作1:第3轮的数据无效。总数是:3。
第4轮:你可以得到-4分(第三轮的数据已被删除)。总和是:-1。
第5轮:你可以得到9分。总数是:8。
第6轮:你可以得到-4 + 9 = 5分。总数是13。
第7轮:你可以得到9 + 5 = 14分。总数是27。
注意:
输入列表的大小将介于1和1000之间。
列表中的每个整数都将介于-30000和30000之间。
Program
1 | class Solution { |
696. 计数二进制子串
Description
给定一个字符串 s,计算具有相同数量0和1的非空(连续)子字符串的数量,并且这些子字符串中的所有0和所有1都是组合在一起的。
重复出现的子串要计算它们出现的次数。
Example
示例 1 :
输入: “00110011”
输出: 6
解释: 有6个子串具有相同数量的连续1和0:“0011”,“01”,“1100”,“10”,“0011” 和 “01”。
请注意,一些重复出现的子串要计算它们出现的次数。
另外,“00110011”不是有效的子串,因为所有的0(和1)没有组合在一起。
示例 2 :
输入: “10101”
输出: 4
解释: 有4个子串:“10”,“01”,“10”,“01”,它们具有相同数量的连续1和0。
注意:
s.length 在1到50,000之间。
s 只包含“0”或“1”字符。
Program
1 | class Solution { |
735. 行星碰撞
Description
给定一个整数数组 asteroids,表示在同一行的行星。
对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。
找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
Example
示例 1:
输入:
asteroids = [5, 10, -5]
输出: [5, 10]
解释:
10 和 -5 碰撞后只剩下 10。 5 和 10 永远不会发生碰撞。
示例 2:
输入:
asteroids = [8, -8]
输出: []
解释:
8 和 -8 碰撞后,两者都发生爆炸。
示例 3:
输入:
asteroids = [10, 2, -5]
输出: [10]
解释:
2 和 -5 发生碰撞后剩下 -5。10 和 -5 发生碰撞后剩下 10。
示例 4:
输入:
asteroids = [-2, -1, 1, 2]
输出: [-2, -1, 1, 2]
解释:
-2 和 -1 向左移动,而 1 和 2 向右移动。
由于移动方向相同的行星不会发生碰撞,所以最终没有行星发生碰撞。
说明:
数组 asteroids 的长度不超过 10000。
每一颗行星的大小都是非零整数,范围是 [-1000, 1000] 。
Program
思路
栈:这里只有左边的球向右移动,右边的球向左移动才会发生碰撞,反之不会发生碰撞。
时间复杂度:$O(n)$,for循环是$O(n)$的,while里在for的整个过程中是$O(n)$的,因为每个元素最多入栈出栈一次。
1 | class Solution { |
739. 每日温度
Description
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
Example
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
Program
1 | class Solution { |
844. 比较含退格的字符串
Description
给定 S 和 T 两个字符串,当它们分别被输入到空白的文本编辑器后,判断二者是否相等,并返回结果。 # 代表退格字符。
注意:如果对空文本输入退格字符,文本继续为空。
Example
示例 1:
输入:S = “ab#c”, T = “ad#c”
输出:true
解释:S 和 T 都会变成 “ac”。
示例 2:
输入:S = “ab##”, T = “c#d#”
输出:true
解释:S 和 T 都会变成 “”。
示例 3:
输入:S = “a##c”, T = “#a#c”
输出:true
解释:S 和 T 都会变成 “c”。
示例 4:
输入:S = “a#c”, T = “b”
输出:false
解释:S 会变成 “c”,但 T 仍然是 “b”。
提示:
1 <= S.length <= 200
1 <= T.length <= 200
S 和 T 只含有小写字母以及字符 ‘#’。
进阶:
你可以用 O(N) 的时间复杂度和 O(1) 的空间复杂度解决该问题吗?
Program
思路
从后往前遍历,遇到’#’则计数,遇到普通字符则判断计数是否为0,否则跳过;
时间复杂度:$O(n)$
空间复杂度:$O(1)$
1 | class Solution { |
856. 括号的分数
Description
给定一个平衡括号字符串 S,按下述规则计算该字符串的分数:
- () 得 1 分。
- AB 得 A + B 分,其中 A 和 B 是平衡括号字符串。
- (A) 得 2 * A 分,其中 A 是平衡括号字符串。
Example
示例 1:
输入: “()”
输出: 1
示例 2:
输入: “(())”
输出: 2
示例 3:
输入: “()()”
输出: 2
示例 4:
输入: “(()(()))”
输出: 6
提示:
S 是平衡括号字符串,且只含有 ( 和 ) 。
2 <= S.length <= 50
Program
栈
维护一个栈,栈内元素表示以该对括号内的分数:
(1)遇到左括号,入栈,初试化括号内的分数为0;
(2)遇到右括号,出栈,出栈前的栈顶元素值为当前一对括号包含的所有子括号的分数,判断该score是否为0:
- score==0,表示当前括号内没有嵌套,应当向上将包含该括号的上一级括号的分数st.top()+1——如果栈为空,则直接最终结果ans+=1;
- score>0,表示当前括号内有嵌套的分数为score,更新栈顶元素(包含当前括号的上一级括号分数)st.top()+2score —— 如果栈为空,则直接最终结果ans+=2score;
时间复杂度:$O(n)$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
int scoreOfParentheses(string S) {
stack<int> st;
int ans=0;
for(int i=0;i<S.length();i++){
if(S[i]=='('){
st.push(0);
}else{
int score=st.top();st.pop();
if(score==0){
if(st.empty()) ans+=1;
else st.top()+=1;
}else{
if(st.empty()) ans+=2*score;
else st.top()+=2*score;
}
}
}
return ans;
}
};880. 索引处的解码字符串
Description
给定一个编码字符串 S。请你找出 解码字符串 并将其写入磁带。解码时,从编码字符串中 每次读取一个字符 ,并采取以下步骤:
- 如果所读的字符是字母,则将该字母写在磁带上。
- 如果所读的字符是数字(例如 d),则整个当前磁带总共会被重复写 d-1 次。
- 现在,对于给定的编码字符串 S 和索引 K,查找并返回解码字符串中的第 K 个字母。
Example
示例 1:
输入:S = “leet2code3”, K = 10
输出:”o”
解释:
解码后的字符串为 “leetleetcodeleetleetcodeleetleetcode”。
字符串中的第 10 个字母是 “o”。
示例 2:
输入:S = “ha22”, K = 5
输出:”h”
解释:
解码后的字符串为 “hahahaha”。第 5 个字母是 “h”。
示例 3:
输入:S = “a2345678999999999999999”, K = 1
输出:”a”
解释:
解码后的字符串为 “a” 重复 8301530446056247680 次。第 1 个字母是 “a”。
提示:
2 <= S.length <= 100
S 只包含小写字母与数字 2 到 9 。
S 以字母开头。
1 <= K <= 10^9
题目保证 K 小于或等于解码字符串的长度。
解码后的字符串保证少于 2^63 个字母。
Program
暴力
超内存!
1 | class Solution { |
规律处理
(1)如果我们有一个像 appleappleappleappleappleapple 这样的解码字符串和一个像 K=24 这样的索引,那么如果 K=4,答案是相同的。
(2)一般来说,当解码的字符串等于某个长度为 size 的单词重复某些次数(例如 apple 与 size=5 组合重复6次)时,索引 K 的答案与索引 K % size 的答案相同。
(3)首先计算解码后字符串长度为size,然后从后往前遍历,遇到数字就size/=S[i]-‘0’,否则遇到字母size–,然后K%size,判断K==0且S[i]为字母,则说明找到解。
例如样例1:”leet2code3”
size=36,k=10
i=9,size=36/3=12,k=10 mod 12=10;
i=8,size=11,k=10
i=7,size=10,k=0
i=6,return;
1 | class Solution { |
901. 股票价格跨度
Description
编写一个 StockSpanner 类,它收集某些股票的每日报价,并返回该股票当日价格的跨度。
今天股票价格的跨度被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
例如,如果未来7天股票的价格是 [100, 80, 60, 70, 60, 75, 85],那么股票跨度将是 [1, 1, 1, 2, 1, 4, 6]。
Example
示例:
输入:[“StockSpanner”,”next”,”next”,”next”,”next”,”next”,”next”,”next”], [[],[100],[80],[60],[70],[60],[75],[85]]
输出:[null,1,1,1,2,1,4,6]
解释:
首先,初始化 S = StockSpanner(),然后:
S.next(100) 被调用并返回 1,
S.next(80) 被调用并返回 1,
S.next(60) 被调用并返回 1,
S.next(70) 被调用并返回 2,
S.next(60) 被调用并返回 1,
S.next(75) 被调用并返回 4,
S.next(85) 被调用并返回 6。
注意 (例如) S.next(75) 返回 4,因为截至今天的最后 4 个价格
(包括今天的价格 75) 小于或等于今天的价格。
提示:
调用 StockSpanner.next(int price) 时,将有 1 <= price <= 10^5。
每个测试用例最多可以调用 10000 次 StockSpanner.next。
在所有测试用例中,最多调用 150000 次 StockSpanner.next。
此问题的总时间限制减少了 50%。
Program
单调栈
乍一看还以为是树状数组题,然后看到最大连续日数。这题还是比较有意思的,没有直接说求左边第一个比当前大的元素!这个转变很关键啊!
这么一看就是求当前到左边比当前大的天数的索引差值!Next Greater Element变成了Pre Greater Element,正向遍历,单调递减栈!时间复杂度:$O(n)$,n为next调用的次数
1 | class StockSpanner { |
907. 子数组的最小值之和
Description
给定一个整数数组 A,找到 min(B) 的总和,其中 B 的范围为 A 的每个(连续)子数组。
由于答案可能很大,因此返回答案模 10^9 + 7。
Example
示例:
输入:[3,1,2,4]
输出:17
解释:
子数组为 [3],[1],[2],[4],[3,1],[1,2],[2,4],[3,1,2],[1,2,4],[3,1,2,4]。
最小值为 3,1,2,4,1,1,2,1,1,1,和为 17。
提示:
1 <= A <= 30000
1 <= A[i] <= 30000
Program
单调栈
以A[i]为最小值,左右最大辐射范围
left[i]记录左边第一个小于A[i]的下标;
right[i]记录右边第一个小于A[i]的下标;
以A[i]为最小值的区间个数为:$(i-left[i]) * (right[i] - i)$
由于存在重复元素,所以需要左右两边其中一个取小于等于。
1 | class Solution { |
1 | class Solution { |
946. 验证栈序列
Description
给定 pushed 和 popped 两个序列,每个序列中的 值都不重复,只有当它们可能是在最初空栈上进行的推入 push 和弹出 pop 操作序列的结果时,返回 true;否则,返回 false 。
Example
示例 1:
输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1]
输出:true
解释:我们可以按以下顺序执行:
push(1), push(2), push(3), push(4), pop() -> 4,
push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1
示例 2:
输入:pushed = [1,2,3,4,5], popped = [4,3,5,1,2]
输出:false
解释:1 不能在 2 之前弹出。
提示:
0 <= pushed.length == popped.length <= 1000
0 <= pushed[i], popped[i] < 1000
pushed 是 popped 的排列。
Program
直接判断栈顶元素是否等于出栈元素,是则继续出栈,否则进栈元素进栈。
时间复杂度:$O(n)$
1 | class Solution { |
1 | class Solution { |
1002. 查找常用字符
Description
给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。
你可以按任意顺序返回答案。
Example
示例 1:
输入:[“bella”,”label”,”roller”]
输出:[“e”,”l”,”l”]
示例 2:
输入:[“cool”,”lock”,”cook”]
输出:[“c”,”o”]
提示:
1 <= A.length <= 100
1 <= A[i].length <= 100
A[i][j] 是小写字母
Program
思路
(1)对每个字符串的26个字母进行计数;
(2)最终结果仅保留各个字符串中对应字母最小的值;
1 | class Solution { |
1003. 检查替换后的词是否有效
Description
给定有效字符串 “abc”。
对于任何有效的字符串 V,我们可以将 V 分成两个部分 X 和 Y,使得 X + Y(X 与 Y 连接)等于 V。(X 或 Y 可以为空。)那么,X + “abc” + Y 也同样是有效的。
例如,如果 S = “abc”,则有效字符串的示例是:”abc”,”aabcbc”,”abcabc”,”abcabcababcc”。无效字符串的示例是:”abccba”,”ab”,”cababc”,”bac”。
如果给定字符串 S 有效,则返回 true;否则,返回 false。
Example
示例 1:
输入:”aabcbc”
输出:true
解释:
从有效字符串 “abc” 开始。
然后我们可以在 “a” 和 “bc” 之间插入另一个 “abc”,产生 “a” + “abc” + “bc”,即 “aabcbc”。
示例 2:
输入:”abcabcababcc”
输出:true
解释:
“abcabcabc” 是有效的,它可以视作在原串后连续插入 “abc”。
然后我们可以在最后一个字母之前插入 “abc”,产生 “abcabcab” + “abc” + “c”,即 “abcabcababcc”。
示例 3:
输入:”abccba”
输出:false
示例 4:
输入:”cababc”
输出:false
提示:
1 <= S.length <= 20000
S[i] 为 ‘a’、’b’、或 ‘c’
Program
1 | class Solution { |
1019. 链表中的下一个更大节点
Description
给出一个以头节点 head 作为第一个节点的链表。链表中的节点分别编号为:node_1, node_2, node_3, … 。
每个节点都可能有下一个更大值(next larger value):对于 node_i,如果其 next_larger(node_i) 是 node_j.val,那么就有 j > i 且 node_j.val > node_i.val,而 j 是可能的选项中最小的那个。如果不存在这样的 j,那么下一个更大值为 0 。
返回整数答案数组 answer,其中 answer[i] = next_larger(node_{i+1}) 。
注意:在下面的示例中,诸如 [2,1,5] 这样的输入(不是输出)是链表的序列化表示,其头节点的值为 2,第二个节点值为 1,第三个节点值为 5 。
Example
示例 1:
输入:[2,1,5]
输出:[5,5,0]
示例 2:
输入:[2,7,4,3,5]
输出:[7,0,5,5,0]
示例 3:
输入:[1,7,5,1,9,2,5,1]
输出:[7,9,9,9,0,5,0,0]
提示:
对于链表中的每个节点,1 <= node.val <= 10^9
给定列表的长度在 [0, 10000] 范围内
Program
单调栈
时间复杂度:$O(n)$
空间复杂度:$O(n)$
1 | /** |
1021. 删除最外层的括号
Description
有效括号字符串为空 (“”)、”(“ + A + “)” 或 A + B,其中 A 和 B 都是有效的括号字符串,+ 代表字符串的连接。例如,””,”()”,”(())()” 和 “(()(()))” 都是有效的括号字符串。
如果有效字符串 S 非空,且不存在将其拆分为 S = A+B 的方法,我们称其为原语(primitive),其中 A 和 B 都是非空有效括号字符串。
给出一个非空有效字符串 S,考虑将其进行原语化分解,使得:S = P_1 + P_2 + … + P_k,其中 P_i 是有效括号字符串原语。
对 S 进行原语化分解,删除分解中每个原语字符串的最外层括号,返回 S 。
Example
示例 1:
输入:”(()())(())”
输出:”()()()”
解释:
输入字符串为 “(()())(())”,原语化分解得到 “(()())” + “(())”,
删除每个部分中的最外层括号后得到 “()()” + “()” = “()()()”。
示例 2:
输入:”(()())(())(()(()))”
输出:”()()()()(())”
解释:
输入字符串为 “(()())(())(()(()))”,原语化分解得到 “(()())” + “(())” + “(()(()))”,
删除每个部分中的最外层括号后得到 “()()” + “()” + “()(())” = “()()()()(())”。
示例 3:
输入:”()()”
输出:””
解释:
输入字符串为 “()()”,原语化分解得到 “()” + “()”,
删除每个部分中的最外层括号后得到 “” + “” = “”。
提示:
S.length <= 10000
S[i] 为 “(“ 或 “)”
S 是一个有效括号字符串
Program
思路
关键在于拆分原语,可以发现左括号与右括号数量相等的时候是一个原语!!
时间复杂度:$O(n)$
1 | class Solution { |
1023. 驼峰式匹配
Description
如果我们可以将小写字母插入模式串 pattern 得到待查询项 query,那么待查询项与给定模式串匹配。(我们可以在任何位置插入每个字符,也可以插入 0 个字符。)
给定待查询列表 queries,和模式串 pattern,返回由布尔值组成的答案列表 answer。只有在待查项 queries[i] 与模式串 pattern 匹配时, answer[i] 才为 true,否则为 false。
Example
示例 1:
输入:queries = [“FooBar”,”FooBarTest”,”FootBall”,”FrameBuffer”,”ForceFeedBack”], pattern = “FB”
输出:[true,false,true,true,false]
示例:
“FooBar” 可以这样生成:”F” + “oo” + “B” + “ar”。
“FootBall” 可以这样生成:”F” + “oot” + “B” + “all”.
“FrameBuffer” 可以这样生成:”F” + “rame” + “B” + “uffer”.
示例 2:
输入:queries = [“FooBar”,”FooBarTest”,”FootBall”,”FrameBuffer”,”ForceFeedBack”], pattern = “FoBa”
输出:[true,false,true,false,false]
解释:
“FooBar” 可以这样生成:”Fo” + “o” + “Ba” + “r”.
“FootBall” 可以这样生成:”Fo” + “ot” + “Ba” + “ll”.
示例 3:
输出:queries = [“FooBar”,”FooBarTest”,”FootBall”,”FrameBuffer”,”ForceFeedBack”], pattern = “FoBaT”
输入:[false,true,false,false,false]
解释:
“FooBarTest” 可以这样生成:”Fo” + “o” + “Ba” + “r” + “T” + “est”.
提示:
1 <= queries.length <= 100
1 <= queries[i].length <= 100
1 <= pattern.length <= 100
所有字符串都仅由大写和小写英文字母组成。
Program
双指针
如果str[i]与pattern[j]匹配,同时后移;
否则,如果str[i]为大写字母,直接返回false:
否则,i后移;
判断pattern是否匹配完,没匹配完,直接返回false;
最后判断str剩余部分是否存在大写字母,如果有直接返回false;
如果没有,则匹配成功,返回true;
1 | class Solution { |
1047. 删除字符串中的所有相邻重复项
Description
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
Example
示例:
输入:”abbaca”
输出:”ca”
解释:
例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。
提示:
1 <= S.length <= 20000
S 仅由小写英文字母组成。
Program
1 | class Solution { |
1081. 不同字符的最小子序列
Description
返回字符串 text 中按字典序排列最小的子序列,该子序列包含 text 中所有不同字符一次。
Example
示例 1:
输入:”cdadabcc”
输出:”adbc”
示例 2:
输入:”abcd”
输出:”abcd”
示例 3:
输入:”ecbacba”
输出:”eacb”
示例 4:
输入:”leetcode”
输出:”letcod”
提示:
1 <= text.length <= 1000
text 由小写英文字母组成
Program
思路
子序列且要求每个字符仅出现一次,子序列要求相对位置不变,可以考虑单调栈,遇到与当前字符大的字符,检查是否可以出栈;
出栈条件:①比当前字符大;②并且该字符在字符串后面还存在
1 | class Solution { |
1124. 表现良好的最长时间段
Description
给你一份工作时间表 hours,上面记录着某一位员工每天的工作小时数。
我们认为当员工一天中的工作小时数大于 8 小时的时候,那么这一天就是「劳累的一天」。
所谓「表现良好的时间段」,意味在这段时间内,「劳累的天数」是严格 大于「不劳累的天数」。
请你返回「表现良好时间段」的最大长度。
Example
示例 1:
输入:hours = [9,9,6,0,6,6,9]
输出:3
解释:最长的表现良好时间段是 [9,9,6]。
提示:
1 <= hours.length <= 10000
0 <= hours[i] <= 16
Program
暴力
首先将hours数组转成1,-1的形式,方便统计,然后计算前缀和,题目要求的就是说要使得[i,j]的和大于0的最长长度。一个直接的思路是暴力枚举,时间复杂度:$O(n^2)$
超时
1 | class Solution { |
单调栈
从暴力的双循环看:
(1)内循环,$i<j_1<j_2$,如果preSum[j_2]>preSum[i],那么$j_1$无意义,所以从后往前遍历j;
(2)外循环:$i<i_1<j$,如果preSum[i_1]>preSum[i],那么$i_1$无意义;
详解
1 | class Solution { |
1190. 反转每对括号间的子串
Description
给出一个字符串 s(仅含有小写英文字母和括号)。
请你按照从括号内到外的顺序,逐层反转每对匹配括号中的字符串,并返回最终的结果。
注意,您的结果中 不应 包含任何括号。
Example
示例 1:
输入:s = “(abcd)”
输出:”dcba”
示例 2:
输入:s = “(u(love)i)”
输出:”iloveu”
示例 3:
输入:s = “(ed(et(oc))el)”
输出:”leetcode”
示例 4:
输入:s = “a(bcdefghijkl(mno)p)q”
输出:”apmnolkjihgfedcbq”
提示:
0 <= s.length <= 2000
s 中只有小写英文字母和括号
我们确保所有括号都是成对出现的
Program
暴力
时间复杂度:$O(n^2)$
1 | class Solution { |
虫洞法
时间复杂度:$O(n)$
1 | class Solution { |
1209. 删除字符串中的所有相邻重复项 II
Description
给你一个字符串 s,「k 倍重复项删除操作」将会从 s 中选择 k 个相邻且相等的字母,并删除它们,使被删去的字符串的左侧和右侧连在一起。
你需要对 s 重复进行无限次这样的删除操作,直到无法继续为止。
在执行完所有删除操作后,返回最终得到的字符串。
本题答案保证唯一。
Example
示例 1:
输入:s = “abcd”, k = 2
输出:”abcd”
解释:没有要删除的内容。
示例 2:
输入:s = “deeedbbcccbdaa”, k = 3
输出:”aa”
解释:
先删除 “eee” 和 “ccc”,得到 “ddbbbdaa”
再删除 “bbb”,得到 “dddaa”
最后删除 “ddd”,得到 “aa”
示例 3:
输入:s = “pbbcggttciiippooaais”, k = 2
输出:”ps”
提示:
1 <= s.length <= 10^5
2 <= k <= 10^4
s 中只含有小写英文字母。
Program
1 | class Solution { |
1249. 移除无效的括号
Description
给你一个由 ‘(‘、’)’ 和小写字母组成的字符串 s。
你需要从字符串中删除最少数目的 ‘(‘ 或者 ‘)’ (可以删除任意位置的括号),使得剩下的「括号字符串」有效。
请返回任意一个合法字符串。
有效「括号字符串」应当符合以下 任意一条 要求:
- 空字符串或只包含小写字母的字符串
- 可以被写作 AB(A 连接 B)的字符串,其中 A 和 B 都是有效「括号字符串」
- 可以被写作 (A) 的字符串,其中 A 是一个有效的「括号字符串」
Example
示例 1:
输入:s = “lee(t(c)o)de)”
输出:”lee(t(c)o)de”
解释:”lee(t(co)de)” , “lee(t(c)ode)” 也是一个可行答案。
示例 2:
输入:s = “a)b(c)d”
输出:”ab(c)d”
示例 3:
输入:s = “))((“
输出:””
解释:空字符串也是有效的
示例 4:
输入:s = “(a(b(c)d)”
输出:”a(b(c)d)”
提示:
1 <= s.length <= 10^5
s[i] 可能是 ‘(‘、’)’ 或英文小写字母
Program
时间复杂度:$O(n)$
1 | class Solution { |
1370. 上升下降字符串
Description
给你一个字符串 s ,请你根据下面的算法重新构造字符串:
从 s 中选出 最小 的字符,将它 接在 结果字符串的后面。
从 s 剩余字符中选出 最小 的字符,且该字符比上一个添加的字符大,将它 接在 结果字符串后面。
重复步骤 2 ,直到你没法从 s 中选择字符。
从 s 中选出 最大 的字符,将它 接在 结果字符串的后面。
从 s 剩余字符中选出 最大 的字符,且该字符比上一个添加的字符小,将它 接在 结果字符串后面。
重复步骤 5 ,直到你没法从 s 中选择字符。
重复步骤 1 到 6 ,直到 s 中所有字符都已经被选过。
在任何一步中,如果最小或者最大字符不止一个 ,你可以选择其中任意一个,并将其添加到结果字符串。
请你返回将 s 中字符重新排序后的 结果字符串 。
Example
示例 1:
输入:s = “aaaabbbbcccc”
输出:”abccbaabccba”
解释:第一轮的步骤 1,2,3 后,结果字符串为 result = “abc”
第一轮的步骤 4,5,6 后,结果字符串为 result = “abccba”
第一轮结束,现在 s = “aabbcc” ,我们再次回到步骤 1
第二轮的步骤 1,2,3 后,结果字符串为 result = “abccbaabc”
第二轮的步骤 4,5,6 后,结果字符串为 result = “abccbaabccba”
示例 2:
输入:s = “rat”
输出:”art”
解释:单词 “rat” 在上述算法重排序以后变成 “art”
示例 3:
输入:s = “leetcode”
输出:”cdelotee”
示例 4:
输入:s = “ggggggg”
输出:”ggggggg”
示例 5:
输入:s = “spo”
输出:”ops”
提示:
1 <= s.length <= 500
s 只包含小写英文字母。
Program
1 | class Solution { |
1381. 设计一个支持增量操作的栈
Description
请你设计一个支持下述操作的栈。
实现自定义栈类 CustomStack :
CustomStack(int maxSize):用 maxSize 初始化对象,maxSize 是栈中最多能容纳的元素数量,栈在增长到 maxSize 之后则不支持 push 操作。
void push(int x):如果栈还未增长到 maxSize ,就将 x 添加到栈顶。
int pop():弹出栈顶元素,并返回栈顶的值,或栈为空时返回 -1 。
void inc(int k, int val):栈底的 k 个元素的值都增加 val 。如果栈中元素总数小于 k ,则栈中的所有元素都增加 val 。
Example
示例:
输入:
[“CustomStack”,”push”,”push”,”pop”,”push”,”push”,”push”,”increment”,”increment”,”pop”,”pop”,”pop”,”pop”]
[[3],[1],[2],[],[2],[3],[4],[5,100],[2,100],[],[],[],[]]
输出:
[null,null,null,2,null,null,null,null,null,103,202,201,-1]
解释:
CustomStack customStack = new CustomStack(3); // 栈是空的 []
customStack.push(1); // 栈变为 [1]
customStack.push(2); // 栈变为 [1, 2]
customStack.pop(); // 返回 2 –> 返回栈顶值 2,栈变为 [1]
customStack.push(2); // 栈变为 [1, 2]
customStack.push(3); // 栈变为 [1, 2, 3]
customStack.push(4); // 栈仍然是 [1, 2, 3],不能添加其他元素使栈大小变为 4
customStack.increment(5, 100); // 栈变为 [101, 102, 103]
customStack.increment(2, 100); // 栈变为 [201, 202, 103]
customStack.pop(); // 返回 103 –> 返回栈顶值 103,栈变为 [201, 202]
customStack.pop(); // 返回 202 –> 返回栈顶值 202,栈变为 [201]
customStack.pop(); // 返回 201 –> 返回栈顶值 201,栈变为 []
customStack.pop(); // 返回 -1 –> 栈为空,返回 -1
提示:
1 <= maxSize <= 1000
1 <= x <= 1000
1 <= k <= 1000
0 <= val <= 100
每种方法 increment,push 以及 pop 分别最多调用 1000 次
Program
1 | class CustomStack { |
1410. HTML 实体解析器
Description
「HTML 实体解析器」 是一种特殊的解析器,它将 HTML 代码作为输入,并用字符本身替换掉所有这些特殊的字符实体。
HTML 里这些特殊字符和它们对应的字符实体包括:
双引号:字符实体为 " ,对应的字符是 “ 。
单引号:字符实体为 ' ,对应的字符是 ‘ 。
与符号:字符实体为 & ,对应对的字符是 & 。
大于号:字符实体为 > ,对应的字符是 > 。
小于号:字符实体为 < ,对应的字符是 < 。
斜线号:字符实体为 ⁄ ,对应的字符是 / 。
给你输入字符串 text ,请你实现一个 HTML 实体解析器,返回解析器解析后的结果。
Example
示例 1:
输入:text = “& is an HTML entity but &ambassador; is not.”
输出:”& is an HTML entity but &ambassador; is not.”
解释:解析器把字符实体 & 用 & 替换
示例 2:
输入:text = “and I quote: "…"”
输出:”and I quote: "…"“
示例 3:
输入:text = “Stay home! Practice on Leetcode :)”
输出:”Stay home! Practice on Leetcode :)”
示例 4:
输入:text = “x > y && x < y is always false”
输出:”x > y && x < y is always false”
示例 5:
输入:text = “leetcode.com⁄problemset⁄all”
输出:”leetcode.com/problemset/all”
提示:
1 <= text.length <= 10^5
字符串可能包含 256 个ASCII 字符中的任意字符。
Program
1 | class Solution { |
1441. 用栈操作构建数组
Description
给你一个目标数组 target 和一个整数 n。每次迭代,需要从 list = {1,2,3…, n} 中依序读取一个数字。
请使用下述操作来构建目标数组 target :
- Push:从 list 中读取一个新元素, 并将其推入数组中。
- Pop:删除数组中的最后一个元素。
- 如果目标数组构建完成,就停止读取更多元素。
题目数据保证目标数组严格递增,并且只包含 1 到 n 之间的数字。
请返回构建目标数组所用的操作序列。
题目数据保证答案是唯一的。
Example
示例 1:
输入:target = [1,3], n = 3
输出:[“Push”,”Push”,”Pop”,”Push”]
解释:
读取 1 并自动推入数组 -> [1]
读取 2 并自动推入数组,然后删除它 -> [1]
读取 3 并自动推入数组 -> [1,3]
示例 2:
输入:target = [1,2,3], n = 3
输出:[“Push”,”Push”,”Push”]
示例 3:
输入:target = [1,2], n = 4
输出:[“Push”,”Push”]
解释:只需要读取前 2 个数字就可以停止。
示例 4:
输入:target = [2,3,4], n = 4
输出:[“Push”,”Pop”,”Push”,”Push”,”Push”]
提示:
1 <= target.length <= 100
1 <= target[i] <= 100
1 <= n <= 100
target 是严格递增的
Program
1 | class Solution { |
1544. 整理字符串
Description
给你一个由大小写英文字母组成的字符串 s 。
一个整理好的字符串中,两个相邻字符 s[i] 和 s[i + 1] 不会同时满足下述条件:
0 <= i <= s.length - 2
s[i] 是小写字符,但 s[i + 1] 是相同的大写字符;反之亦然 。
请你将字符串整理好,每次你都可以从字符串中选出满足上述条件的 两个相邻 字符并删除,直到字符串整理好为止。
请返回整理好的 字符串 。题目保证在给出的约束条件下,测试样例对应的答案是唯一的。
注意:空字符串也属于整理好的字符串,尽管其中没有任何字符。
Example
示例 1:
输入:s = “leEeetcode”
输出:”leetcode”
解释:无论你第一次选的是 i = 1 还是 i = 2,都会使 “leEeetcode” 缩减为 “leetcode” 。
示例 2:
输入:s = “abBAcC”
输出:””
解释:存在多种不同情况,但所有的情况都会导致相同的结果。例如:
“abBAcC” –> “aAcC” –> “cC” –> “”
“abBAcC” –> “abBA” –> “aA” –> “”
示例 3:
输入:s = “s”
输出:”s”
提示:
1 <= s.length <= 100
s 只包含小写和大写英文字母
Program
1 | class Solution { |
剑指 Offer 30. 包含min函数的栈
Description
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
Example
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.min(); –> 返回 -3.
minStack.pop();
minStack.top(); –> 返回 0.
minStack.min(); –> 返回 -2.
提示:
各函数的调用总次数不超过 20000 次
Program
1 | class MinStack { |
面试题 03.02. 栈的最小值
Description
请设计一个栈,除了常规栈支持的pop与push函数以外,还支持min函数,该函数返回栈元素中的最小值。执行push、pop和min操作的时间复杂度必须为O(1)。
Example
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); –> 返回 -3.
minStack.pop();
minStack.top(); –> 返回 0.
minStack.getMin(); –> 返回 -2.
Program
1 | class MinStack { |
面试题 03.04. 化栈为队
Description
实现一个MyQueue类,该类用两个栈来实现一个队列。
Example
示例:
MyQueue queue = new MyQueue();
queue.push(1);
queue.push(2);
queue.peek(); // 返回 1
queue.pop(); // 返回 1
queue.empty(); // 返回 false
说明:
你只能使用标准的栈操作 – 也就是只有 push to top, peek/pop from top, size 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
Program
1 | class MyQueue { |
面试题 17.17. 多次搜索
Description
给定一个较长字符串big和一个包含较短字符串的数组smalls,设计一个方法,根据smalls中的每一个较短字符串,对big进行搜索。输出smalls中的字符串在big里出现的所有位置positions,其中positions[i]为smalls[i]出现的所有位置。
Example
示例:
输入:
big = “mississippi”
smalls = [“is”,”ppi”,”hi”,”sis”,”i”,”ssippi”]
输出: [[1,4],[8],[],[3],[1,4,7,10],[5]]
提示:
0 <= len(big) <= 1000
0 <= len(smalls[i]) <= 1000
smalls的总字符数不会超过 100000。
你可以认为smalls中没有重复字符串。
所有出现的字符均为英文小写字母。
Program
1 | **1、KMP** |
2、AC自动机
1 | class Solution { |
树
树的序列化
652. 寻找重复的子树
Description
给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
两棵树重复是指它们具有相同的结构以及相同的结点值。
Example
示例 1:
1 | 1 |
下面是两个重复的子树:
1 | 2 |
和
4
因此,你需要以列表的形式返回上述重复子树的根结点。
Program
思路
将每个子树序列化后,用哈希表判断是否重复,如果重复,加入结果即可,注意分隔符,否则将不能准确区分不同子树的情况
1 | /** |
树的操作
114. 二叉树展开为链表
Description
给定一个二叉树,原地将它展开为链表。
Example
例如,给定二叉树
1 | 1 |
将其展开为:
1 | 1 |
Program
前序遍历,自顶而下
1 | /** |
后序遍历,自底而上
1 | /** |
前两种时间复杂度$O(n)$,空间复杂度:$O(n)$,栈相关!
现在使用前驱的方法,使得空间复杂度降为$O(1)$.
其中每个节点最多额外访问一次,所以时间复杂度还是$O(n)$
1 | /** |
99. 恢复二叉搜索树
Description
二叉搜索树中的两个节点被错误地交换。
请在不改变其结构的情况下,恢复这棵树。
Example
示例 1:
输入: [1,3,null,null,2]
1 | 1 |
3
/
1
2
1 | 示例 2: |
3
/
1 4
/
2
1 | 输出: [2,1,4,null,null,3] |
2
/
1 4
/
3
1 | 进阶: |
Mirros遍历
先找到左子树前驱,如果前驱右孩子为空则,置为root,否则置为空,其他与上一个一致
1 | * Definition for a binary tree node. |
98. 验证二叉搜索树
Description
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
Example
示例 1:
输入:
2
/
1 3
输出: true
示例 2:
输入:
5
/
1 4
/
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。
Program
1 | /** |
105. 从前序与中序遍历序列构造二叉树
Description
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
Example
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
1 | 3 |
Program
1 | /** |
106. 从中序与后序遍历序列构造二叉树
Description
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
Example
例如,给出
中序遍历 inorder = [9,3,15,20,7]
后序遍历 postorder = [9,15,7,20,3]
返回如下的二叉树:
1 | 3 |
Program
1 | /** |
109. 有序链表转换二叉搜索树
Description
给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
Example
示例:
给定的有序链表: [-10, -3, 0, 5, 9],
一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树:
1 | 0 |
Program
1 | /** |
113. 路径总和 II
Description
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
Example
示例:
给定如下二叉树,以及目标和 sum = 22,
1 | 5 |
返回:
1 | [ |
Program
1 | /** |
116. 填充每个节点的下一个右侧节点指针
Description
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
1 | struct Node { |
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
Example
1 | 输入:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":null,"right":null,"val":4},"next":null,"right":{"$id":"4","left":null,"next":null,"right":null,"val":5},"val":2},"next":null,"right":{"$id":"5","left":{"$id":"6","left":null,"next":null,"right":null,"val":6},"next":null,"right":{"$id":"7","left":null,"next":null,"right":null,"val":7},"val":3},"val":1} |
Program
1 | /* |
117. 填充每个节点的下一个右侧节点指针 II
Description
给定一个二叉树
1 | struct Node { |
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
进阶:
你只能使用常量级额外空间。
使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
Example
示例:
Program
1 | /* |
129. 求根到叶子节点数字之和
Description
给定一个二叉树,它的每个结点都存放一个 0-9 的数字,每条从根到叶子节点的路径都代表一个数字。
例如,从根到叶子节点路径 1->2->3 代表数字 123。
计算从根到叶子节点生成的所有数字之和。
说明: 叶子节点是指没有子节点的节点。
Example
示例 1:
输入: [1,2,3]
1 | 1 |
输出: 25
解释:
从根到叶子节点路径 1->2 代表数字 12.
从根到叶子节点路径 1->3 代表数字 13.
因此,数字总和 = 12 + 13 = 25.
示例 2:
输入: [4,9,0,5,1]
1 | 4 |
输出: 1026
解释:
从根到叶子节点路径 4->9->5 代表数字 495.
从根到叶子节点路径 4->9->1 代表数字 491.
从根到叶子节点路径 4->0 代表数字 40.
因此,数字总和 = 495 + 491 + 40 = 1026.
Progam
1 | /** |
133. 克隆图
Description
给定无向连通图中一个节点的引用,返回该图的深拷贝(克隆)。图中的每个节点都包含它的值 val(Int) 和其邻居的列表(list[Node])。
Example
示例:
1 | 输入: |
提示:
节点数介于 1 到 100 之间。
无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
必须将给定节点的拷贝作为对克隆图的引用返回。
Program
1 | /* |
199. 二叉树的右视图
Description
给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
Example
示例:
输入: [1,2,3,null,5,null,4]
输出: [1, 3, 4]
解释:
1 | 1 <--- |
Program
1 | /** |
235. 二叉搜索树的最近公共祖先
Description
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
Example
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
所有节点的值都是唯一的。
p、q 为不同节点且均存在于给定的二叉搜索树中。
Program
1 | /** |
236. 二叉树的最近公共祖先
Description
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
Example
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
说明:
所有节点的值都是唯一的。
p、q 为不同节点且均存在于给定的二叉树中。
Program
思路
root为p,q的最近公共祖先:
1.p,q分别在root的左右子树上;
2.root=p,q在root的子树上;
3.root=q,p在root的子树上;
后序遍历:
先判断左右子树是否包含p或q,不分别包含p和q的话,比较2,3即可。
1 | /** |
257. 二叉树的所有路径
Description
给定一个二叉树,返回所有从根节点到叶子节点的路径。
说明: 叶子节点是指没有子节点的节点。
Example
示例:
输入:
1 | 1 |
输出: [“1->2->5”, “1->3”]
解释: 所有根节点到叶子节点的路径为: 1->2->5, 1->3
Program
1 | /** |
437. 路径总和 III
Description
给定一个二叉树,它的每个结点都存放着一个整数值。
找出路径和等于给定数值的路径总数。
路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
二叉树不超过1000个节点,且节点数值范围是 [-1000000,1000000] 的整数。
Example
示例:
root = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8
1 | 10 |
返回 3。和等于 8 的路径有:
- 5 -> 3
- 5 -> 2 -> 1
- -3 -> 11
Program
思路
(1)pathSum(root, sum)是以root为根的二叉树路径和为sum的个数,则:
pathSum(root, sum)=pathSum(root->left, sum)+pathSum(root->right, sum)?
还漏了一种情况,因为pathSum仅仅以root为根,而路径不一定以root为起点,所以这里漏了以root为起点的路径的情况:
pathSum(root, sum)=pathSum(root->left, sum)+pathSum(root->right, sum)+calPath(root, sum);
其中calPath(root, sum)为以root为起点的路径和为sum的路径数!
(2)所以有两个递归过程,一个是以root作为根的递归,一个是以root作为路径起点的递归;
(3)calPath(root,sum)中找到和为sum时,ans+1,还需要继续向下递归,因为可以类似于[1,2,-1,4],sum=3这种情况,以1位起点可以有两条路径。
1 | /** |
508. 出现次数最多的子树元素和
Description
给你一个二叉树的根结点,请你找出出现次数最多的子树元素和。一个结点的「子树元素和」定义为以该结点为根的二叉树上所有结点的元素之和(包括结点本身)。
你需要返回出现次数最多的子树元素和。如果有多个元素出现的次数相同,返回所有出现次数最多的子树元素和(不限顺序)。
Example
示例 1:
输入:
1 | 5 |
返回 [2, -3, 4],所有的值均只出现一次,以任意顺序返回所有值。
示例 2:
输入:
1 | 5 |
返回 [2],只有 2 出现两次,-5 只出现 1 次。
提示: 假设任意子树元素和均可以用 32 位有符号整数表示。
Program
1 | /** |
572. 另一个树的子树
Description
给定两个非空二叉树 s 和 t,检验 s 中是否包含和 t 具有相同结构和节点值的子树。s 的一个子树包括 s 的一个节点和这个节点的所有子孙。s 也可以看做它自身的一棵子树。
Example
示例 1:
给定的树 s:
1 | 3 |
给定的树 t:
1 | 4 |
返回 true,因为 t 与 s 的一个子树拥有相同的结构和节点值。
示例 2:
给定的树 s:
1 | 3 |
给定的树 t:
1 | 4 |
返回 false。
Program
思路
(1)比较当前root是否一致,一致则判断各自左右子树是否相等;
(2)即isSubtree(s, t) || isSubtree(s->left, t) ||isSubtree(s->right, t)
这里有问题,即每次第一个isSubtree(s, t)不相等的时候,后面都会进行左右子树比较,存在大量重复,解决方法是比较当前root为根的子树与t是否一致,与左右子树比较分开。
1 | /** |
1 | /** |
530. 二叉搜索树的最小绝对差
Description
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
Example
示例:
输入:
1 | 1 |
输出:
1
解释:
最小绝对差为 1,其中 2 和 1 的差的绝对值为 1(或者 2 和 3)。
提示:
树中至少有 2 个节点。
Program
1 | /** |
538. 把二叉搜索树转换为累加树
Description
给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和。
Example
例如:
输入: 原始二叉搜索树:
1 | 5 |
输出: 转换为累加树:
1 | 18 |
Program
1 | /** |
543. 二叉树的直径
Description
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
Example
示例 :
给定二叉树
1 | 1 |
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
注意:两结点之间的路径长度是以它们之间边的数目表示。
Program
1 | /** |
563. 二叉树的坡度
Description
给定一个二叉树,计算整个树的坡度。
一个树的节点的坡度定义即为,该节点左子树的结点之和和右子树结点之和的差的绝对值。空结点的的坡度是0。
整个树的坡度就是其所有节点的坡度之和。
Example
示例:
输入:
1 | 1 |
输出:1
解释:
结点 2 的坡度: 0
结点 3 的坡度: 0
结点 1 的坡度: |2-3| = 1
树的坡度 : 0 + 0 + 1 = 1
提示:
任何子树的结点的和不会超过 32 位整数的范围。
坡度的值不会超过 32 位整数的范围。
Program
1 | /** |
617. 合并二叉树
Description
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
Example
示例 1:
输入:
1 | Tree 1 Tree 2 |
3
/ \
4 5
/ \ \
5 4 71 | 注意: 合并必须从两个树的根节点开始。 |
655. 输出二叉树
Description
在一个 mn 的二维字符串数组中输出二叉树,并遵守以下规则:
行数 m 应当等于给定二叉树的高度。
列数 n 应当总是奇数。
根节点的值(以字符串格式给出)应当放在可放置的第一行正中间。根节点所在的行与列会将剩余空间划分为两部分(左下部分和右下部分)。你应该将左子树输出在左下部分,右子树输出在右下部分。左下和右下部分应当有相同的大小。即使一个子树为空而另一个非空,你不需要为空的子树输出任何东西,但仍需要为另一个子树留出足够的空间。然而,如果两个子树都为空则不需要为它们留出任何空间。
每个未使用的空间应包含一个空的字符串””。
使用相同的规则输出子树。
*Example**
示例 1:
输入:
1 | 1 |
输出:
[[“”, “1”, “”],
[“2”, “”, “”]]
示例 2:
输入:
1 | 1 |
输出:
[[“”, “”, “”, “1”, “”, “”, “”],
[“”, “2”, “”, “”, “”, “3”, “”],
[“”, “”, “4”, “”, “”, “”, “”]]
示例 3:
输入:
1 | 1 |
输出:
[[“”, “”, “”, “”, “”, “”, “”, “1”, “”, “”, “”, “”, “”, “”, “”]
[“”, “”, “”, “2”, “”, “”, “”, “”, “”, “”, “”, “5”, “”, “”, “”]
[“”, “3”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”]
[“4”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”, “”]]
注意: 二叉树的高度在范围 [1, 10] 中。
Program
1 | /** |
662. 二叉树最大宽度
Description
给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。
Example
示例 1:
输入:
1 | 1 |
输出: 4
解释: 最大值出现在树的第 3 层,宽度为 4 (5,3,null,9)。
示例 2:
输入:
1 | 1 |
输出: 2
解释: 最大值出现在树的第 3 层,宽度为 2 (5,3)。
示例 3:
输入:
1 | 1 |
输出: 2
解释: 最大值出现在树的第 2 层,宽度为 2 (3,2)。
示例 4:
输入:
1 | 1 |
输出: 8
解释: 最大值出现在树的第 4 层,宽度为 8 (6,null,null,null,null,null,null,7)。
注意: 答案在32位有符号整数的表示范围内。
Program
思路
(1)通过满二叉树的性质,子节点索引分别为$idx_{father}2+1,idx_{father}}2+2$,来对非空节点进行编码;
(2)由于二叉树的层数阅读,编码为2的指数倍,容易越界,故可以考虑同一层同时减去本层最小的索引来进行编码数值的压缩,而不会影响宽度(索引差值)的结果!
时间复杂度:$O(n)$
1 | /** |
894. 所有可能的满二叉树
Description
满二叉树是一类二叉树,其中每个结点恰好有 0 或 2 个子结点。
返回包含 N 个结点的所有可能满二叉树的列表。 答案的每个元素都是一个可能树的根结点。
答案中每个树的每个结点都必须有 node.val=0。
你可以按任何顺序返回树的最终列表。
Example
示例:
输入:7
输出:[[0,0,0,null,null,0,0,null,null,0,0],[0,0,0,null,null,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,null,null,null,null,0,0],[0,0,0,0,0,null,null,0,0]]
解释:
提示:
1 <= N <= 20
Program
递归
根结点1
左子树节点数为0, 1, 3, 5, i
右子树节点数为N-1-i, 1, 0
1 | /** |
919. 完全二叉树插入器
Description
完全二叉树是每一层(除最后一层外)都是完全填充(即,节点数达到最大)的,并且所有的节点都尽可能地集中在左侧。
设计一个用完全二叉树初始化的数据结构 CBTInserter,它支持以下几种操作:
- CBTInserter(TreeNode root) 使用头节点为 root 的给定树初始化该数据结构;
- CBTInserter.insert(int v) 向树中插入一个新节点,节点类型为 TreeNode,值为 v 。使树保持完全二叉树的状态,并返回插入的新节点的父节点的值;
- CBTInserter.get_root() 将返回树的头节点。
Example
示例 1:
输入:inputs = [“CBTInserter”,”insert”,”get_root”], inputs = [[[1]],[2],[]]
输出:[null,1,[1,2]]
示例 2:
输入:inputs = [“CBTInserter”,”insert”,”insert”,”get_root”], inputs = [[[1,2,3,4,5,6]],[7],[8],[]]
输出:[null,3,4,[1,2,3,4,5,6,7,8]]
提示:
最初给定的树是完全二叉树,且包含 1 到 1000 个节点。
每个测试用例最多调用 CBTInserter.insert 操作 10000 次。
给定节点或插入节点的每个值都在 0 到 5000 之间。
Program
思路
维护一个双端队列,保存孩子为0或1的节点,插入时,插入队列头结点即可,如果头结点孩子满了,出队,同时注意插入的节点孩子为0,也需要入队。
1 | /** |
968. 监控二叉树
Description
给定一个二叉树,我们在树的节点上安装摄像头。
节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
计算监控树的所有节点所需的最小摄像头数量。
Example
示例 1:
输入:[0,0,null,0,0]
输出:1
解释:如图所示,一台摄像头足以监控所有节点。
示例 2:
输入:[0,0,null,0,null,0,null,null,0]
输出:2
解释:需要至少两个摄像头来监视树的所有节点。 上图显示了摄像头放置的有效位置之一。
提示:
给定树的节点数的范围是 [1, 1000]。
每个节点的值都是 0。
Program
1 | /** |
979. 在二叉树中分配硬币
Description
给定一个有 N 个结点的二叉树的根结点 root,树中的每个结点上都对应有 node.val 枚硬币,并且总共有 N 枚硬币。
在一次移动中,我们可以选择两个相邻的结点,然后将一枚硬币从其中一个结点移动到另一个结点。(移动可以是从父结点到子结点,或者从子结点移动到父结点。)。
返回使每个结点上只有一枚硬币所需的移动次数。
Example
示例 1:
输入:[3,0,0]
输出:2
解释:从树的根结点开始,我们将一枚硬币移到它的左子结点上,一枚硬币移到它的右子结点上。
示例 2:
输入:[0,3,0]
输出:3
解释:从根结点的左子结点开始,我们将两枚硬币移到根结点上 [移动两次]。然后,我们把一枚硬币从根结点移到右子结点上。
示例 3:
输入:[1,0,2]
输出:2
示例 4:
输入:[1,0,0,null,3]
输出:4
提示:
1<= N <= 100
0 <= node.val <= N
Program
1 | /** |
987. 二叉树的垂序遍历
Description
给定二叉树,按垂序遍历返回其结点值。
对位于 (X, Y) 的每个结点而言,其左右子结点分别位于 (X-1, Y-1) 和 (X+1, Y-1)。
把一条垂线从 X = -infinity 移动到 X = +infinity ,每当该垂线与结点接触时,我们按从上到下的顺序报告结点的值( Y 坐标递减)。
如果两个结点位置相同,则首先报告的结点值较小。
按 X 坐标顺序返回非空报告的列表。每个报告都有一个结点值列表。
Example
示例 1:
输入:[3,9,20,null,null,15,7]
输出:[[9],[3,15],[20],[7]]
解释:
在不丧失其普遍性的情况下,我们可以假设根结点位于 (0, 0):
然后,值为 9 的结点出现在 (-1, -1);
值为 3 和 15 的两个结点分别出现在 (0, 0) 和 (0, -2);
值为 20 的结点出现在 (1, -1);
值为 7 的结点出现在 (2, -2)。
示例 2:
输入:[1,2,3,4,5,6,7]
输出:[[4],[2],[1,5,6],[3],[7]]
解释:
根据给定的方案,值为 5 和 6 的两个结点出现在同一位置。
然而,在报告 “[1,5,6]” 中,结点值 5 排在前面,因为 5 小于 6。
提示:
树的结点数介于 1 和 1000 之间。
每个结点值介于 0 和 1000 之间。
Program
思路
(1)给每个节点坐标化;
(2)先按照x增序排列,在根据y轴降序排列,最后根据val升序排列;
1 | /** |
1008. 前序遍历构造二叉搜索树
Description
返回与给定前序遍历 preorder 相匹配的二叉搜索树(binary search tree)的根结点。
(回想一下,二叉搜索树是二叉树的一种,其每个节点都满足以下规则,对于 node.left 的任何后代,值总 < node.val,而 node.right 的任何后代,值总 > node.val。此外,前序遍历首先显示节点 node 的值,然后遍历 node.left,接着遍历 node.right。)
题目保证,对于给定的测试用例,总能找到满足要求的二叉搜索树。
Example
示例:
输入:[8,5,1,7,10,12]
输出:[8,5,10,1,7,null,12]
提示:
1 <= preorder.length <= 100
1 <= preorder[i] <= 10^8
preorder 中的值互不相同
Program
1 | /** |
1104. 二叉树寻路
Description
在一棵无限的二叉树上,每个节点都有两个子节点,树中的节点 逐行 依次按 “之” 字形进行标记。
如下图所示,在奇数行(即,第一行、第三行、第五行……)中,按从左到右的顺序进行标记;
而偶数行(即,第二行、第四行、第六行……)中,按从右到左的顺序进行标记。
给你树上某一个节点的标号 label,请你返回从根节点到该标号为 label 节点的路径,该路径是由途经的节点标号所组成的。
Example
示例 1:
输入:label = 14
输出:[1,3,4,14]
示例 2:
输入:label = 26
输出:[1,2,6,10,26]
提示:
$1 <= label <= 10^6$
Program
思路
(1)正常顺序下的父节点编码为子节点编码$\frac{label}{2}$;
(2)可以发现规律每层头尾节点的值$left+right=father_label + label/2$
即$father_label = left+right-label/2=2^{h-1}+2^{h}-1-label/2=3 * 2^{h-1}-1-label/2$;
1 | class Solution { |
1261. 在受污染的二叉树中查找元素
Description
给出一个满足下述规则的二叉树:
root.val == 0
如果 treeNode.val == x 且 treeNode.left != null,那么 treeNode.left.val == 2 * x + 1
如果 treeNode.val == x 且 treeNode.right != null,那么 treeNode.right.val == 2 * x + 2
现在这个二叉树受到「污染」,所有的 treeNode.val 都变成了 -1。
请你先还原二叉树,然后实现 FindElements 类:
FindElements(TreeNode* root) 用受污染的二叉树初始化对象,你需要先把它还原。
bool find(int target) 判断目标值 target 是否存在于还原后的二叉树中并返回结果。
Example
示例 1:
输入:
[“FindElements”,”find”,”find”]
[[[-1,null,-1]],[1],[2]]
输出:
[null,false,true]
解释:
FindElements findElements = new FindElements([-1,null,-1]);
findElements.find(1); // return False
findElements.find(2); // return True
示例 2:
输入:
[“FindElements”,”find”,”find”,”find”]
[[[-1,-1,-1,-1,-1]],[1],[3],[5]]
输出:
[null,true,true,false]
解释:
FindElements findElements = new FindElements([-1,-1,-1,-1,-1]);
findElements.find(1); // return True
findElements.find(3); // return True
findElements.find(5); // return False
示例 3:
输入:
[“FindElements”,”find”,”find”,”find”,”find”]
[[[-1,null,-1,-1,null,-1]],[2],[3],[4],[5]]
输出:
[null,true,false,false,true]
解释:
FindElements findElements = new FindElements([-1,null,-1,-1,null,-1]);
findElements.find(2); // return True
findElements.find(3); // return False
findElements.find(4); // return False
findElements.find(5); // return True
提示:
TreeNode.val == -1
二叉树的高度不超过 20
节点的总数在 $[1, 10^4]$ 之间
调用 find() 的总次数在 $[1, 10^4]$ 之间
$0 <= target <= 10^6$
Program
1 | /** |
1 | /** |
1530. 好叶子节点对的数量
Description
给你二叉树的根节点 root 和一个整数 distance 。
如果二叉树中两个 叶 节点之间的 最短路径长度 小于或者等于 distance ,那它们就可以构成一组 好叶子节点对 。
返回树中 好叶子节点对的数量 。
Example
示例 1:
输入:root = [1,2,3,null,4], distance = 3
输出:1
解释:树的叶节点是 3 和 4 ,它们之间的最短路径的长度是 3 。这是唯一的好叶子节点对。
示例 2:
输入:root = [1,2,3,4,5,6,7], distance = 3
输出:2
解释:好叶子节点对为 [4,5] 和 [6,7] ,最短路径长度都是 2 。但是叶子节点对 [4,6] 不满足要求,因为它们之间的最短路径长度为 4 。
示例 3:
输入:root = [7,1,4,6,null,5,3,null,null,null,null,null,2], distance = 3
输出:1
解释:唯一的好叶子节点对是 [2,5] 。
示例 4:
输入:root = [100], distance = 1
输出:0
示例 5:
输入:root = [1,1,1], distance = 2
输出:1
提示:
tree 的节点数在 [1, 2^10] 范围内。
每个节点的值都在 [1, 100] 之间。
1 <= distance <= 10
Program
思路
详见官方题解
(1)一个自然的思路是需要记录叶子结点到以每个节点为根的距离,这里可以简化,因为题目只需要小于等于distance的好节点,所以对于每个节点为根来说,只需要记录距离小于等于distance的叶子结点个数即可,即$dist[i],0<=i<=distance$;
(2)其次,对于以每个节点为根的好节点个数来说,由两部分组成:
一个是leftDist[i]*rightDist[j],其中i+j+2<=distance;
另一个则是leftCount+rightCount;(leftCount, rightCount分别为以左右孩子为根的好节点对个数)
可以知道这个以节点为根的好节点对个数,即以该节点为最近公共祖先!
1 | /** |
剑指 Offer 68 - II. 二叉树的最近公共祖先
Description
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
Example
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
说明:
所有节点的值都是唯一的。
p、q 为不同节点且均存在于给定的二叉树中。
Program
1 | /** |
树遍历
94. 二叉树的中序遍历
Description
给定一个二叉树,返回它的中序 遍历。
Example
示例:
输入: [1,null,2,3]
1 | 1 |
输出: [1,3,2]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
Program
1 | /** |
144. 二叉树的前序遍历
Description
给定一个二叉树,返回它的 前序 遍历。
Example
示例:
输入: [1,null,2,3]
1 | 1 |
输出: [1,2,3]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
Program
1 | /** |
1 | /** |
145. 二叉树的后序遍历
Description
给定一个二叉树,返回它的 后序 遍历。
Example
示例:
输入: [1,null,2,3]
1 | 1 |
输出: [3,2,1]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
Program
1 | /** |
222. 完全二叉树的节点个数
Description
给出一个完全二叉树,求出该树的节点个数。
说明:
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
Example
示例:
输入:
1 | 1 |
输出: 6
Program
1 | /** |
501. 二叉搜索树中的众数
Description
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
假定 BST 有如下定义:
结点左子树中所含结点的值小于等于当前结点的值
结点右子树中所含结点的值大于等于当前结点的值
左子树和右子树都是二叉搜索树
Example
例如:
给定 BST [1,null,2,2],
1 | 1 |
返回[2].
提示:如果众数超过1个,不需考虑输出顺序
进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
Program
1 | /** |
637. 二叉树的层平均值
Description
给定一个非空二叉树, 返回一个由每层节点平均值组成的数组。
Example
示例 1:
输入:
1 | 3 |
输出:[3, 14.5, 11]
解释:
第 0 层的平均值是 3 , 第1层是 14.5 , 第2层是 11 。因此返回 [3, 14.5, 11] 。
提示:
节点值的范围在32位有符号整数范围内。
Program
1 | /** |
1022. 从根到叶的二进制数之和
Description
给出一棵二叉树,其上每个结点的值都是 0 或 1 。每一条从根到叶的路径都代表一个从最高有效位开始的二进制数。例如,如果路径为 0 -> 1 -> 1 -> 0 -> 1,那么它表示二进制数 01101,也就是 13 。
对树上的每一片叶子,我们都要找出从根到该叶子的路径所表示的数字。
返回这些数字之和。题目数据保证答案是一个 32 位 整数。
Example
示例 1:
输入:root = [1,0,1,0,1,0,1]
输出:22
解释:(100) + (101) + (110) + (111) = 4 + 5 + 6 + 7 = 22
示例 2:
输入:root = [0]
输出:0
示例 3:
输入:root = [1]
输出:1
示例 4:
输入:root = [1,1]
输出:3
提示:
树中的结点数介于 1 和 1000 之间。
Node.val 为 0 或 1 。
Program
1 | /** |
树计数
230. 二叉搜索树中第K小的元素
Description
给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素。
说明:
你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数。
Example
示例 1:
输入: root = [3,1,4,null,2], k = 1
1 | 3 |
输出: 1
示例 2:
输入: root = [5,3,6,2,4,null,null,1], k = 3
1 | 5 |
输出: 3
进阶:
如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化 kthSmallest 函数?
Program
栈遍历
时间复杂度:$O(H+K)$
1 | /** |
404. 左叶子之和
Description
计算给定二叉树的所有左叶子之和。
Example
示例:
1 | 3 |
在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
Program
1 | /** |
二分查找
线性二分
33. 搜索旋转排序数组
Description
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
你的算法时间复杂度必须是 O(log n) 级别。
Example
示例 1:
输入: nums = [4,5,6,7,0,1,2], target = 0
输出: 4
示例 2:
输入: nums = [4,5,6,7,0,1,2], target = 3
输出: -1
Program
思路
首先,题目要求时间复杂度必须是$O(\log{n})$,则肯定要用二分查找,但是一般二分查找需要有序,那么现在这种不分有序可以吗?可以!
设left,mid,right分别为当前搜索左、中、右索引:
按照一般二分思路:
(1)如果nums[mid]==target,则返回mid,找到元素;
(2)如果[left,mid-1]有序:
①如果target在此范围内,则在左半部分查找;
②如果target不在此范围内,则在右半部分查找,此时有可能变成原问题(与递归很像);
(3)如果[mid+1,right]有序:
①如果target在此范围内,则在右半部分查找;
②否则,在左半部分查找,此时有可能原问题
1 | class Solution { |
34. 在排序数组中查找元素的第一个和最后一个位置
Description
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
你的算法时间复杂度必须是 O(log n) 级别。
如果数组中不存在目标值,返回 [-1, -1]。
Example
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: [3,4]
示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: [-1,-1]
Program
思路
题目就是找比target小的第一个位置,以及比target大的第一个位置
注意边界!!!!搞死人!
时间复杂度:$O(\log{n})$
1 | class Solution { |
35. 搜索插入位置
Description
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
你可以假设数组中无重复元素。
Example
示例 1:
输入: [1,3,5,6], 5
输出: 2
示例 2:
输入: [1,3,5,6], 2
输出: 1
示例 3:
输入: [1,3,5,6], 7
输出: 4
示例 4:
输入: [1,3,5,6], 0
输出: 0
Program
1 | class Solution { |
69. x 的平方根
Description
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
Example
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842…,
由于返回类型是整数,小数部分将被舍去。
Program
注意二分法,left+right+1防止死循环
1 | class Solution { |
81. 搜索旋转排序数组 II
Description
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。
Example
示例 1:
输入: nums = [2,5,6,0,0,1,2], target = 0
输出: true
示例 2:
输入: nums = [2,5,6,0,0,1,2], target = 3
输出: false
进阶:
这是 搜索旋转排序数组 的延伸题目,本题中的 nums 可能包含重复元素。
这会影响到程序的时间复杂度吗?会有怎样的影响,为什么?
Program
由于无法根据nums[left]<=nums[mid]判断哪边直接有序,因为譬如[1,0,0,1,1,1,1],target=0,但是如果nums[left]==nums[mid],只要target!=nums[mid],直接left++,相当于化为子问题[0,0,1,1,1]进行查找。
最差时间复杂度:$O(n)$,例如[1,1,1,1,0],target=0
1 | class Solution { |
153. 寻找旋转排序数组中的最小值
Description
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。
Example
示例 1:
输入: [3,4,5,1,2]
输出: 1
示例 2:
输入: [4,5,6,7,0,1,2]
输出: 0
Program
思路
还是之前旋转排序树组的思路,不同的是,这里需要记录minValue,
(1)当左半部分有序,minValue肯定在nums[left]或右半部分产生,left=mid+1;
(2)当右半部分有序,minvalue肯定在nums[mid]或左半部分产生,right=mid-1;
(3)判断left<=right,又回到了子问题!
时间复杂度:$O(\log{n})$
1 | class Solution { |
162. 寻找峰值
Description
峰值元素是指其值大于左右相邻值的元素。
给定一个输入数组 nums,其中 nums[i] ≠ nums[i+1],找到峰值元素并返回其索引。
数组可能包含多个峰值,在这种情况下,返回任何一个峰值所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞。
Example
示例 1:
输入: nums = [1,2,3,1]
输出: 2
解释: 3 是峰值元素,你的函数应该返回其索引 2。
示例 2:
输入: nums = [1,2,1,3,5,6,4]
输出: 1 或 5
解释: 你的函数可以返回索引 1,其峰值元素为 2;
或者返回索引 5, 其峰值元素为 6。
说明:
你的解法应该是 $O(\log{N})$ 时间复杂度的。
Program
递归二分查找
也可以说是分治。
设left,right分别是数组左右端点下标,mid=(left+right)/2:
(1)判断mid是否满足峰值,如果是直接返回;
(2)否则,判断子问题(left,mid)以及(mid,right)是否有满足题意的峰值,或运算;
(3)边界:
- left==right,即数组只有一个元素,先判断是否满足峰值,若满足,返回true,否则返回false!
- right-left=1,即数组只有两个元素,由于mid=(left+right)/2,所以mid一定是奇数时的中点位置或者偶数时中间偏左的位置:若mid满足,则返回true;否则判断子问题(left,mid)以及(mid+1,right)——不能判断(mid,right)因为会死循环!
当然,找到峰值时,当然要记录峰值位置了,找到一个即可,或运算的前者如果为true,后面就不会计算了~1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
int res;
int n;
bool findPeak(vector<int>& nums, int left, int right){
int mid=left+(right-left)/2;
if((mid-1<0||nums[mid]>nums[mid-1])&&(mid+1>=n||nums[mid]>nums[mid+1])){
res=mid;
return true;
}
if(left==right) return false; //只有一个元素的时候,先检查
if(right-left==1) return findPeak(nums, left, mid) || findPeak(nums, mid+1, right); //只有两个元素的时候
return findPeak(nums, left, mid) || findPeak(nums, mid, right);
}
int findPeakElement(vector<int>& nums) {
n=nums.size();
findPeak(nums, 0, n-1);
return res;
}
};270. 最接近的二叉搜索树值
Description
给定一个不为空的二叉搜索树和一个目标值 target,请在该二叉搜索树中找到最接近目标值 target 的数值。
注意:
给定的目标值 target 是一个浮点数
题目保证在该二叉搜索树中只会存在一个最接近目标值的数
Example
示例:
输入: root = [4,2,5,1,3],目标值 target = 3.714286
1 | 4 |
输出: 4
Program
遍历
时间复杂度:$O(n)$
1 | /** |
二分
时间复杂度:$O(H)$
根据root->Val与target的比较选择左右子树。
1 | /** |
274. H 指数
Description
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数 不超过 h 次。)
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
Example
1 | class Solution { |
示例:
输入:citations = [3,0,6,1,5]
输出:3
解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
提示:如果 h 有多种可能的值,h 指数是其中最大的那个。
275. H指数 II
Description
给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列。编写一个方法,计算出研究者的 h 指数。
h 指数的定义: “h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数不多于 h 次。)”
Example
示例:
输入: citations = [0,1,3,5,6]
输出: 3
解释: 给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6 次。
由于研究者有 3 篇论文每篇至少被引用了 3 次,其余两篇论文每篇被引用不多于 3 次,所以她的 h 指数是 3。
说明:
如果 h 有多有种可能的值 ,h 指数是其中最大的那个。
进阶:
这是 H指数 的延伸题目,本题中的 citations 数组是保证有序的。
你可以优化你的算法到对数时间复杂度吗?
Program
二分查找
如果citations[mid]>=n-mid,则H=n-mid是一个可能的解,这里需要H尽可能大,所以mid要尽可能靠左。
时间复杂度:$O(\log{n})$
1 | class Solution { |
278. 第一个错误的版本
Description
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, …, n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
Example
示例:
给定 n = 5,并且 version = 4 是第一个错误的版本。
调用 isBadVersion(3) -> false
调用 isBadVersion(5) -> true
调用 isBadVersion(4) -> true
所以,4 是第一个错误的版本。
Program
1 | // The API isBadVersion is defined for you. |
287. 寻找重复数
Description
给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
Example
示例 1:
输入: [1,3,4,2,2]
输出: 2
示例 2:
输入: [3,1,3,4,2]
输出: 3
说明:
不能更改原数组(假设数组是只读的)。
只能使用额外的 $O(1)$ 的空间。
时间复杂度小于 $O(n^2)$ 。
数组中只有一个重复的数字,但它可能不止重复出现一次。
Program
从[1,n]进行二分判断那个数为重复数,left=1,right=n,计算数组中小于等于mid的个数cnt:
- 如果cnt小于等于mid,则[1,mid]范围内不存在重复数;
- 如果cnt严格大于mid,则[1,mid]必定存在重复数;
因为n+1个元素的数组,其中只有一个数target重复至少一次,那么对于数组中原本大于等于target的数x,数组中小于等于x的个数一定大于x。因为如果不存在重复小于等于x的数的个数严格小于等于x
时间复杂度:$O(n\log{n})$
空间复杂度:$O(1)$
1 | class Solution { |
374. 猜数字大小
Description
我们正在玩一个猜数字游戏。 游戏规则如下:
我从 1 到 n 选择一个数字。 你需要猜我选择了哪个数字。
每次你猜错了,我会告诉你这个数字是大了还是小了。
你调用一个预先定义好的接口 guess(int num),它会返回 3 个可能的结果(-1,1 或 0):
1 | -1 : 我的数字比较小 |
Example
示例 :
输入: n = 10, pick = 6
输出: 6
Program
1 | /** |
436. 寻找右区间
Description
给定一组区间,对于每一个区间 i,检查是否存在一个区间 j,它的起始点大于或等于区间 i 的终点,这可以称为 j 在 i 的“右侧”。
对于任何区间,你需要存储的满足条件的区间 j 的最小索引,这意味着区间 j 有最小的起始点可以使其成为“右侧”区间。如果区间 j 不存在,则将区间 i 存储为 -1。最后,你需要输出一个值为存储的区间值的数组。
注意:
- 你可以假设区间的终点总是大于它的起始点。
- 你可以假定这些区间都不具有相同的起始点
Example
示例 1:
输入: [ [1,2] ]
输出: [-1]
解释:集合中只有一个区间,所以输出-1。
示例 2:
输入: [ [3,4], [2,3], [1,2] ]
输出: [-1, 0, 1]
解释:对于[3,4],没有满足条件的“右侧”区间。
对于[2,3],区间[3,4]具有最小的“右”起点;
对于[1,2],区间[2,3]具有最小的“右”起点。
示例 3:
输入: [ [1,4], [2,3], [3,4] ]
输出: [-1, 2, -1]
解释:对于区间[1,4]和[3,4],没有满足条件的“右侧”区间。
对于[2,3],区间[3,4]有最小的“右”起点。
Program
吐槽题干,最小索引个屁!
1 | class Solution { |
475. 供暖器
Description
冬季已经来临。 你的任务是设计一个有固定加热半径的供暖器向所有房屋供暖。
现在,给出位于一条水平线上的房屋和供暖器的位置,找到可以覆盖所有房屋的最小加热半径。
所以,你的输入将会是房屋和供暖器的位置。你将输出供暖器的最小加热半径。
说明:
- 给出的房屋和供暖器的数目是非负数且不会超过 25000。
- 给出的房屋和供暖器的位置均是非负数且不会超过10^9。
- 只要房屋位于供暖器的半径内(包括在边缘上),它就可以得到供暖。
- 所有供暖器都遵循你的半径标准,加热的半径也一样。
Example
示例 1:
输入: [1,2,3],[2]
输出: 1
解释: 仅在位置2上有一个供暖器。如果我们将加热半径设为1,那么所有房屋就都能得到供暖。
示例 2:
输入: [1,2,3,4],[1,4]
输出: 1
解释: 在位置1, 4上有两个供暖器。我们需要将加热半径设为1,这样所有房屋就都能得到供暖。
Program
利用二分寻找每个hosue最近的两个热水器位置,取其最小距离作为其最小半径,而所有house的最小半径的最大值即为所求!
1 | class Solution { |
528. 按权重随机选择
Description
给定一个正整数数组 w ,其中 w[i] 代表位置 i 的权重,请写一个函数 pickIndex ,它可以随机地获取位置 i,选取位置 i 的概率与 w[i] 成正比。
例如,给定一个值 [1,9] 的输入列表,当我们从中选择一个数字时,很有可能 10 次中有 9 次应该选择数字 9 作为答案。
Example
示例 1:
输入:
[“Solution”,”pickIndex”]
[[[1]],[]]
输出:[null,0]
示例 2:
输入:
[“Solution”,”pickIndex”,”pickIndex”,”pickIndex”,”pickIndex”,”pickIndex”]
[[[1,3]],[],[],[],[],[]]
输出:[null,0,1,1,1,0]
输入语法说明:
输入是两个列表:调用成员函数名和调用的参数。Solution 的构造函数有一个参数,即数组 w。pickIndex 没有参数。输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
提示:
1 <= w.length <= 10000
1 <= w[i] <= 10^5
pickIndex 将被调用不超过 10000 次
Program
思路,由于选择位置i的概率与权重w[i]成正比,所以设基础概率为p,可知$p\sum_{i=0}^{n-1}W[i]=1},所以$p_i=w[i]/\sum_{j=0}^{n-1}w[j]$。
一般使用均匀分布,那么类似画条线,根据权重落在一段区间内表示选择位置i,例如[1,2,3],则在[1,6]范围内,[1],[2,3],[4,5,6]分别为三个位置的概率区间,根据二分查找找到去第几个区间即可。
时间复杂度:$O(n)$,pickIndex的复杂度$O(\log{n})$
1 | class Solution { |
658. 找到 K 个最接近的元素
Description
给定一个排序好的数组,两个整数 k 和 x,从数组中找到最靠近 x(两数之差最小)的 k 个数。返回的结果必须要是按升序排好的。如果有两个数与 x 的差值一样,优先选择数值较小的那个数。
Example
示例 1:
输入: [1,2,3,4,5], k=4, x=3
输出: [1,2,3,4]
示例 2:
输入: [1,2,3,4,5], k=4, x=-1
输出: [1,2,3,4]
说明:
k 的值为正数,且总是小于给定排序数组的长度。
数组不为空,且长度不超过 104
数组里的每个元素与 x 的绝对值不超过 104
Program
一般思路
对每个元素与x求绝对值,对绝对值排序,选出前k个数就是答案,时间复杂度:$O(n\log{n})$
二分查找
(1)先找到数组中与目标值绝对值最小的元素,这里使用二分查找第一个不小于目标值的元素,当然有可能找的值偏大,需要与其左边一个数比较(如果存在);
(2)然后从绝对值最小的元素位置开始向两边扩展!
时间复杂度:$(\log{n} + k)$
1 | class Solution { |
704. 二分查找
Description
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
Example
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
提示:
你可以假设 nums 中的所有元素是不重复的。
n 将在 [1, 10000]之间。
nums 的每个元素都将在 [-9999, 9999]之间。
Program
1 | class Solution { |
744. 寻找比目标字母大的最小字母
Description
给你一个排序后的字符列表 letters ,列表中只包含小写英文字母。另给出一个目标字母 target,请你寻找在这一有序列表里比目标字母大的最小字母。
在比较时,字母是依序循环出现的。举个例子:
如果目标字母 target = ‘z’ 并且字符列表为 letters = [‘a’, ‘b’],则答案返回 ‘a’
Example
示例:
输入:
letters = [“c”, “f”, “j”]
target = “a”
输出: “c”
输入:
letters = [“c”, “f”, “j”]
target = “c”
输出: “f”
输入:
letters = [“c”, “f”, “j”]
target = “d”
输出: “f”
输入:
letters = [“c”, “f”, “j”]
target = “g”
输出: “j”
输入:
letters = [“c”, “f”, “j”]
target = “j”
输出: “c”
输入:
letters = [“c”, “f”, “j”]
target = “k”
输出: “c”
提示:
letters长度范围在[2, 10000]区间内。
letters 仅由小写字母组成,最少包含两个不同的字母。
目标字母target 是一个小写字母。
Program
1 | class Solution { |
826. 安排工作以达到最大收益
Description
有一些工作:difficulty[i] 表示第 i 个工作的难度,profit[i] 表示第 i 个工作的收益。
现在我们有一些工人。worker[i] 是第 i 个工人的能力,即该工人只能完成难度小于等于 worker[i] 的工作。
每一个工人都最多只能安排一个工作,但是一个工作可以完成多次。
举个例子,如果 3 个工人都尝试完成一份报酬为 1 的同样工作,那么总收益为 $3。如果一个工人不能完成任何工作,他的收益为 $0 。
我们能得到的最大收益是多少?
Example
示例:
输入: difficulty = [2,4,6,8,10], profit = [10,20,30,40,50], worker = [4,5,6,7]
输出: 100
解释: 工人被分配的工作难度是 [4,4,6,6] ,分别获得 [20,20,30,30] 的收益。
提示:
$1 <= difficulty.length = profit.length <= 10000$
$1 <= worker.length <= 10000$
$difficulty[i], profit[i], worker[i]$ 的范围是 $[1, 10^5]$
Program
排序+二分
(1)首先,按照任务难度升序;
(2)二分找到可胜任的尽可能大的难度的任务;
(3)而(2)中找到的未必是利润最大的任务,因为有可能难度小的任务利润更大,那么需要预处理,即找到前缀最大利润,即[0,j]这j+1个任务中的最大利润best[j];
时间复杂度:$O(n\log{n})$
1 | class Solution { |
852. 山脉数组的峰顶索引
Description
我们把符合下列属性的数组 A 称作山脉:
$A.length >= 3$
存在 $0 < i < A.length - 1$ 使得$A[0] < A[1] < … A[i-1] < A[i] > A[i+1] > … > A[A.length - 1]$
给定一个确定为山脉的数组,返回任何满足 $A[0] < A[1] < … A[i-1] < A[i] > A[i+1] > … > A[A.length - 1]$ 的 $i$ 的值。
Example
示例 1:
输入:[0,1,0]
输出:1
示例 2:
输入:[0,2,1,0]
输出:1
提示:
3 <= A.length <= 10000
0 <= A[i] <= 10^6
A 是如上定义的山脉
Program
1 | class Solution { |
875. 爱吃香蕉的珂珂
Description
珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
Example
示例 1:
输入: piles = [3,6,7,11], H = 8
输出: 4
示例 2:
输入: piles = [30,11,23,4,20], H = 5
输出: 30
示例 3:
输入: piles = [30,11,23,4,20], H = 6
输出: 23
提示:
1 <= piles.length <= 10^4
piles.length <= H <= 10^9
1 <= piles[i] <= 10^9
Program
对K进行二分,时间复杂度:$O(n\log(K))$ 其中n为piles最大长度,K为piles[i]最大值
1 | class Solution { |
911. 在线选举
Description
在选举中,第 i 张票是在时间为 times[i] 时投给 persons[i] 的。
现在,我们想要实现下面的查询函数: TopVotedCandidate.q(int t) 将返回在 t 时刻主导选举的候选人的编号。
在 t 时刻投出的选票也将被计入我们的查询之中。在平局的情况下,最近获得投票的候选人将会获胜。
Example
示例:
输入:[“TopVotedCandidate”,”q”,”q”,”q”,”q”,”q”,”q”], [[[0,1,1,0,0,1,0],[0,5,10,15,20,25,30]],[3],[12],[25],[15],[24],[8]]
输出:[null,0,1,1,0,0,1]
解释:
时间为 3,票数分布情况是 [0],编号为 0 的候选人领先。
时间为 12,票数分布情况是 [0,1,1],编号为 1 的候选人领先。
时间为 25,票数分布情况是 [0,1,1,0,0,1],编号为 1 的候选人领先(因为最近的投票结果是平局)。
在时间 15、24 和 8 处继续执行 3 个查询。
提示:
1 <= persons.length = times.length <= 5000
0 <= persons[i] <= persons.length
times 是严格递增的数组,所有元素都在 [0, 10^9] 范围中。
每个测试用例最多调用 10000 次 TopVotedCandidate.q。
TopVotedCandidate.q(int t) 被调用时总是满足 t >= times[0]。
Program
思路
(1)预处理:先计算每个时刻对应索引下的领先候选人
(2)二分查找:查找times序列下不大于t的最大索引!
1 | class TopVotedCandidate { |
1011. 在 D 天内送达包裹的能力
Description
传送带上的包裹必须在 D 天内从一个港口运送到另一个港口。
传送带上的第 i 个包裹的重量为 weights[i]。每一天,我们都会按给出重量的顺序往传送带上装载包裹。我们装载的重量不会超过船的最大运载重量。
返回能在 D 天内将传送带上的所有包裹送达的船的最低运载能力。
Example
示例 1:
输入:weights = [1,2,3,4,5,6,7,8,9,10], D = 5
输出:15
解释:
船舶最低载重 15 就能够在 5 天内送达所有包裹,如下所示:
第 1 天:1, 2, 3, 4, 5
第 2 天:6, 7
第 3 天:8
第 4 天:9
第 5 天:10
请注意,货物必须按照给定的顺序装运,因此使用载重能力为 14 的船舶并将包装分成 (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) 是不允许的。
示例 2:
输入:weights = [3,2,2,4,1,4], D = 3
输出:6
解释:
船舶最低载重 6 就能够在 3 天内送达所有包裹,如下所示:
第 1 天:3, 2
第 2 天:2, 4
第 3 天:1, 4
示例 3:
输入:weights = [1,2,3,1,1], D = 4
输出:3
解释:
第 1 天:1
第 2 天:2
第 3 天:3
第 4 天:1, 1
提示:
1 <= D <= weights.length <= 50000
1 <= weights[i] <= 500
Program
1 | class Solution { |
1150. 检查一个数是否在数组中占绝大多数
Description
给出一个按 非递减 顺序排列的数组 nums,和一个目标数值 target。假如数组 nums 中绝大多数元素的数值都等于 target,则返回 True,否则请返回 False。
所谓占绝大多数,是指在长度为 N 的数组中出现必须 超过 N/2 次。
Example
示例 1:
输入:nums = [2,4,5,5,5,5,5,6,6], target = 5
输出:true
解释:
数字 5 出现了 5 次,而数组的长度为 9。
所以,5 在数组中占绝大多数,因为 5 次 > 9/2。
示例 2:
输入:nums = [10,100,101,101], target = 101
输出:false
解释:
数字 101 出现了 2 次,而数组的长度是 4。
所以,101 不是 数组占绝大多数的元素,因为 2 次 = 4/2。
提示:
1 <= nums.length <= 1000
1 <= nums[i] <= 10^9
1 <= target <= 10^9
Program
二分
由于本题有序,而不是无序,无序的做法是计数加减,不再赘述,时间复杂度$O(n)$,
而有序,则可以用二分找第一个target的位置以及题目要求超过N/2次,故第一个位置到此之后的N/2次如果都为target肯定true,否则false,注意边界以及target不存在即可。
1 | class Solution { |
1064. 不动点
Description
给定已经按升序排列、由不同整数组成的数组 A,返回满足 A[i] == i 的最小索引 i。如果不存在这样的 i,返回 -1。
Example
示例 1:
输入:[-10,-5,0,3,7]
输出:3
解释:
对于给定的数组,A[0] = -10,A[1] = -5,A[2] = 0,A[3] = 3,因此输出为 3 。
示例 2:
输入:[0,2,5,8,17]
输出:0
示例:
A[0] = 0,因此输出为 0 。
示例 3:
输入:[-10,-5,3,4,7,9]
输出:-1
解释:
不存在这样的 i 满足 A[i] = i,因此输出为 -1 。
提示:
1 <= A.length < 10^4
-10^9 <= A[i] <= 10^9
Program
1 | class Solution { |
1283. 使结果不超过阈值的最小除数
Description
给你一个整数数组 nums 和一个正整数 threshold ,你需要选择一个正整数作为除数,然后将数组里每个数都除以它,并对除法结果求和。
请你找出能够使上述结果小于等于阈值 threshold 的除数中 最小 的那个。
每个数除以除数后都向上取整,比方说 7/3 = 3 , 10/2 = 5 。
题目保证一定有解。
Example
示例 1:
输入:nums = [1,2,5,9], threshold = 6
输出:5
解释:如果除数为 1 ,我们可以得到和为 17 (1+2+5+9)。
如果除数为 4 ,我们可以得到和为 7 (1+1+2+3) 。如果除数为 5 ,和为 5 (1+1+1+2)。
示例 2:
输入:nums = [2,3,5,7,11], threshold = 11
输出:3
示例 3:
输入:nums = [19], threshold = 5
输出:4
提示:
1 <= nums.length <= 5 * 10^4
1 <= nums[i] <= 10^6
nums.length <= threshold <= 10^6
Program
1 | class Solution { |
1300. 转变数组后最接近目标值的数组和
Description
给你一个整数数组 arr 和一个目标值 target ,请你返回一个整数 value ,使得将数组中所有大于 value 的值变成 value 后,数组的和最接近 target (最接近表示两者之差的绝对值最小)。
如果有多种使得和最接近 target 的方案,请你返回这些整数中的最小值。
请注意,答案不一定是 arr 中的数字。
Example
示例 1:
输入:arr = [4,9,3], target = 10
输出:3
解释:当选择 value 为 3 时,数组会变成 [3, 3, 3],和为 9 ,这是最接近 target 的方案。
示例 2:
输入:arr = [2,3,5], target = 10
输出:5
示例 3:
输入:arr = [60864,25176,27249,21296,20204], target = 56803
输出:11361
提示:
1 <= arr.length <= 10^4
1 <= arr[i], target <= 10^5
Program
排序+前缀和+二分
时间复杂度:$O((N+C)\log{N})$
1 | class Solution { |
排序+前缀和+双重二分
时间复杂度:$O(C\log{N})$
1 | class Solution { |
1351. 统计有序矩阵中的负数
Description
给你一个 m * n 的矩阵 grid,矩阵中的元素无论是按行还是按列,都以非递增顺序排列。
请你统计并返回 grid 中 负数 的数目。
Example
示例 1:
输入:grid = [[4,3,2,-1],[3,2,1,-1],[1,1,-1,-2],[-1,-1,-2,-3]]
输出:8
解释:矩阵中共有 8 个负数。
示例 2:
输入:grid = [[3,2],[1,0]]
输出:0
示例 3:
输入:grid = [[1,-1],[-1,-1]]
输出:3
示例 4:
输入:grid = [[-1]]
输出:1
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 100
-100 <= grid[i][j] <= 100
Program
时间复杂度:$O(n\log{n})$
1 | class Solution { |
1482. 制作 m 束花所需的最少天数
Description
给你一个整数数组 bloomDay,以及两个整数 m 和 k 。
现需要制作 m 束花。制作花束时,需要使用花园中 相邻的 k 朵花 。
花园中有 n 朵花,第 i 朵花会在 bloomDay[i] 时盛开,恰好 可以用于 一束 花中。
请你返回从花园中摘 m 束花需要等待的最少的天数。如果不能摘到 m 束花则返回 -1 。
Example
示例 1:
输入:bloomDay = [1,10,3,10,2], m = 3, k = 1
输出:3
解释:让我们一起观察这三天的花开过程,x 表示花开,而 _ 表示花还未开。
现在需要制作 3 束花,每束只需要 1 朵。
1 天后:[x, _, _, _, _] // 只能制作 1 束花
2 天后:[x, _, _, _, x] // 只能制作 2 束花
3 天后:[x, _, x, _, x] // 可以制作 3 束花,答案为 3
示例 2:
输入:bloomDay = [1,10,3,10,2], m = 3, k = 2
输出:-1
解释:要制作 3 束花,每束需要 2 朵花,也就是一共需要 6 朵花。而花园中只有 5 朵花,无法满足制作要求,返回 -1 。
示例 3:
输入:bloomDay = [7,7,7,7,12,7,7], m = 2, k = 3
输出:12
解释:要制作 2 束花,每束需要 3 朵。
花园在 7 天后和 12 天后的情况如下:
7 天后:[x, x, x, x, _, x, x]
可以用前 3 朵盛开的花制作第一束花。但不能使用后 3 朵盛开的花,因为它们不相邻。
12 天后:[x, x, x, x, x, x, x]
显然,我们可以用不同的方式制作两束花。
示例 4:
输入:bloomDay = [1000000000,1000000000], m = 1, k = 1
输出:1000000000
解释:需要等 1000000000 天才能采到花来制作花束
示例 5:
输入:bloomDay = [1,10,2,9,3,8,4,7,5,6], m = 4, k = 2
输出:9
提示:
bloomDay.length == n
1 <= n <= 10^5
1 <= bloomDay[i] <= 10^9
1 <= m <= 10^6
1 <= k <= n
Program
二分查找
对最终天数进行二分即可,isPass判断mid天内是否能够组成m个花束!
时间复杂度:$O(n\log{C})$,$n$为数组长度,$C$为天数的范围
1 | class Solution { |
5643. 将数组分成三个子数组的方案数
Description
我们称一个分割整数数组的方案是 好的 ,当它满足:
数组被分成三个 非空 连续子数组,从左至右分别命名为 left , mid , right 。
left 中元素和小于等于 mid 中元素和,mid 中元素和小于等于 right 中元素和。
给你一个 非负 整数数组 nums ,请你返回 好的 分割 nums 方案数目。由于答案可能会很大,请你将结果对 109 + 7 取余后返回。
Example
示例 1:
输入:nums = [1,1,1]
输出:1
解释:唯一一种好的分割方案是将 nums 分成 [1] [1] [1] 。
示例 2:
输入:nums = [1,2,2,2,5,0]
输出:3
解释:nums 总共有 3 种好的分割方案:
[1] [2] [2,2,5,0]
[1] [2,2] [2,5,0]
[1,2] [2,2] [5,0]
示例 3:
输入:nums = [3,2,1]
输出:0
解释:没有好的分割方案。
提示:
3 <= nums.length <= 105
0 <= nums[i] <= 104
program
思路
(1)控制mid数组的左边界j;
(2)二分查找mid数组的右边界i的范围!注意边界~
时间复杂度:$O(n\log{n})$
1 | class Solution { |
5644. 得到子序列的最少操作次数
Description
给你一个数组 target ,包含若干 互不相同 的整数,以及另一个整数数组 arr ,arr 可能 包含重复元素。
每一次操作中,你可以在 arr 的任意位置插入任一整数。比方说,如果 arr = [1,4,1,2] ,那么你可以在中间添加 3 得到 [1,4,3,1,2] 。你可以在数组最开始或最后面添加整数。
请你返回 最少 操作次数,使得 target 成为 arr 的一个子序列。
一个数组的 子序列 指的是删除原数组的某些元素(可能一个元素都不删除),同时不改变其余元素的相对顺序得到的数组。比方说,[2,7,4] 是 [4,2,3,7,2,1,4] 的子序列(加粗元素),但 [2,4,2] 不是子序列。
Example
示例 1:
输入:target = [5,1,3], arr = [9,4,2,3,4]
输出:2
解释:你可以添加 5 和 1 ,使得 arr 变为 [5,9,4,1,2,3,4] ,target 为 arr 的子序列。
示例 2:
输入:target = [6,4,8,1,3,2], arr = [4,7,6,2,3,8,6,1]
输出:3
提示:
$1 <= target.length, arr.length <= 10^5$
$1 <= target[i], arr[i] <= 10^9$
target 不包含任何重复元素。
Program
方法:最长上升子序列
设target的长度为 N。
回顾题意,假设我们需要添加 xx 个整数,那么就需要 arr 中提供额外的 N-xN−x 个整数,且这 N-xN−x 个整数在 arr 中出现的顺序应该与 target 中的顺序相同。
为了使得 xx 最小,我们需要让 N-xN−x 尽可能大,也就是找出 rr 中,满足「顺序相同」性质的最长子序列。
那么怎么构造出「顺序相同」的最长子序列呢?
显然,如果把arr 中所有的整数,按照其在 target 中的位置「重新标号」,那么一个「顺序相同」的子序列,就等于「重新标号」后的一个上升子序列。而「顺序相同」的最长子序列,就等于「重新标号」后的最长上升子序列。
到此,解法已经呼之欲出了,只剩下最后一个细节:对于那些不在 target 中的数要怎么「标号」呢?实际上,这部分数字对于结果没有任何影响,因此在「标号」的过程中,直接剔除它们即可。
时间复杂度:$O(\log{n})$
1 | class Solution { |
面试题 10.03. 搜索旋转数组
Description
搜索旋转数组。给定一个排序后的数组,包含n个整数,但这个数组已被旋转过很多次了,次数不详。请编写代码找出数组中的某个元素,假设数组元素原先是按升序排列的。若有多个相同元素,返回索引值最小的一个。
Example
示例1:
输入: arr = [15, 16, 19, 20, 25, 1, 3, 4, 5, 7, 10, 14], target = 5
输出: 8(元素5在该数组中的索引)
示例2:
输入:arr = [15, 16, 19, 20, 25, 1, 3, 4, 5, 7, 10, 14], target = 11
输出:-1 (没有找到)
提示:
arr 长度范围在[1, 1000000]之间
Program
1 | class Solution { |
剑指 Offer 11. 旋转数组的最小数字
Description
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
Example
示例 1:
输入:[3,4,5,1,2]
输出:1
示例 2:
输入:[2,2,2,0,1]
输出:0
Program
二分查找
与搜索旋转排序数组 II类似,即存在重复元素,那么如果number[left]==number[mid],无法判断应当从哪个位置开始二分,这个时候left++,即重新成为原问题!
平均时间复杂度:$O(\log{n})$,最差时间复杂度:$O(n)$,即所有元素相等
1 | class Solution { |
剑指 Offer 53 - I. 在排序数组中查找数字 I
Description
统计一个数字在排序数组中出现的次数。
Example
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2
示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: 0
限制:
0 <= 数组长度 <= 50000
Progam
1 | class Solution { |
剑指 Offer 53 - II. 0~n-1中缺失的数字
Description
一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
Example
示例 1:
输入: [0,1,3]
输出: 2
示例 2:
输入: [0,1,2,3,4,5,6,7,9]
输出: 8
限制:
1 <= 数组长度 <= 10000
Program
二分
话不多说上二分找到下标与元素对应的最右端的元素即可,注意边界!时间复杂度$O(n)$
1 | class Solution { |
位运算
位运算的话时间复杂度$O(n)$,思路就是先遍历0~n所有数异或,然后遍历数组元素进行异或,利用两个相同的数异或为0的性质,本题某个数不存在,最后就会被异或剩下,就是结果。
1 | class Solution { |
面试题 10.05. 稀疏数组搜索
Description
稀疏数组搜索。有个排好序的字符串数组,其中散布着一些空字符串,编写一种方法,找出给定字符串的位置。
Example
示例1:
输入: words = [“at”, “”, “”, “”, “ball”, “”, “”, “car”, “”, “”,”dad”, “”, “”], s = “ta”
输出:-1
说明: 不存在返回-1。
示例2:
输入:words = [“at”, “”, “”, “”, “ball”, “”, “”, “car”, “”, “”,”dad”, “”, “”], s = “ball”
输出:4
提示:
words的长度在[1, 1000000]之间
Program
二分分治
最差时间复杂度:$O(n)$
1 | class Solution { |
二分查找
问题在于mid为空字符串的情况需要特殊处理。
平均时间复杂度:$O(\log{n})$
1 | class Solution { |
矩阵二分
74. 搜索二维矩阵
Description
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
Example
示例 1:
输入:
1 | matrix = [ |
输出: true
示例 2:
输入:
1 | matrix = [ |
输出: false
Program
1 | class Solution { |
240. 搜索二维矩阵 II
Description
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
Example
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false。
Program
根据严格单调的特性:
令x=1,y=1000,
若f(x,y)<z,则计算f(x+1,,y)
若f(x,y)>z,则计算f(x,y-1)
若f(x,y)==z,则计算f(x+1,y-1)
时间复杂度:$O(m+n)$
确实巧妙,想了下这个算法的关键是找到合适的遍历起点,这个点肯定具有某种特殊性,这个二维矩阵,四个角就是四个特殊点,但他们的特点不同,左上和右下分别是矩阵的最小和最大值,左下和右上具有两面性,如果是所在行最大值那么就是所在列的最小值,反过来也一样。左上和右下与目标值比较不相等时,下一步既可以遍历行也可以遍历列是不确定的,而左下和右上是可以确定的,因为自身值的特点可以排除一个方向的路径,只有一个遍历路径。
1 | class Solution { |
378. 有序矩阵中第K小的元素
Description
给定一个 n x n 矩阵,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是排序后的第 k 小元素,而不是第 k 个不同的元素。
Example
示例:
1 | matrix = [ |
返回 13。
提示:
你可以假设 k 的值永远是有效的,1 ≤ k ≤ n2 。
Program
相似题目,用到同一性质的题:
240. 搜索二维矩阵 II
1237. 找出给定方程的正整数解
性质:
- f(x, y) < f(x + 1, y)
- f(x, y) < f(x, y + 1)
如果暴力排序,时间复杂度:$O(n^2 \log{n})$
思路
(1)矩阵最小值为matrix[0][0],最大值为matrix[n-1][n-1],分别记为left,right;
(2)记任意mid,使得left<=mid<=right,那么不大于mid所有元素肯定在矩阵左上方,
盗张图:
如图,mid=8,折线左上部分为不小于8的所有数
(3)那么从右上角或左下角开始,由性质可以发现可以单调移动,以右上角为例:
①若f(x,y)<=mid,计数ans+=y+1,x++(因为第x行y列左边所有数都不小于mid,而要比较下一行f(x+1,y));
②若f(x,y)>mid,y–;
(4)二分查找mid即可。
1 | class Solution { |
1292. 元素和小于等于阈值的正方形的最大边长
给你一个大小为 m x n 的矩阵 mat 和一个整数阈值 threshold。
请你返回元素总和小于或等于阈值的正方形区域的最大边长;如果没有这样的正方形区域,则返回 0 。
Example
示例 1:
输入:mat = [[1,1,3,2,4,3,2],[1,1,3,2,4,3,2],[1,1,3,2,4,3,2]], threshold = 4
输出:2
解释:总和小于 4 的正方形的最大边长为 2,如图所示。
示例 2:
输入:mat = [[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2]], threshold = 1
输出:0
示例 3:
输入:mat = [[1,1,1,1],[1,0,0,0],[1,0,0,0],[1,0,0,0]], threshold = 6
输出:3
示例 4:
输入:mat = [[18,70],[61,1],[25,85],[14,40],[11,96],[97,96],[63,45]], threshold = 40184
输出:2
提示:
1 <= m, n <= 300
m == mat.length
n == mat[i].length
0 <= mat[i][j] <= 10000
0 <= threshold <= 10^5
Program
前缀和+二分
先求出矩阵前缀和,然后对边长进行二分查找。
时间复杂度:$O(mn\log{min(m,n)}$
1 | class Solution { |
面试题 10.09. 排序矩阵查找
Description
给定M×N矩阵,每一行、每一列都按升序排列,请编写代码找出某元素。
Example
示例:
现有矩阵 matrix 如下:
1 | [ |
给定 target = 5,返回 true。
给定 target = 20,返回 false。
Program
1 | class Solution { |
二分思想
454. 四数相加 II
Description
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -228 到 228 - 1 之间,最终结果不会超过 231 - 1 。
Example
例如:
输入:
A = [ 1, 2]
B = [-2,-1]
C = [-1, 2]
D = [ 0, 2]
输出:
2
解释:
两个元组如下:
- (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
- (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
Program
二分
先求出两个数组的和,然后求另两个数组的和,在HashMap中查找即可。
1 | class Solution { |
面试题 08.03. 魔术索引
Description
魔术索引。 在数组A[0…n-1]中,有所谓的魔术索引,满足条件A[i] = i。给定一个有序整数数组,编写一种方法找出魔术索引,若有的话,在数组A中找出一个魔术索引,如果没有,则返回-1。若有多个魔术索引,返回索引值最小的一个。
Example
示例1:
输入:nums = [0, 2, 3, 4, 5]
输出:0
说明: 0下标的元素为0
示例2:
输入:nums = [1, 1, 1]
输出:1
提示:
nums长度在[1, 1000000]之间
Program
线性搜索
1 | class Solution { |
二分
1 | class Solution { |
分治
经典分治
4. 寻找两个正序数组的中位数
Description
给定两个大小为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。
请你找出这两个正序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
你可以假设 nums1 和 nums2 不会同时为空。
Example
示例 1:
nums1 = [1, 3]
nums2 = [2]
则中位数是 2.0
示例 2:
nums1 = [1, 2]
nums2 = [3, 4]
则中位数是 (2 + 3)/2 = 2.5
Program
暴力
时间复杂度:$O((m+n)/2)$
1 | class Solution { |
23. 合并K个排序链表
Description
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
Example
示例:
输入:
1 | [ |
输出: 1->1->2->3->4->4->5->6
Program
非递归归并
首先,此题与归并排序很像,只不过是链表合并,那么根据非递归归并可以这样做:
(1)len=2,4,8,…,这里需要注意n不是2的幂次的时候,len最大为比n大的最小2次幂——因为需要合并最终剩余的两个单链;
(2)对于每len个链进行归并,l,r分表表示左右端点,只需要合并l与(l+r+1)/2两个单链,结果存储在lists[l]中即可:
例如lists:[0,1,2,3,4,5,6]
len=2:[0,1]合并存储在lists[0]中,[2,3]合并存储在lists[2]中,…
len=4:[0,1,2,3]合并0,2存储在lists[0]中,[4,5,6]合并4,6存储在lists[4]…
len=8:[0,1,2,3,4,5,6]合并0,4存储在lists[0]中;
…
以此类推,所以最终结果存储在lists[0]中。
时间复杂度:$O(n\log(n))$
1 | /** |
218. 天际线问题
Description
城市的天际线是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。现在,假设您获得了城市风光照片(图A)上显示的所有建筑物的位置和高度,请编写一个程序以输出由这些建筑物形成的天际线(图B)。
每个建筑物的几何信息用三元组 [Li,Ri,Hi] 表示,其中 Li 和 Ri 分别是第 i 座建筑物左右边缘的 x 坐标,Hi 是其高度。可以保证 0 ≤ Li, Ri ≤ INT_MAX, 0 < Hi ≤ INT_MAX 和 Ri - Li > 0。您可以假设所有建筑物都是在绝对平坦且高度为 0 的表面上的完美矩形。
例如,图A中所有建筑物的尺寸记录为:[ [2 9 10], [3 7 15], [5 12 12], [15 20 10], [19 24 8] ] 。
输出是以 [ [x1,y1], [x2, y2], [x3, y3], … ] 格式的“关键点”(图B中的红点)的列表,它们唯一地定义了天际线。关键点是水平线段的左端点。请注意,最右侧建筑物的最后一个关键点仅用于标记天际线的终点,并始终为零高度。此外,任何两个相邻建筑物之间的地面都应被视为天际线轮廓的一部分。
例如,图B中的天际线应该表示为:[ [2 10], [3 15], [7 12], [12 0], [15 10], [20 8], [24, 0] ]。
说明:
任何输入列表中的建筑物数量保证在 [0, 10000] 范围内。
输入列表已经按左 x 坐标 Li 进行升序排列。
输出列表必须按 x 位排序。
输出天际线中不得有连续的相同高度的水平线。例如 […[2 3], [4 5], [7 5], [11 5], [12 7]…] 是不正确的答案;三条高度为 5 的线应该在最终输出中合并为一个:[…[2 3], [4 5], [12 7], …]
Program
扫描法
使用扫描线,从左至右扫过。如果遇到左端点,将高度入堆,如果遇到右端点,则将高度从堆中删除。使用 last 变量记录上一个转折点。
可以参考下面的图,扫描线下方的方格就是堆。
1 | class Solution { |
241. 为运算表达式设计优先级
Description
给定一个含有数字和运算符的字符串,为表达式添加括号,改变其运算优先级以求出不同的结果。你需要给出所有可能的组合的结果。有效的运算符号包含 +, - 以及 * 。
Example
示例 1:
输入: “2-1-1”
输出: [0, 2]
解释:
1 | ((2-1)-1) = 0 |
示例 2:
输入: “23-45”
输出: [-34, -14, -10, -10, 10]
解释:
1 | (2*(3-(4*5))) = -34 |
Program
分治
以操作符划分为两部分,分别求两部分的结果,最后对应求值。
可以发现可以分成两个子问题。
边界:纯数字
记得记忆化搜索,因为存在重复计算。
1 | class Solution { |
493. 翻转对
Description
给定一个数组 nums ,如果 $i < j 且 nums[i] > 2 * nums[j]$ 我们就将 (i, j) 称作一个重要翻转对。
你需要返回给定数组中的重要翻转对的数量。
Example
示例 1:
输入: [1,3,2,3,1]
输出: 2
示例 2:
输入: [2,4,3,5,1]
输出: 3
注意:
给定数组的长度不会超过50000。
输入数组中的所有数字都在32位整数的表示范围内。
Program
思路
求逆序对的思路,即求第i个元素左边比它大两倍的元素个数!树状数组求解:
(1)元素范围[-INT_MIN,INT_MAX],太大,树状数组C内存超限,需要离散化;
(2)对元素离散化后,需要找到在已排序初始数组nums中小于等于当前nums[i]的两倍的最大元素对应于离散化后的值!,显然二分查找:
- 为什么要找小于等于$target=nums[i] * 2$的最大元素对应离散值呢?——因为对于每个nums[i],需要数组左边[0,i-1]中求比$target$大的元素的个数,通过树状数组$getSum(n)-getSum(lessValue)$,其中lessValue是小于等于$target$最大元素的离散值!
(3)注意边界: - 有可能整个数组都比$target$小,那么二分查找到的对应元素离散值lessValue恰好为最大元素的离散值n,应当累加getSum(n)-getSum(lessValue)=getSum(n)-getSum(n)=0;
- 有可能整个数组都比$target$大,那么二分查找返回-1,此时应当累加getSum(n)-getSum(0)=getSum(n);
1 | class Solution { |
932. 漂亮数组
Description
对于某些固定的 N,如果数组 A 是整数 1, 2, …, N 组成的排列,使得:
对于每个 $i < j$,都不存在 k 满足 $i < k < j$ 使得 $A[k] * 2 = A[i] + A[j]$。
那么数组 A 是漂亮数组。
给定 N,返回任意漂亮数组 A(保证存在一个)。
Example
示例 1:
输入:4
输出:[2,1,4,3]
示例 2:
输入:5
输出:[3,1,2,5,4]
提示:
1 <= N <= 1000
Program
分治
性质:
(1)A是一个漂亮数组,如果对A中所有元素乘k+一个常数,那么A还是一个漂亮数组
(2)A是一个奇数漂亮数组,B是一个偶数漂亮数组,那么A+B也是漂亮数组:
- 因为$x[k] * 2=x[i] + x[j], i<k<j$对A,B都成立;
- 对于A+B,如果i,j都属于A或B,不用谈,那么如果i属于A,j属于B,方程左边为偶数,右边为奇数,所以方程也一定不成立,得证!
那么根据性质2,如果能够将所有奇数放在左边,所有偶数放在右边,各自成为一个漂亮数组,那么就找到结果了。
奇数有$(N+1)/2$个,偶数有$N/2$个。
进行子问题划分:
设$f(N)$为以$[1,N]$为某排列的漂亮数组,求$f((N+1)/2),f(N/2)$,可以发现:
- $f((N+1)/2)$的每个元素$x$,$x * 2-1 \in [1, N]$ 且 $(x * 2-1)&1=1$,即$x * 2-1$为奇数,且恰好为$[1,N]$的所有奇数。
- $f(N/2)$的每个元素$y$,$y * 2 \in [1, N]$ 且 $(y * 2)&1=0$,即$y * 2$为偶数,且恰好为$[1,N]$的所有偶数。
根据性质1、2,$[f((N+1)/2) * 2-1]+[f(N/2) * 2]$即为答案!
1 | class Solution { |
973. 最接近原点的 K 个点
Description
我们有一个由平面上的点组成的列表 points。需要从中找出 K 个距离原点 (0, 0) 最近的点。
(这里,平面上两点之间的距离是欧几里德距离。)
你可以按任何顺序返回答案。除了点坐标的顺序之外,答案确保是唯一的。
Example
示例 1:
输入:points = [[1,3],[-2,2]], K = 1
输出:[[-2,2]]
解释:
(1, 3) 和原点之间的距离为 sqrt(10),
(-2, 2) 和原点之间的距离为 sqrt(8),
由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。
我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。
示例 2:
输入:points = [[3,3],[5,-1],[-2,4]], K = 2
输出:[[3,3],[-2,4]]
(答案 [[-2,4],[3,3]] 也会被接受。)
提示:
1 | 1 <= K <= points.length <= 10000 |
Program
堆排序
优先队列实现,时间复杂度:$O(n\log{n})$
1 | class Solution { |
快排
题目要的是前k个距离最小的元素,根据快排的性质,每次快排都能将元素分成左右两部分。
平均时间复杂度:$O(n)$
1 | class Solution { |
剑指 Offer 25. 合并两个排序的链表
Description
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
Example
示例1:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
限制:
0 <= 链表长度 <= 1000
Program
1 | /** |
剑指 Offer 40. 最小的k个数
Description
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
Example
示例 1:
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]
示例 2:
输入:arr = [0,1,2,1], k = 1
输出:[0]
限制:
0 <= k <= arr.length <= 10000
0 <= arr[i] <= 10000
Program
1 | class Solution { |
面试题 17.14. 最小K个数
Description
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
Example
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4
输出: [1,2,3,4]
提示:
0 <= len(arr) <= 100000
0 <= k <= min(100000, len(arr))
Program
1 | class Solution { |
位运算
常规位运算
78. 子集
Description
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
Example
示例:
输入: nums = [1,2,3]
输出:
1 | [ |
Program
1 | class Solution { |
1356. 根据数字二进制下 1 的数目排序
Description
给你一个整数数组 arr 。请你将数组中的元素按照其二进制表示中数字 1 的数目升序排序。
如果存在多个数字二进制中 1 的数目相同,则必须将它们按照数值大小升序排列。
请你返回排序后的数组。
Example
示例 1:
输入:arr = [0,1,2,3,4,5,6,7,8]
输出:[0,1,2,4,8,3,5,6,7]
解释:[0] 是唯一一个有 0 个 1 的数。
[1,2,4,8] 都有 1 个 1 。
[3,5,6] 有 2 个 1 。
[7] 有 3 个 1 。
按照 1 的个数排序得到的结果数组为 [0,1,2,4,8,3,5,6,7]
示例 2:
输入:arr = [1024,512,256,128,64,32,16,8,4,2,1]
输出:[1,2,4,8,16,32,64,128,256,512,1024]
解释:数组中所有整数二进制下都只有 1 个 1 ,所以你需要按照数值大小将它们排序。
示例 3:
输入:arr = [10000,10000]
输出:[10000,10000]
示例 4:
输入:arr = [2,3,5,7,11,13,17,19]
输出:[2,3,5,17,7,11,13,19]
示例 5:
输入:arr = [10,100,1000,10000]
输出:[10,100,10000,1000]
提示:
1 <= arr.length <= 500
0 <= arr[i] <= 10^4
Program
1 | class Solution { |
去重位运算
136. 只出现一次的数字
Description
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
Example
示例 1:
输入: [2,2,1]
输出: 1
示例 2:
输入: [4,1,2,1,2]
输出: 4
Program
①常规思路
1 | class Solution { |
位运算’与’去重
1 | class Solution { |
剑指 Offer 39. 数组中出现次数超过一半的数字
Description
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
Example
示例 1:
输入: [1, 2, 3, 2, 2, 2, 5, 4, 2]
输出: 2
限制:
1 <= 数组长度 <= 50000
Program
思路
投票:由于众数过半,所以正负抵消,最终剩余的一定是众数。
1 | class Solution { |
137. 只出现一次的数字 II
Description
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
Example
示例 1:
输入: [2,2,3,2]
输出: 3
示例 2:
输入: [0,1,0,1,0,1,99]
输出: 99
Program
1 | class Solution { |
268. 缺失数字
Description
给定一个包含 0, 1, 2, …, n 中 n 个数的序列,找出 0 .. n 中没有出现在序列中的那个数。
Example
示例 1:
输入: [3,0,1]
输出: 2
示例 2:
输入: [9,6,4,2,3,5,7,0,1]
输出: 8
Program
位运算,$O(n)$,[0…n]异或,而数组缺少其中一个,故整体两次异或编程0,单独一次异或的就是缺失的了
1 | class Solution { |
贪心
区间贪心
55. 跳跃游戏
Description
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个位置。
Example
示例 1:
输入: [2,3,1,1,4]
输出: true
解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。
示例 2:
输入: [3,2,1,0,4]
输出: false
解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
Program
- 如果某一个作为 起跳点 的格子可以跳跃的距离是 3,那么表示后面 3 个格子都可以作为 起跳点。
- 可以对每一个能作为 起跳点 的格子都尝试跳一次,把 能跳到最远的距离 不断更新。
- 如果可以一直跳到最后,就成功了。
1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
bool canJump(vector<int>& nums) {
int k=0;
for(int i=0;i<nums.size();i++){
if(i>k) return false;
k=max(k, i+nums[i]);
if(k>=nums.size()-1) return true;
}
return true;
}
};135. 分发糖果
Description
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
每个孩子至少分配到 1 个糖果。
评分更高的孩子必须比他两侧的邻位孩子获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
Example
示例 1:
输入:[1,0,2]
输出:5
解释:你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
输入:[1,2,2]
输出:4
解释:你可以分别给这三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
Program
1 | class Solution { |
605. 种花问题
Description
假设有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给你一个整数数组 flowerbed 表示花坛,由若干 0 和 1 组成,其中 0 表示没种植花,1 表示种植了花。另有一个数 n ,能否在不打破种植规则的情况下种入 n 朵花?能则返回 true ,不能则返回 false。
Example
示例 1:
输入:flowerbed = [1,0,0,0,1], n = 1
输出:true
示例 2:
输入:flowerbed = [1,0,0,0,1], n = 2
输出:false
提示:
1 <= flowerbed.length <= 2 * 10^4
flowerbed[i] 为 0 或 1
flowerbed 中不存在相邻的两朵花
0 <= n <= flowerbed.length
Program
1 | class Solution { |
632. 最小区间
Description
你有 k 个升序排列的整数数组。找到一个最小区间,使得 k 个列表中的每个列表至少有一个数包含在其中。
我们定义如果 b-a < d-c 或者在 b-a == d-c 时 a < c,则区间 [a,b] 比 [c,d] 小。
Example
示例 1:
输入:[[4,10,15,24,26], [0,9,12,20], [5,18,22,30]]
输出: [20,24]
解释:
列表 1:[4, 10, 15, 24, 26],24 在区间 [20,24] 中。
列表 2:[0, 9, 12, 20],20 在区间 [20,24] 中。
列表 3:[5, 18, 22, 30],22 在区间 [20,24] 中。
注意:
给定的列表可能包含重复元素,所以在这里升序表示 >= 。
1 <= k <= 3500
-10^5 <= 元素的值 <= 10^5
对于使用Java的用户,请注意传入类型已修改为List<List
Program
思路
首先,我们想一下这样一个问题:题目要求是寻找最小区间,最小区间满足下面两点:
- 长度最小(首要)
- 长度相同时起点最小
长度最小的区间必然是需要我们在计算中找到的,但是起点最小的区间我们是可以知道的。就是从每个区间中找最小的元素,组成的新的区间,我们称其为起始区间。如果之后没有长度比起始区间长度更短的,那么起始区间就是我们所求的最小区间,因为起始区间的起点是最小的。
那么我们所需要做的就是搜索是否有比起始区间还要短的区间了。那么该如何搜索呢?
答案是 每次都将当前区间中最小的元素丢弃,换成其原始数组中的下一个元素(为了保证区间至少包含每个数组一个元素)。就是说,如果当前我们从每个区间中选取的元素分别是a1_1,a2_1,a3_1…ak_1(前面的数字代表来自第几个数组,后面的数字表示该数是该数组的第几个元素),若此时最小的元素是ai_1,最大元素是aj_1,那么区间就为[ai_1, aj_1],区间中最小元素是ai_1,那么我们就将ai_1丢弃,将ai_2拿出来放进去。
原因:如果不换ai_1,那么区间的起点就一直是ai_1,而且区间长度不可能缩小,区间长度取决于起点和终点,而终点是不可能变小的。因为我们是从小到大进行元素的选取,我们每次丢弃一个元素,就要选择它在原数组中的下一位,而原数组是升序排列的。故终点不可能减小。
那么,我们只能够通过让起点增大来是区间缩小,即每次丢弃最小的元素,换成它原数组的下一个元素。然后再计算当前所选区间的长度,如果小于之前的区间长度就更新即可。
结束条件:当当前最小元素是其原来整数数组的最后一个元素时,就是结束的时候。因为之后的操作不可能更改起点了,只会让终点变大,即区间变长。
1 | class Solution { |
1024. 视频拼接
Description
你将会获得一系列视频片段,这些片段来自于一项持续时长为 T 秒的体育赛事。这些片段可能有所重叠,也可能长度不一。
视频片段 clips[i] 都用区间进行表示:开始于 clips[i][0] 并于 clips[i][1] 结束。我们甚至可以对这些片段自由地再剪辑,例如片段 [0, 7] 可以剪切成 [0, 1] + [1, 3] + [3, 7] 三部分。
我们需要将这些片段进行再剪辑,并将剪辑后的内容拼接成覆盖整个运动过程的片段([0, T])。返回所需片段的最小数目,如果无法完成该任务,则返回 -1 。
Example
示例 1:
输入:clips = [[0,2],[4,6],[8,10],[1,9],[1,5],[5,9]], T = 10
输出:3
解释:
我们选中 [0,2], [8,10], [1,9] 这三个片段。
然后,按下面的方案重制比赛片段:
将 [1,9] 再剪辑为 [1,2] + [2,8] + [8,9] 。
现在我们手上有 [0,2] + [2,8] + [8,10],而这些涵盖了整场比赛 [0, 10]。
示例 2:
输入:clips = [[0,1],[1,2]], T = 5
输出:-1
解释:
我们无法只用 [0,1] 和 [0,2] 覆盖 [0,5] 的整个过程。
示例 3:
输入:clips = [[0,1],[6,8],[0,2],[5,6],[0,4],[0,3],[6,7],[1,3],[4,7],[1,4],[2,5],[2,6],[3,4],[4,5],[5,7],[6,9]], T = 9
输出:3
解释:
我们选取片段 [0,4], [4,7] 和 [6,9] 。
示例 4:
输入:clips = [[0,4],[2,8]], T = 5
输出:2
解释:
注意,你可能录制超过比赛结束时间的视频。
提示:
1 <= clips.length <= 100
0 <= clips[i][0] <= clips[i][1] <= 100
0 <= T <= 100
Program
动态规划
设DP[i]是以i为结束的最小数目:
(1)以HashMap记录以i为结尾的所有区间的起始点,这里需要将区间[s,e]中每个以s开头,j(j=s,…e)为结尾的区间都算进去;
(2)递推方程:DP[i]=min(DP[i],1+DP[m[i][j]),其中j为以i结尾的区间的索引,0表示该区间起始。
边界:
- 如果m[0].size()==0,表示没有以0开头的区间,如果m[T].size()==0,表示没有以T为结尾的区间,所以直接返回false;
- 否则DP[0]=0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Solution {
public:
const int inf=0x3f3f3f3f;
int videoStitching(vector<vector<int>>& clips, int T) {
unordered_map<int, vector<int> > m;//记录以i为结尾的区间
for(vector<int>& vec:clips){
int s=vec[0];
int e=vec[1];
for(int i=s;i<=e;i++){ //拆分区间
m[i].push_back(s);
}
}
int DP[T+1];
memset(DP, inf, sizeof(DP));
if(m[T].size()==0||m[0].size()==0) return -1;
DP[0]=0;
for(int i=0;i<=T;i++){
for(int j=0;j<m[i].size();j++){
int s=m[i][j];
DP[i]=min(DP[i], 1+DP[s]);
}
//cout<<DP[i]<<endl;
}
return DP[T]==inf?-1:DP[T]; //未找到连通区间
}
};
贪心
此题与跳跃游戏类似,可以说是其的变型。
DP[i]记录以i为起点的最远可达距离。
按起点i进行遍历,记录过程中最远可达距离,
- 如果i==mx(当前最大可达),说明不连续可达后面的点;
- 如果i==pre(上一次的最远可达),记录区间数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int videoStitching(vector<vector<int>>& clips, int T) {
int dp[101] ={0};
int mx = 0, ans = 0, pre = 0;
for (vector<int>& clip : clips) {
dp[clip[0]] = max(dp[clip[0]], clip[1]);
}
for (int i = 0; i < T; i++) {
mx = max(mx, dp[i]);
if (i == pre) { //已到达上一区间所能到达的最远距离
ans++;
pre = mx;
}
if (i == mx) return -1; //不可达
}
return ans;
}
};5641. 卡车上的最大单元数
Description
请你将一些箱子装在 一辆卡车 上。给你一个二维数组 boxTypes ,其中 boxTypes[i] = [numberOfBoxesi, numberOfUnitsPerBoxi] :
numberOfBoxesi 是类型 i 的箱子的数量。
numberOfUnitsPerBoxi 是类型 i 每个箱子可以装载的单元数量。
整数 truckSize 表示卡车上可以装载 箱子 的 最大数量 。只要箱子数量不超过 truckSize ,你就可以选择任意箱子装到卡车上。
返回卡车可以装载 单元 的 最大 总数。
Example
示例 1:
输入:boxTypes = [[1,3],[2,2],[3,1]], truckSize = 4
输出:8
解释:箱子的情况如下:
- 1 个第一类的箱子,里面含 3 个单元。
- 2 个第二类的箱子,每个里面含 2 个单元。
- 3 个第三类的箱子,每个里面含 1 个单元。
可以选择第一类和第二类的所有箱子,以及第三类的一个箱子。
单元总数 = (1 * 3) + (2 * 2) + (1 * 1) = 8
示例 2:
输入:boxTypes = [[5,10],[2,5],[4,7],[3,9]], truckSize = 10
输出:91
提示:
$1 <= boxTypes.length <= 1000$
$1 <= numberOfBoxesi, numberOfUnitsPerBoxi <= 1000$
$1 <= truckSize <= 10^6$
Program
1 | class Solution { |
5642. 大餐计数
Description
大餐 是指 恰好包含两道不同餐品 的一餐,其美味程度之和等于 2 的幂。
你可以搭配 任意 两道餐品做一顿大餐。
给你一个整数数组 deliciousness ,其中 deliciousness[i] 是第 i 道餐品的美味程度,返回你可以用数组中的餐品做出的不同 大餐 的数量。结果需要对 109 + 7 取余。
注意,只要餐品下标不同,就可以认为是不同的餐品,即便它们的美味程度相同。
Example
示例 1:
输入:deliciousness = [1,3,5,7,9]
输出:4
解释:大餐的美味程度组合为 (1,3) 、(1,7) 、(3,5) 和 (7,9) 。
它们各自的美味程度之和分别为 4 、8 、8 和 16 ,都是 2 的幂。
示例 2:
输入:deliciousness = [1,1,1,3,3,3,7]
输出:15
解释:大餐的美味程度组合为 3 种 (1,1) ,9 种 (1,3) ,和 3 种 (1,7) 。
提示:
$1 <= deliciousness.length <= 10^5$
$0 <= deliciousness[i] <= 2^20$
Program
1 | class Solution { |
树形分治
剑指 Offer 36. 二叉搜索树与双向链表
Description
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
为了让您更好地理解问题,以下面的二叉搜索树为例:
我们希望将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
Program
分治
先吐槽下自己,早就写出来了,然后dfs里面调用dfs的地方,忘记将treeToDoublyList()改成dfs(),然后找了半天bug…
(1)当前根结点为中间节点,左右子树当然就成为了两个分治子问题,分别求各自的递增循环队列
(2)合并循环队列。
1 | /* |
数学
常规数学
2. 两数相加
Description
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
Example
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
Program
1 | /** |
7.整数反转
Description
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
Example
示例 1:
输入: 123
输出: 321
示例 2:
输入: -123
输出: -321
示例 3:
输入: 120
输出: 21
Program
1 | class Solution { |
8. 字符串转换整数 (atoi)
Description
请你来实现一个 atoi 函数,使其能将字符串转换成整数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。接下来的转化规则如下:
- 如果第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字字符组合起来,形成一个有符号整数。
- 假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成一个整数。
- 该字符串在有效的整数部分之后也可能会存在多余的字符,那么这些字符可以被忽略,它们对函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换,即无法进行有效转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0 。
提示:
本题中的空白字符只包括空格字符 ‘ ‘ 。
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 $[−2^31, 2^31 − 1]$。如果数值超过这个范围,请返回 INT_MAX $(2^31 − 1)$ 或 INT_MIN $(−2^31)$ 。
Example
示例 1:
输入: “42”
输出: 42
示例 2:
输入: “ -42”
输出: -42
解释: 第一个非空白字符为 ‘-‘, 它是一个负号。
我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。
示例 3:
输入: “4193 with words”
输出: 4193
解释: 转换截止于数字 ‘3’ ,因为它的下一个字符不为数字。
示例 4:
输入: “words and 987”
输出: 0
解释: 第一个非空字符是 ‘w’, 但它不是数字或正、负号。
因此无法执行有效的转换。
示例 5:
输入: “-91283472332”
输出: -2147483648
解释: 数字 “-91283472332” 超过 32 位有符号整数范围。
因此返回 INT_MIN $(−2^31)$ 。
Program
1 | class Solution { |
9.回文数
Description
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
Example
示例 1:
输入: 121
输出: true
示例 2:
输入: -121
输出: false
解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 3:
输入: 10
输出: false
解释: 从右向左读, 为 01 。因此它不是一个回文数。
Program
1 | class Solution { |
12. 整数转罗马数字
Description
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 |
|
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
- I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
- X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
- C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个整数,将其转为罗马数字。输入确保在 1 到 3999 的范围内。
Example
示例 1:
输入: 3
输出: “III”
示例 2:
输入: 4
输出: “IV”
示例 3:
输入: 9
输出: “IX”
示例 4:
输入: 58
输出: “LVIII”
解释: L = 50, V = 5, III = 3.
示例 5:
输入: 1994
输出: “MCMXCIV”
解释: M = 1000, CM = 900, XC = 90, IV = 4.
Program
1 | class Solution { |
29. 两数相除
Description
给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。
返回被除数 dividend 除以除数 divisor 得到的商。
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
Example
示例 1:
输入: dividend = 10, divisor = 3
输出: 3
解释: 10/3 = truncate(3.33333..) = truncate(3) = 3
示例 2:
输入: dividend = 7, divisor = -3
输出: -2
解释: 7/-3 = truncate(-2.33333..) = -2
提示:
被除数和除数均为 32 位有符号整数。
除数不为 0。
假设我们的环境只能存储 32 位有符号整数,其数值范围是 $[−2^{31}, 2^{31} − 1]$。本题中,如果除法结果溢出,则返回 $2^{31} − 1$。
Program
例如:11/2,题目要求不用乘法、除法和mod运算符,那么只能用加减法,11一直减2太慢
11-2-4-…更快,那么需要判断是否越过了11.
一般情况a/b:
(1)a=INT_MIN且b=-1,越上界,结果应为INT_MAX;
(2)记录最终结果符号,如果a,b都转成正数,INT_MIN会越上界,所以都转为负数计算,详见代码
当然笔试啥的可能就直接转long了,避免麻烦。
1 | class Solution { |
50. Pow(x, n)
Description
实现 $pow(x, n)$ ,即计算 $x$ 的 $n$ 次幂函数。
Example
示例 1:
输入: 2.00000, 10
输出: 1024.00000
示例 2:
输入: 2.10000, 3
输出: 9.26100
示例 3:
输入: 2.00000, -2
输出: 0.25000
解释: 2-2 = 1/22 = 1/4 = 0.25
说明:
$-100.0 < x < 100.0$
$n$ 是 32 位有符号整数,其数值范围是 $[−231, 231 − 1]$ 。
Program
1 | class Solution { |
223. 矩形面积
Description
在二维平面上计算出两个由直线构成的矩形重叠后形成的总面积。
每个矩形由其左下顶点和右上顶点坐标表示,如图所示。
Example
示例:
输入: -3, 0, 3, 4, 0, -1, 9, 2
输出: 45
说明: 假设矩形面积不会超出 int 的范围。
Program
1 | 思路:先对两个矩形按照左下角横坐标排序,较小的在左边,即rectA, rectB |
1 | class Solution { |
367. 有效的完全平方数
Description
给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False。
说明:不要使用任何内置的库函数,如 sqrt。
Example
示例 1:
输入:16
输出:True
示例 2:
输入:14
输出:False
Program
1 | class Solution { |
1093. 大样本统计
Description
我们对 0 到 255 之间的整数进行采样,并将结果存储在数组 count 中:count[k] 就是整数 k 的采样个数。
我们以 浮点数 数组的形式,分别返回样本的最小值、最大值、平均值、中位数和众数。其中,众数是保证唯一的。
我们先来回顾一下中位数的知识:
如果样本中的元素有序,并且元素数量为奇数时,中位数为最中间的那个元素;
如果样本中的元素有序,并且元素数量为偶数时,中位数为中间的两个元素的平均值。
Example
示例 1:
输入:count = [0,1,3,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
输出:[1.00000,3.00000,2.37500,2.50000,3.00000]
示例 2:
输入:count = [0,4,3,2,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
输出:[1.00000,4.00000,2.18182,2.00000,1.00000]
提示:
count.length == 256
1 <= sum(count) <= 10^9
计数表示的众数是唯一的
答案与真实值误差在 10^-5 以内就会被视为正确答案
Program
1 | class Solution { |
规划数学
面试题 16.11. 跳水板
Description
你正在使用一堆木板建造跳水板。有两种类型的木板,其中长度较短的木板长度为shorter,长度较长的木板长度为longer。你必须正好使用k块木板。编写一个方法,生成跳水板所有可能的长度。
返回的长度需要从小到大排列。
Example
示例:
输入:
shorter = 1
longer = 2
k = 3
输出: {3,4,5,6}
提示:
$0 < shorter <= longer$
$0 <= k <= 100000$
Program
①记忆搜索
超时
1 | class Solution { |
②数学
题目k的范围限制了不能使用递归。
那么如何考虑呢?
(1)首先,有$k+1$种组合,每种组合下的长度不相同,证明如下:
- 不失一般性,设i,j分别为短板数目,且$0<=i<j<=k$,长度分别为:
- $shorter * i+longer * (k-i), shorter * j+longer * (k-j)$
- 二者之差:$shorter * i+longer * (k-i)-shorter * j-longer * (k-j)=(longer-shorter) * (j-i)!=0$
(2)两个边界,$k==0$和$shorter==longer$可以直接得出答案。
(3)一般情况求解,$shorter * i+longer * (k-i), k>=i>=0$,其中$i$递减遍历即可得到长度递增的答案,因为$i$递减的过程中,最终长度相当于每次用一根长板替换一根短板,所以长度在变长!
时间复杂度:$O(k)$1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
vector<int> divingBoard(int shorter, int longer, int k) {
if(k==0) return {};
if(longer==shorter) return {k*shorter};
vector<int> res(k+1, 0);
for(int i=k;i>=0;i--){
res[k-i]=shorter*i+longer*(k-i);
}
return res;
}
};模拟数学
67. 二进制求和
Description
给定两个二进制字符串,返回他们的和(用二进制表示)。
输入为非空字符串且只包含数字 1 和 0。
Example
示例 1:
输入: a = “11”, b = “1”
输出: “100”
示例 2:
输入: a = “1010”, b = “1011”
输出: “10101”
Program
1 | class Solution { |
数学规律
168. Excel表列名称
Description
给定一个正整数,返回它在 Excel 表中相对应的列名称。
例如,
1 | 1 -> A |
Example
示例 1:
输入: 1
输出: “A”
示例 2:
输入: 28
输出: “AB”
示例 3:
输入: 701
输出: “ZY”
Program
1 | class Solution { |
166. 分数到小数
Description
给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以字符串形式返回小数。
如果小数部分为循环小数,则将循环的部分括在括号内。
Example
示例 1:
输入: numerator = 1, denominator = 2
输出: “0.5”
示例 2:
输入: numerator = 2, denominator = 1
输出: “2”
示例 3:
输入: numerator = 2, denominator = 3
输出: “0.(6)”
Program
模拟
模拟除法,特别要注意-INT_MAX,INT_MAX,与1,-1组合,特判。
(1)首先要注意混循环小数,例如2/15=0.1333…,1/6=0.1666…这种非纯循环小数(0.333…,0.1111..)情况;
(2)再看看模拟除法过程中何时会出现循环小数,以num表示分子,den表示分母:
①如果num<den,当前商为0,num=10;
②如果num>=den,当前商为num/den (除了整数部分,商一定为个位数1~9),num=num%den10;
那么循环小数出现的条件就是num重复出现!用Hash记录已出现的num即可。
(3)记录小数点的位置以及括号的位置。
1 | class Solution { |
171. Excel表列序号
Description
给定一个Excel表格中的列名称,返回其相应的列序号。
例如,
1 | A -> 1 |
Example
示例 1:
输入: “A”
输出: 1
示例 2:
输入: “AB”
输出: 28
示例 3:
输入: “ZY”
输出: 701
Program
1 | class Solution { |
172. 阶乘后的零
Description
给定一个整数 n,返回 n! 结果尾数中零的数量。
Example
示例 1:
输入: 3
输出: 0
解释: 3! = 6, 尾数中没有零。
示例 2:
输入: 5
输出: 1
解释: 5! = 120, 尾数中有 1 个零.
Program
0的数量与10有关,10与因子2和5有关,2的个数一定比5多。
5出现次数为每5个出现一次,每25出现两次,每125出现三次….
1 | class Solution { |
202. 快乐数
Description
编写一个算法来判断一个数是不是“快乐数”。
一个“快乐数”定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果可以变为 1,那么这个数就是快乐数。
Example
示例:
输入: 19
输出: true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
Program
1 | class Solution { |
231. 2的幂
Description
给定一个整数,编写一个函数来判断它是否是 2 的幂次方。
Example
示例 1:
输入: 1
输出: true
解释: 20 = 1
示例 2:
输入: 16
输出: true
解释: 24 = 16
示例 3:
输入: 218
输出: false
Program
1 | class Solution { |
1 | class Solution { |
258. 各位相加
Description
给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数。
Example
示例:
输入: 38
输出: 2
解释: 各位相加的过程为:3 + 8 = 11, 1 + 1 = 2。 由于 2 是一位数,所以返回 2。
进阶:
你可以不使用循环或者递归,且在 O(1) 时间复杂度内解决这个问题吗?
Program
(1)令$X=x_{n} * 10^{n-1} + x_{n-1} * 10^{n-2}…+x_1$,则:
$$X=x_{n} * (10^{n-1}-1+1) + x_{n-1} * (10^{n-2}-1+1)…+x_1 \\
=x_{n} * (10^{n-1}-1) + x_{n-1} * (10^{n-2}-1)…+(x_n+…x_1)$$
其中$n>=1$,所以$n-i>1时,10^{n-i} \pmod 9==0$
设$Y=(x_n+…x_1)$:
- 当$0<=Y<9$,就是所求答案,$Answer=X \pmod 9=(X-1) \pmod 9$;
- 当$Y==9$,也是答案,$Answer=(X-1) \pmod 9+1$——因为直接模9为0;
- 当$Y>9$,也就是$Y$的位数多于一位,那么又回到了原问题$X$,所以还是最终一定会到个位数,即$Answer=(X-1) \pmod 9+1$。
1
2
3
4
5
6class Solution {
public:
int addDigits(int num) {
return (num - 1) % 9 + 1;
}
};数学推导
1201. 丑数 III
Description
请你帮忙设计一个程序,用来找出第 n 个丑数。
丑数是可以被 a 或 b 或 c 整除的 正整数。
Example
示例 1:
输入:n = 3, a = 2, b = 3, c = 5
输出:4
解释:丑数序列为 2, 3, 4, 5, 6, 8, 9, 10… 其中第 3 个是 4。
示例 2:
输入:n = 4, a = 2, b = 3, c = 4
输出:6
解释:丑数序列为 2, 3, 4, 6, 8, 9, 12… 其中第 4 个是 6。
示例 3:
输入:n = 5, a = 2, b = 11, c = 13
输出:10
解释:丑数序列为 2, 4, 6, 8, 10, 11, 12, 13… 其中第 5 个是 10。
示例 4:
输入:n = 1000000000, a = 2, b = 217983653, c = 336916467
输出:1999999984
提示:
1 <= n, a, b, c <= 10^9
1 <= a * b * c <= 10^18
本题结果在 [1, 2 * 10^9] 的范围内
Program
1,对于一个数,有多少个丑数小于等于该数是可以快速计算出来的
2,因此可以用二分搜索定位该数
1 | class Solution { |
素数筛选
204. 计数质数
Description
统计所有小于非负整数 n 的质数的数量。
Example
示例:
输入: 10
输出: 4
解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
Program
1 | class Solution { |
有限状态自动机
确定性有限状态自动机
65. 有效数字
Description
验证给定的字符串是否可以解释为十进制数字。
Example
例如:
“0” => true
“ 0.1 “ => true
“abc” => false
“1 a” => false
“2e10” => true
“ -90e3 “ => true
“ 1e” => false
“e3” => false
“ 6e-1” => true
“ 99e2.5 “ => false
“53.5e93” => true
“ –6 “ => false
“-+3” => false
“95a54e53” => false
说明: 我们有意将问题陈述地比较模糊。在实现代码之前,你应当事先思考所有可能的情况。这里给出一份可能存在于有效十进制数字中的字符列表:
数字 0-9
指数 - “e”
正/负号 - “+”/“-“
小数点 - “.”
当然,在输入中,这些字符的上下文也很重要。
Program
1 | class Solution { |
滑动窗口
经典滑窗
3. 无重复字符的最长子串
Description
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
Example
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,”pwke” 是一个子序列,不是子串。
Program
滑动窗口
设s,e分别为不重复子串的起止位置,可以发现如果str[s:e]为无重复子串,那么[s+1,e]也为无重复子串!
遍历s从头到尾:
(1)剔除前一个位置的字符;
(2)以s为开头,只要满足无重复就不断后移e;
1 | class Solution { |
209. 长度最小的子数组
Description
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。
Example
示例:
输入:s = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
进阶:
如果你已经完成了$O(n)$时间复杂度的解法, 请尝试$O(n log n)$时间复杂度的解法。
Program
滑窗
时间复杂度:$O(n)$
1 | class Solution { |
424. 替换后的最长重复字符
Description
给你一个仅由大写英文字母组成的字符串,你可以将任意位置上的字符替换成另外的字符,总共可最多替换 k 次。在执行上述操作后,找到包含重复字母的最长子串的长度。
注意:
字符串长度 和 k 不会超过 104。
Example
示例 1:
输入:
s = “ABAB”, k = 2
输出:
4
解释:
用两个’A’替换为两个’B’,反之亦然。
示例 2:
输入:
s = “AABABBA”, k = 1
输出:
4
解释:
将中间的一个’A’替换为’B’,字符串变为 “AABBBBA”。
子串 “BBBB” 有最长重复字母, 答案为 4。
Program
滑动窗口
这题与’1004 最大连续1的个数 III’类似,不同的是1004题知道所求连续1个数,而这里未知,可以是任意字符组成的最大长度。
问题的关键仿佛在于是哪个字符组成了最大长度?!
然而,这么想的话不好分析,可以是任意字符。
那么一个简单的想法就是记录当前窗口中字符出现个数的最大值maxCount:
(1)如果maxCount+k小于窗口长度则继续在增长窗口,窗口右终点右移;
(2)否则,窗口缩减,窗口左起点右移;
这里的思想还是滑动窗口的思想,即窗口[s,e]满足条件,那么[s+1…,e]肯定也是满足条件的窗口,最后结果取过程中窗口长度最大值即可。
1 | class Solution { |
567. 字符串的排列
Description
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列。
换句话说,第一个字符串的排列之一是第二个字符串的子串。
Example
示例1:
输入: s1 = “ab” s2 = “eidbaooo”
输出: True
解释: s2 包含 s1 的排列之一 (“ba”).
示例2:
输入: s1= “ab” s2 = “eidboaoo”
输出: False
注意:
输入的字符串只包含小写字母
两个字符串的长度都在 [1, 10,000] 之间
Program
滑动窗口
很明显滑动窗口题,关键在于如何在s1长度窗口内匹配所有s1的字母,先上滑窗模板:
(1)窗口起始i前一个位置i-1如果有s1的字母出现,m[s2[i-1]]++,同时由于窗口后移一位,窗口长度k++;
(2)while中滑动窗口计算,如果发现s1的字母出现m[s2[e+1]]–,不过这里会有问题:可能窗口内匹配的某种字母比s1对应字母的个数要多!
(3)为解决这个问题,需要确定s1长度窗口内对应每种s1的字母个数m[ch]==0,说明完全匹配,否则并不匹配。
时间复杂度:$O(kn)$——for为n复杂度,而while在整个for过程最多移动n长度,复杂度n,而判断完全匹配为k=26,其中n为s2长度,k为s1最多包含不同字母数。
1 | class Solution { |
992. K 个不同整数的子数组
Description
给定一个正整数数组 A,如果 A 的某个子数组中不同整数的个数恰好为 K,则称 A 的这个连续、不一定独立的子数组为好子数组。
(例如,[1,2,3,1,2] 中有 3 个不同的整数:1,2,以及 3。)
返回 A 中好子数组的数目。
Example
示例 1:
输入:A = [1,2,1,2,3], K = 2
输出:7
解释:恰好由 2 个不同整数组成的子数组:[1,2], [2,1], [1,2], [2,3], [1,2,1], [2,1,2], [1,2,1,2].
示例 2:
输入:A = [1,2,1,3,4], K = 3
输出:3
解释:恰好由 3 个不同整数组成的子数组:[1,2,1,3], [2,1,3], [1,3,4].
提示:
1 <= A.length <= 20000
1 <= A[i] <= A.length
1 <= K <= A.length
Program
滑窗
错误代码
样例一就有问题[1,2,1,2]中的{2,1,2}无法识别orz。
1 | class Solution { |
详见官方题解
K个不同整数的子数组个数=最多包含K种不同整数的子数组个数-最多包含K-1种不同整数的子数组个数,妙啊!
1 | class Solution { |
1004. 最大连续1的个数 III
Description
给定一个由若干 0 和 1 组成的数组 A,我们最多可以将 K 个值从 0 变成 1 。
返回仅包含 1 的最长(连续)子数组的长度。
Example
示例 1:
输入:A = [1,1,1,0,0,0,1,1,1,1,0], K = 2
输出:6
解释:
[1,1,1,0,0,1,1,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 6。
示例 2:
输入:A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3
输出:10
解释:
[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 10。
提示:
1 <= A.length <= 20000
0 <= K <= A.length
A[i] 为 0 或 1
Program
滑动窗口
双指针,l,r表示当前满足条件的子数组头尾下标,如果[l,r]为满足题意的子数组,则[l+1,r]也为满足题意的子数组,不同的是应当尽可能翻转所有K个0使得子数组长尽可能大。
(1)移动左指针l,如果上个位置l-1为0则,K++,可翻转0数增加1;
(2)每个l不动,移动r,若后续为1或者K>0,不断移动r;
(3)更新每个[l,r]的最大长度。
时间复杂度:$O(n)$
1 | class Solution { |
1052. 爱生气的书店老板
Description
今天,书店老板有一家店打算试营业 customers.length 分钟。每分钟都有一些顾客(customers[i])会进入书店,所有这些顾客都会在那一分钟结束后离开。
在某些时候,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。 当书店老板生气时,那一分钟的顾客就会不满意,不生气则他们是满意的。
书店老板知道一个秘密技巧,能抑制自己的情绪,可以让自己连续 X 分钟不生气,但却只能使用一次。
请你返回这一天营业下来,最多有多少客户能够感到满意的数量。
Example
示例:
输入:customers = [1,0,1,2,1,1,7,5], grumpy = [0,1,0,1,0,1,0,1], X = 3
输出:16
解释:
书店老板在最后 3 分钟保持冷静。
感到满意的最大客户数量 = 1 + 1 + 1 + 1 + 7 + 5 = 16.
提示:
1 <= X <= customers.length == grumpy.length <= 20000
0 <= customers[i] <= 1000
0 <= grumpy[i] <= 1
Program
思路
题目求一整天最大顾客满意数。
其中老板不生气的时候肯定都是满意的,关键就是在连续X分钟内能够使得其中老板生气时间下顾客最多就是最终答案。
典型就是求X窗口内顾客满意数的最大值!(注意需要的是对应分钟内老板在生气!你TM真傲娇!)
1 | class Solution { |
1208. 尽可能使字符串相等
Description
给你两个长度相同的字符串,s 和 t。
将 s 中的第 i 个字符变到 t 中的第 i 个字符需要 |s[i] - t[i]| 的开销(开销可能为 0),也就是两个字符的 ASCII 码值的差的绝对值。
用于变更字符串的最大预算是 maxCost。在转化字符串时,总开销应当小于等于该预算,这也意味着字符串的转化可能是不完全的。
如果你可以将 s 的子字符串转化为它在 t 中对应的子字符串,则返回可以转化的最大长度。
如果 s 中没有子字符串可以转化成 t 中对应的子字符串,则返回 0。
Example
示例 1:
输入:s = “abcd”, t = “bcdf”, cost = 3
输出:3
解释:s 中的 “abc” 可以变为 “bcd”。开销为 3,所以最大长度为 3。
示例 2:
输入:s = “abcd”, t = “cdef”, cost = 3
输出:1
解释:s 中的任一字符要想变成 t 中对应的字符,其开销都是 2。因此,最大长度为 1。
示例 3:
输入:s = “abcd”, t = “acde”, cost = 0
输出:1
解释:你无法作出任何改动,所以最大长度为 1。
提示:
1 <= s.length, t.length <= 10^5
0 <= maxCost <= 10^6
s 和 t 都只含小写英文字母。
Program
滑动窗口套路,注意细节。
1 | class Solution { |
1234. 替换子串得到平衡字符串
Description
有一个只含有 ‘Q’, ‘W’, ‘E’, ‘R’ 四种字符,且长度为 n 的字符串。
假如在该字符串中,这四个字符都恰好出现 n/4 次,那么它就是一个「平衡字符串」。
给你一个这样的字符串 s,请通过「替换一个子串」的方式,使原字符串 s 变成一个「平衡字符串」。
你可以用和「待替换子串」长度相同的 任何 其他字符串来完成替换。
请返回待替换子串的最小可能长度。
如果原字符串自身就是一个平衡字符串,则返回 0。
Example
示例 1:
输入:s = “QWER”
输出:0
解释:s 已经是平衡的了。
示例 2:
输入:s = “QQWE”
输出:1
解释:我们需要把一个 ‘Q’ 替换成 ‘R’,这样得到的 “RQWE” (或 “QRWE”) 是平衡的。
示例 3:
输入:s = “QQQW”
输出:2
解释:我们可以把前面的 “QQ” 替换成 “ER”。
示例 4:
输入:s = “QQQQ”
输出:3
解释:我们可以替换后 3 个 ‘Q’,使 s = “QWER”。
提示:
$1 <= s.length <= 10^5$
s.length 是 4 的倍数
s 中只含有 ‘Q’, ‘W’, ‘E’, ‘R’ 四种字符
Program
滑动窗口
(1)题目要求替换一个子串得到满足条件的字符串,可以考虑滑动窗口;
(2)窗口外的所有字符必须满足个数小于等于n/4即可,上模板!
注意更新ans的时候需要判断是否窗口外满足条件;
1 | class Solution { |
1456. 定长子串中元音的最大数目
Description
给你字符串 s 和整数 k 。
请返回字符串 s 中长度为 k 的单个子字符串中可能包含的最大元音字母数。
英文中的 元音字母 为(a, e, i, o, u)。
Example
示例 1:
输入:s = “abciiidef”, k = 3
输出:3
解释:子字符串 “iii” 包含 3 个元音字母。
示例 2:
输入:s = “aeiou”, k = 2
输出:2
解释:任意长度为 2 的子字符串都包含 2 个元音字母。
示例 3:
输入:s = “leetcode”, k = 3
输出:2
解释:”lee”、”eet” 和 “ode” 都包含 2 个元音字母。
示例 4:
输入:s = “rhythms”, k = 4
输出:0
解释:字符串 s 中不含任何元音字母。
示例 5:
输入:s = “tryhard”, k = 4
输出:1
提示:
1 <= s.length <= 10^5
s 由小写英文字母组成
1 <= k <= s.length
Program
滑动窗口
典型滑动窗口题,这里需要将所有元音字母统一计数。
1 | class Solution { |
1658. 将 x 减到 0 的最小操作数
Description
给你一个整数数组 nums 和一个整数 x 。每一次操作时,你应当移除数组 nums 最左边或最右边的元素,然后从 x 中减去该元素的值。请注意,需要 修改 数组以供接下来的操作使用。
如果可以将 x 恰好 减到 0 ,返回 最小操作数 ;否则,返回 -1 。
Example
示例 1:
输入:nums = [1,1,4,2,3], x = 5
输出:2
解释:最佳解决方案是移除后两个元素,将 x 减到 0 。
示例 2:
输入:nums = [5,6,7,8,9], x = 4
输出:-1
示例 3:
输入:nums = [3,2,20,1,1,3], x = 10
输出:5
解释:最佳解决方案是移除后三个元素和前两个元素(总共 5 次操作),将 x 减到 0 。
提示:
$1 <= nums.length <= 10^5$
$1 <= nums[i] <= 10^4$
$1 <= x <= 10^9$
Program
哈希表
(1)题目要找的就是[j, i]范围内和为k=sum-x的i-j+1值最大的区间!,sum为数组总和;
(2)滑窗为常规做法,这里采用哈希表;
(3)题目preSum[i]-preSum[j]=k,也就是preSum[j]=preSum[i]-k,对于每个preSum[i]找满足该条件的j(j<i),完全就是区间个数的求法!详见代码;
时间复杂度:$O(n)$
1 | class Solution { |
剑指 Offer 48. 最长不含重复字符的子字符串
Description
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
Example
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,”pwke” 是一个子序列,不是子串。
提示:
s.length <= 40000
Program
[s:e]为无重复子串,那么[s+1…:e]即s以后都为无重复子串,所以无需重复,移动窗口剔除前面出去的字符,判断后续字母能否继续增长即可。
1 | class Solution { |
技巧滑窗
239. 滑动窗口最大值
Description
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
进阶:
你能在线性时间复杂度内解决此题吗?
Example
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
1 | 滑动窗口的位置 最大值 |
提示:
1 <= nums.length <= 10^5
-10^4 <= nums[i] <= 10^4
1 <= k <= nums.length
Program
滑动窗口
一个很自然的思路就是维护一个保有索引的优先队列,然而时间复杂度为$O(n\log{k})$
线性复杂度的做法:
维护一个双端队列window:
(1)变量的最前端(也就是 window.front())是此次遍历的最大值的下标
(2)当我们遇到新的数时,将新的数和双项队列的末尾(也就是window.back())比较,如果末尾比新数小,则把末尾扔掉,直到该队列的末尾比新数大或者队列为空的时候才停止。
(3)双项队列中的所有值都要在窗口范围内
特点1:队列头尾当前最大元素下标
特点2:队列降序排列,最大值、次大值…下标
例如
1 | [1,3,1,2,0,5] |
[[1,3,1],2,0,5],队列3,1
[1,[3,1,2],0,5],队列3,2
[1,3,[1,2,0],5],剔除3,新进0,队列2,0
[1,3,1,[2,0,5]],队列5
1 | class Solution { |
传统思路
超时
1 | class Solution { |
1033. 移动石子直到连续
Description
三枚石子放置在数轴上,位置分别为 a,b,c。
每一回合,我们假设这三枚石子当前分别位于位置 x, y, z 且 $x < y < z$。从位置 x 或者是位置 z 拿起一枚石子,并将该石子移动到某一整数位置 k 处,其中 $x < k < z$ 且 k != y。
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves]
Example
示例 1:
输入:a = 1, b = 2, c = 5
输出:[1, 2]
解释:将石子从 5 移动到 4 再移动到 3,或者我们可以直接将石子移动到 3。
示例 2:
输入:a = 4, b = 3, c = 2
输出:[0, 0]
解释:我们无法进行任何移动。
提示:
1 <= a <= 100
1 <= b <= 100
1 <= c <= 100
a != b, b != c, c != a
Program
假设a,b,c升序
最大步数为a,c一步步走到与b紧靠
最小步数:
(1)三者紧靠,0;
(2)其中有一对紧靠,1;
(3)三者之间两两各间隔一位,1;//直接插空到位
(4)三者之间两两间隔大于1,2;//a,c之间各一步移动到b紧靠
1 | class Solution { |
1438. 绝对差不超过限制的最长连续子数组
Description
给你一个整数数组 nums ,和一个表示限制的整数 limit,请你返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 limit 。
如果不存在满足条件的子数组,则返回 0 。
Example
示例 1:
输入:nums = [8,2,4,7], limit = 4
输出:2
解释:所有子数组如下:
[8] 最大绝对差 |8-8| = 0 <= 4.
[8,2] 最大绝对差 |8-2| = 6 > 4.
[8,2,4] 最大绝对差 |8-2| = 6 > 4.
[8,2,4,7] 最大绝对差 |8-2| = 6 > 4.
[2] 最大绝对差 |2-2| = 0 <= 4.
[2,4] 最大绝对差 |2-4| = 2 <= 4.
[2,4,7] 最大绝对差 |2-7| = 5 > 4.
[4] 最大绝对差 |4-4| = 0 <= 4.
[4,7] 最大绝对差 |4-7| = 3 <= 4.
[7] 最大绝对差 |7-7| = 0 <= 4.
因此,满足题意的最长子数组的长度为 2 。
示例 2:
输入:nums = [10,1,2,4,7,2], limit = 5
输出:4
解释:满足题意的最长子数组是 [2,4,7,2],其最大绝对差 |2-7| = 5 <= 5 。
示例 3:
输入:nums = [4,2,2,2,4,4,2,2], limit = 0
输出:3
提示:
1 <= nums.length <= 10^5
1 <= nums[i] <= 10^9
0 <= limit <= 10^9
Program
滑动窗口最大值变型题,所不同的是需要维护两个双端队列,分别保存窗口最大值和最小值(其实是窗口最值排序)
1 | class Solution { |
1040. 移动石子直到连续 II
Description
在一个长度无限的数轴上,第 i 颗石子的位置为 stones[i]。如果一颗石子的位置最小/最大,那么该石子被称作端点石子。
每个回合,你可以将一颗端点石子拿起并移动到一个未占用的位置,使得该石子不再是一颗端点石子。
值得注意的是,如果石子像 stones = [1,2,5] 这样,你将无法移动位于位置 5 的端点石子,因为无论将它移动到任何位置(例如 0 或 3),该石子都仍然会是端点石子。
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves] 。
Example
示例 1:
输入:[7,4,9]
输出:[1,2]
解释:
我们可以移动一次,4 -> 8,游戏结束。
或者,我们可以移动两次 9 -> 5,4 -> 6,游戏结束。
示例 2:
输入:[6,5,4,3,10]
输出:[2,3]
解释:
我们可以移动 3 -> 8,接着是 10 -> 7,游戏结束。
或者,我们可以移动 3 -> 7, 4 -> 8, 5 -> 9,游戏结束。
注意,我们无法进行 10 -> 2 这样的移动来结束游戏,因为这是不合要求的移动。
示例 3:
输入:[100,101,104,102,103]
输出:[0,0]
提示:
3 <= stones.length <= 10^4
1 <= stones[i] <= 10^9
stones[i] 的值各不相同。
Program
解题思路:
题目是上一题的扩展,但是有点不同。
由题意可知,每进行一轮操作,石子的左右端点的距离会缩短,一轮一轮收敛。最后会石子都紧邻游戏结束。
举个例子:
初始时有 8 颗石子,在数轴上的有石子的刻度为:
4,6,8,9,15,16,19,20
最大值求解方法:
石子可以放置的空间,等于左右两端石子之间的未占用位置。在例子中,一共有 20-4+1-8 个位置。
石子覆盖的线段长度是 20-4 个,加上一个端点的位置即 20-4+1,再减去已经占用的 8 个位置。
用公式表示为:
$s1=stones[n-1]-stones[0]+1-n$
但是第一次移动的左端点或右端点的石子后,这个移动的石子和它相邻的那颗石子之间的空间,后面就不能被放置了,因为与他相邻的那个点变为端点,他们之间的位置不可以被放置了。
例如第一步移动了 4,那么 5 这个位置就不可能放置石子了。所以要计算不能被访问的空间
$s2=min(stones[n-1]-stones[n-2]-1, stones[1]-stones[0] -1)$
最大值为 s1-s2。因为在后面的步骤里,我们都可以做出策略,让每一轮左右端点的差值只减1。
最小值求解方法:
如果最后游戏结束,那么一定有 n 个连续坐标摆满了石子。如果我们要移动最少,必定要找一个石子序列,使得在 n 大小连续的坐标内,初始时有最多的石子。
设想有个尺子,上面有 n 个刻度点,我们用这个尺子在石子从最左边到最右边移动,每动一次都查看下在尺子范围内有 m 个石子,那么要使这个区间填满,就需要移动 n-m 次。
只要在尺子外部有石子,就有策略填满尺子内的。
这些次数中最小的就为虽少次数。
但是有一种特例:
1,2,3,4,7
这种 1-4 是最好的序列,但是 7 不能移动到端点,只能 1 先移动到 6,然后 7 移动到 5 解决,这种情况要用 2 步。就是尺子内的石子都是连续的,中间没空洞,只在边上有空,要用 2 次。
1 | class Solution { |
1498. 满足条件的子序列数目
Description
给你一个整数数组 nums 和一个整数 target 。
请你统计并返回 nums 中能满足其最小元素与最大元素的 和 小于或等于 target 的 非空 子序列的数目。
由于答案可能很大,请将结果对 10^9 + 7 取余后返回。
Example
示例 1:
输入:nums = [3,5,6,7], target = 9
输出:4
解释:有 4 个子序列满足该条件。
[3] -> 最小元素 + 最大元素 <= target (3 + 3 <= 9)
[3,5] -> (3 + 5 <= 9)
[3,5,6] -> (3 + 6 <= 9)
[3,6] -> (3 + 6 <= 9)
示例 2:
输入:nums = [3,3,6,8], target = 10
输出:6
解释:有 6 个子序列满足该条件。(nums 中可以有重复数字)
[3] , [3] , [3,3], [3,6] , [3,6] , [3,3,6]
示例 3:
输入:nums = [2,3,3,4,6,7], target = 12
输出:61
解释:共有 63 个非空子序列,其中 2 个不满足条件([6,7], [7])
有效序列总数为(63 - 2 = 61)
示例 4:
输入:nums = [5,2,4,1,7,6,8], target = 16
输出:127
解释:所有非空子序列都满足条件 (2^7 - 1) = 127
提示:
1 <= nums.length <= 10^5
1 <= nums[i] <= 10^6
1 <= target <= 10^6
Program
思路
题目要求满足题意的子序列,即子集。
刚开始想通过双端队列,发现不满足滑窗条件,且无法求子集。
看了题目提示后,修改如下,计算2的幂次的时候记得用快速幂,否则还是超时:
(1)排序,如果过大可以忽略后面的数;
(2)滑动窗口找出以i为起点,e为终点的满足条件的最大序列,那么该窗口满足条件的子序列数目为:
$2^{e-i}=1+2^{0}+2^{1]+…+2^{e-i-1}$,
其中每一项表示以最小值的下标i为起点,到最大值下标j的子序列数目,其中$j=i,…,e$
即以[i,j]为满足题意的序列,且以nums[i],nums[j]为最小最大值,那么有$2^{j-i-1}$种可能结果(如果i==j,则为1)。
1 | class Solution { |
剑指 Offer 59 - II. 队列的最大值
Description
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
Example
示例 1:
输入:
[“MaxQueue”,”push_back”,”push_back”,”max_value”,”pop_front”,”max_value”]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]
示例 2:
输入:
[“MaxQueue”,”pop_front”,”max_value”]
[[],[],[]]
输出: [null,-1,-1]
限制:
1 <= push_back,pop_front,max_value的总操作数 <= 10000
1 <= value <= 10^5
Program
双端队列保留队列最大值,思路与滑动窗口最大值相同。
1 | class MaxQueue { |
面试题 17.18. 最短超串
Description
假设你有两个数组,一个长一个短,短的元素均不相同。找到长数组中包含短数组所有的元素的最短子数组,其出现顺序无关紧要。
返回最短子数组的左端点和右端点,如有多个满足条件的子数组,返回左端点最小的一个。若不存在,返回空数组。
Example
示例 1:
输入:
big = [7,5,9,0,2,1,3,5,7,9,1,1,5,8,8,9,7]
small = [1,5,9]
输出: [7,10]
示例 2:
输入:
big = [1,2,3]
small = [4]
输出: []
提示:
big.length <= 100000
1 <= small.length <= 100000
Program
滑动窗口
最近一直在写滑窗题,基本思路清楚,这里有点想歪了,纠结窗口怎么取了,后面看了人家的题解的一句话恍然大悟:窗口包含了small的所有元素就停止扩大窗口!
1 | class Solution { |
链表
24. 两两交换链表中的节点
Description
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
Example
示例:
给定 1->2->3->4, 你应该返回 2->1->4->3.
Program
1 | /** |
61. 旋转链表
Description
给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
Example
示例 1:
输入: 1->2->3->4->5->NULL, k = 2
输出: 4->5->1->2->3->NULL
解释:
向右旋转 1 步: 5->1->2->3->4->NULL
向右旋转 2 步: 4->5->1->2->3->NULL
示例 2:
输入: 0->1->2->NULL, k = 4
输出: 2->0->1->NULL
解释:
向右旋转 1 步: 2->0->1->NULL
向右旋转 2 步: 1->2->0->NULL
向右旋转 3 步: 0->1->2->NULL
向右旋转 4 步: 2->0->1->NULL
Program
1 | /** |
82. 删除排序链表中的重复元素 II
Description
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
Example
示例 1:
输入: 1->2->3->3->4->4->5
输出: 1->2->5
示例 2:
输入: 1->1->1->2->3
输出: 2->3
Program
1 | /** |
86. 分隔链表
Description
给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。
你应当保留两个分区中每个节点的初始相对位置。
Example
示例:
输入: head = 1->4->3->2->5->2, x = 3
输出: 1->2->2->4->3->5
Program
1 | /** |
92. 反转链表 II
Description
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明:
1 ≤ m ≤ n ≤ 链表长度。
Example
示例:
输入: 1->2->3->4->5->NULL, m = 2, n = 4
输出: 1->4->3->2->5->NULL
Program
1 | /** |
142. 环形链表 II
Description
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
Example
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:tail connects to node index 0
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:no cycle
解释:链表中没有环。
进阶:
你是否可以不用额外空间解决此题?
Program
1 | /** |
1 | /** |
143. 重排链表
Description
给定一个单链表 L:L0→L1→…→Ln-1→Ln ,
将其重新排列后变为: L0→Ln→L1→Ln-1→L2→Ln-2→…
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
Example
示例 1:
给定链表 1->2->3->4, 重新排列为 1->4->2->3.
示例 2:
给定链表 1->2->3->4->5, 重新排列为 1->5->2->4->3.
Program
1 | /** |
234. 回文链表
Description
请判断一个链表是否为回文链表。
Example
示例 1:
输入: 1->2
输出: false
示例 2:
输入: 1->2->2->1
输出: true
进阶:
你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
Program
1 | /** |
237. 删除链表中的节点
Description
请编写一个函数,使其可以删除某个链表中给定的(非末尾)节点,你将只被给定要求被删除的节点。
现有一个链表 – head = [4,5,1,9],它可以表示为:
示例 1:
输入: head = [4,5,1,9], node = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], node = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
链表至少包含两个节点。
链表中所有节点的值都是唯一的。
给定的节点为非末尾节点并且一定是链表中的一个有效节点。
不要从你的函数中返回任何结果。
Program
1 | /** |
328. 奇偶链表
Description
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
Example
示例 1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
示例 2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
说明:
应当保持奇数节点和偶数节点的相对顺序。
链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。
Program
1 | /** |
430. 扁平化多级双向链表
Description
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
Example
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:
输入的多级列表如下图所示: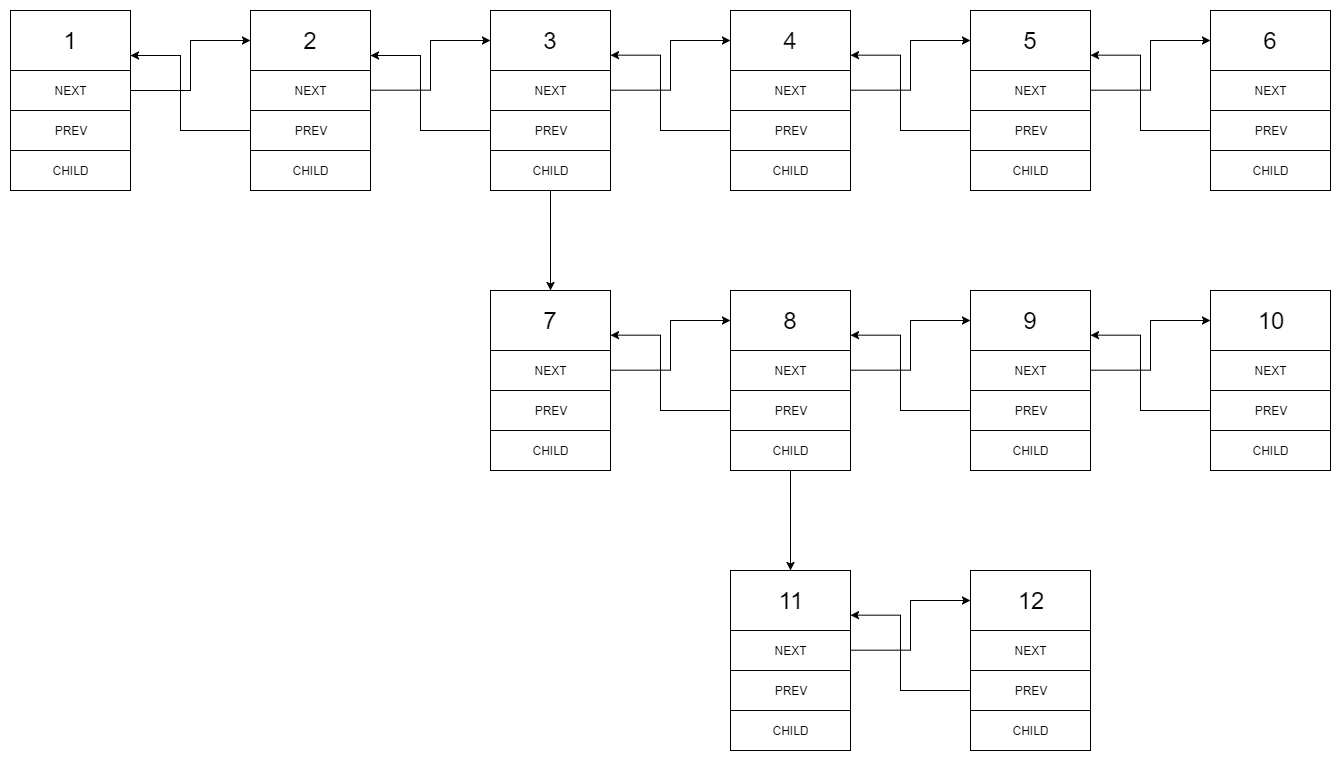
扁平化后的链表如下图:
示例 2:
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:
输入的多级列表如下图所示:
1 | 1---2---NULL |
示例 3:
输入:head = []
输出:[]
如何表示测试用例中的多级链表?
以 示例 1 为例:
1 | 1---2---3---4---5---6--NULL |
序列化其中的每一级之后:
[1,2,3,4,5,6,null]
[7,8,9,10,null]
[11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null]
[null,null,7,8,9,10,null]
[null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
提示:
节点数目不超过 1000
1 <= Node.val <= 10^5
Program
1 | /* |
445. 两数相加 II
Description
给你两个 非空 链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
进阶:
如果输入链表不能修改该如何处理?换句话说,你不能对列表中的节点进行翻转。
Example
示例:
输入:(7 -> 2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 8 -> 0 -> 7
Program
思路
栈
1 | /** |
725. 分隔链表
Description
给定一个头结点为 root 的链表, 编写一个函数以将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等: 任意两部分的长度差距不能超过 1,也就是说可能有些部分为 null。
这k个部分应该按照在链表中出现的顺序进行输出,并且排在前面的部分的长度应该大于或等于后面的长度。
返回一个符合上述规则的链表的列表。
举例: 1->2->3->4, k = 5 // 5 结果 [ [1], [2], [3], [4], null ]
Example
示例 1:
输入:
root = [1, 2, 3], k = 5
输出: [[1],[2],[3],[],[]]
解释:
输入输出各部分都应该是链表,而不是数组。
例如, 输入的结点 root 的 val= 1, root.next.val = 2, \root.next.next.val = 3, 且 root.next.next.next = null。
第一个输出 output[0] 是 output[0].val = 1, output[0].next = null。
最后一个元素 output[4] 为 null, 它代表了最后一个部分为空链表。
示例 2:
输入:
root = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], k = 3
输出: [[1, 2, 3, 4], [5, 6, 7], [8, 9, 10]]
解释:
输入被分成了几个连续的部分,并且每部分的长度相差不超过1.前面部分的长度大于等于后面部分的长度。
提示:
root 的长度范围: [0, 1000].
输入的每个节点的大小范围:[0, 999].
k 的取值范围: [1, 50].
Program
1 | /** |
876. 链表的中间结点
Description
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
Example
示例 1:
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
示例 2:
输入:[1,2,3,4,5,6]
输出:此列表中的结点 4 (序列化形式:[4,5,6])
由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
提示:
给定链表的结点数介于 1 和 100 之间。
Program
1 | /** |
1171. 从链表中删去总和值为零的连续节点
Description
给你一个链表的头节点 head,请你编写代码,反复删去链表中由 总和 值为 0 的连续节点组成的序列,直到不存在这样的序列为止。
删除完毕后,请你返回最终结果链表的头节点。
你可以返回任何满足题目要求的答案。
(注意,下面示例中的所有序列,都是对 ListNode 对象序列化的表示。)
Example
示例 1:
输入:head = [1,2,-3,3,1]
输出:[3,1]
提示:答案 [1,2,1] 也是正确的。
示例 2:
输入:head = [1,2,3,-3,4]
输出:[1,2,4]
示例 3:
输入:head = [1,2,3,-3,-2]
输出:[1]
提示:
给你的链表中可能有 1 到 1000 个节点。
对于链表中的每个节点,节点的值:-1000 <= node.val <= 1000.
Program
1 | /** |
面试题 02.01. 移除重复节点
Description
编写代码,移除未排序链表中的重复节点。保留最开始出现的节点。
Example
示例1:
输入:[1, 2, 3, 3, 2, 1]
输出:[1, 2, 3]
示例2:
输入:[1, 1, 1, 1, 2]
输出:[1, 2]
提示:
链表长度在[0, 20000]范围内。
链表元素在[0, 20000]范围内。
进阶:
如果不得使用临时缓冲区,该怎么解决?
Program
1 | /** |
面试题 02.08. 环路检测
Description
给定一个链表,如果它是有环链表,实现一个算法返回环路的开头节点。
有环链表的定义:在链表中某个节点的next元素指向在它前面出现过的节点,则表明该链表存在环路。
Example
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:tail connects to node index 0
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:no cycle
解释:链表中没有环。
进阶:
你是否可以不用额外空间解决此题?
Program
1 | /** |
剑指 Offer 52. 两个链表的第一个公共节点
Description
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
在节点 c1 开始相交。
Example
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
Program
思路
(1)若存在交点,那么链表A结尾与链表B头链接,链表B结尾与链表A头链接,那么元素节点数一直,双指针一定能够到达同一个点,这个点就是交点!
(2)若不存在交点,那么上述链接一定不会相交,此时应当进行判断!记录双指针到达各自尾节点时的尾节点是否一致即可!
1 | /** |
设计
146. LRU缓存机制
Description
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
Example
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 / );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得关键字 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得关键字 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
*Program**
思路
(1)用双向链表进行存储最近使用的节点,最近使用的节点考前,最近最少使用的在末尾
(2)HashMap存储key对应的节点位置;
get方法:
- 如果链表为空或未找到,返回-1;
- 如果找到,则需要将key节点移至链表头;
put方法: - 如果链表不存在key:①链表满,则应当剔除末尾节点,但是更好的做法就是讲末尾节点的key和value更新为最新值,然后移至链表头;②未满,新建节点,移至链表头
- 如果链表已存在key,则更新value,且移至链表头;
注意:以下代码没有多余头结点,故注意头指针指向当前m[key]的时候,不要移动!因为需要移动的话需要将前后两个节点相连,但是head也随着变化了!
1 | class LRUCache { |
双端双向链表
简化,双向链表即可,且带有头尾两个伪节点!
1 | class LRUCache { |
170. 两数之和 III - 数据结构设计
Description
设计并实现一个 TwoSum 的类,使该类需要支持 add 和 find 的操作。
- add 操作 - 对内部数据结构增加一个数。
- find 操作 - 寻找内部数据结构中是否存在一对整数,使得两数之和与给定的数相等。
Example
示例 1:
add(1); add(3); add(5);
find(4) -> true
find(7) -> false
示例 2:
add(3); add(1); add(2);
find(3) -> true
find(6) -> false
Program
1 | class TwoSum { |
173. 二叉搜索树迭代器
Description
实现一个二叉搜索树迭代器。你将使用二叉搜索树的根节点初始化迭代器。
调用 next() 将返回二叉搜索树中的下一个最小的数。
Example
示例:
BSTIterator iterator = new BSTIterator(root);
iterator.next(); // 返回 3
iterator.next(); // 返回 7
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 9
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 15
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 20
iterator.hasNext(); // 返回 false
提示:
next() 和 hasNext() 操作的时间复杂度是 O(1),并使用 O(h) 内存,其中 h 是树的高度。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 中至少存在一个下一个最小的数。
Program
平均时间复杂度O(1)!题目没讲清楚。
1 | /** |
208. 实现 Trie (前缀树)
Description
实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。
Example
示例:
Trie trie = new Trie();
trie.insert(“apple”);
trie.search(“apple”); // 返回 true
trie.search(“app”); // 返回 false
trie.startsWith(“app”); // 返回 true
trie.insert(“app”);
trie.search(“app”); // 返回 true
说明:
你可以假设所有的输入都是由小写字母 a-z 构成的。
保证所有输入均为非空字符串。
Program
1 | class Trie { |
211. 添加与搜索单词 - 数据结构设计
Description
设计一个支持以下两种操作的数据结构:
- void addWord(word)
- bool search(word)
- search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母 . 或 a-z 。 . 可以表示任何一个字母。
Example
示例:
addWord(“bad”)
addWord(“dad”)
addWord(“mad”)
search(“pad”) -> false
search(“bad”) -> true
search(“.ad”) -> true
search(“b..”) -> true
说明:
你可以假设所有单词都是由小写字母 a-z 组成的。
program
字典树+递归
关键就是在于search方法对于正则匹配的问题,遇到’.’则尝试接下来26个字母的可能,如果其中一种可达true,则不再继续,或者当所有都不可达,则返回false。
1 | class WordDictionary { |
232. 用栈实现队列
Description
使用栈实现队列的下列操作:
- push(x) – 将一个元素放入队列的尾部。
- pop() – 从队列首部移除元素。
- peek() – 返回队列首部的元素。
- empty() – 返回队列是否为空。
Example
示例:
MyQueue queue = new MyQueue();
queue.push(1);
queue.push(2);
queue.peek(); // 返回 1
queue.pop(); // 返回 1
queue.empty(); // 返回 false
说明:
你只能使用标准的栈操作 – 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
Program
1 | class MyQueue { |
284. 顶端迭代器
Description
给定一个迭代器类的接口,接口包含两个方法: next() 和 hasNext()。设计并实现一个支持 peek() 操作的顶端迭代器 – 其本质就是把原本应由 next() 方法返回的元素 peek() 出来。
Example
示例:
假设迭代器被初始化为列表 [1,2,3]。
调用 next() 返回 1,得到列表中的第一个元素。
现在调用 peek() 返回 2,下一个元素。在此之后调用 next() 仍然返回 2。
最后一次调用 next() 返回 3,末尾元素。在此之后调用 hasNext() 应该返回 false。
进阶:你将如何拓展你的设计?使之变得通用化,从而适应所有的类型,而不只是整数型?
Program
1 | /* |
341. 扁平化嵌套列表迭代器
Description
给你一个嵌套的整型列表。请你设计一个迭代器,使其能够遍历这个整型列表中的所有整数。
列表中的每一项或者为一个整数,或者是另一个列表。其中列表的元素也可能是整数或是其他列表。
Example
示例 1:
输入: [[1,1],2,[1,1]]
输出: [1,1,2,1,1]
解释: 通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,1,2,1,1]。
示例 2:
输入: [1,[4,[6]]]
输出: [1,4,6]
解释: 通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,4,6]。
Program
1 | /** |
355. 设计推特
Description
设计一个简化版的推特(Twitter),可以让用户实现发送推文,关注/取消关注其他用户,能够看见关注人(包括自己)的最近十条推文。你的设计需要支持以下的几个功能:
- postTweet(userId, tweetId): 创建一条新的推文
- getNewsFeed(userId): 检索最近的十条推文。每个推文都必须是由此用户关注的人或者是用户自己发出的。推文必须按照时间顺序由最近的开始排序。
- follow(followerId, followeeId): 关注一个用户
- unfollow(followerId, followeeId): 取消关注一个用户
Example
示例:
Twitter twitter = new Twitter();
// 用户1发送了一条新推文 (用户id = 1, 推文id = 5).
twitter.postTweet(1, 5);
// 用户1的获取推文应当返回一个列表,其中包含一个id为5的推文.
twitter.getNewsFeed(1);
// 用户1关注了用户2.
twitter.follow(1, 2);
// 用户2发送了一个新推文 (推文id = 6).
twitter.postTweet(2, 6);
// 用户1的获取推文应当返回一个列表,其中包含两个推文,id分别为 -> [6, 5].
// 推文id6应当在推文id5之前,因为它是在5之后发送的.
twitter.getNewsFeed(1);
// 用户1取消关注了用户2.
twitter.unfollow(1, 2);
// 用户1的获取推文应当返回一个列表,其中包含一个id为5的推文.
// 因为用户1已经不再关注用户2.
twitter.getNewsFeed(1);
Program
思路
用户类:关注者集合,推文链表(最近的发文靠前)
关键在于拉取推文:需要合并两个链表,最多recentMax=10条!多了肯定不会是他。
1 | class Twitter { |
497. 非重叠矩形中的随机点
Description
给定一个非重叠轴对齐矩形的列表 rects,写一个函数 pick 随机均匀地选取矩形覆盖的空间中的整数点。
提示:
整数点是具有整数坐标的点。
矩形周边上的点包含在矩形覆盖的空间中。
第 i 个矩形 rects [i] = [x1,y1,x2,y2],其中 [x1,y1] 是左下角的整数坐标,[x2,y2] 是右上角的整数坐标。
每个矩形的长度和宽度不超过 2000。
1 <= rects.length <= 100
pick 以整数坐标数组 [p_x, p_y] 的形式返回一个点。
pick 最多被调用10000次。
Example
示例 1:
输入:
[“Solution”,”pick”,”pick”,”pick”]
[[[[1,1,5,5]]],[],[],[]]
输出:
[null,[4,1],[4,1],[3,3]]
示例 2:
输入:
[“Solution”,”pick”,”pick”,”pick”,”pick”,”pick”]
[[[[-2,-2,-1,-1],[1,0,3,0]]],[],[],[],[],[]]
输出:
[null,[-1,-2],[2,0],[-2,-1],[3,0],[-2,-2]]
输入语法的说明:
输入是两个列表:调用的子例程及其参数。Solution 的构造函数有一个参数,即矩形数组 rects。pick 没有参数。参数总是用列表包装的,即使没有也是如此。
Program
思路
(1)若干个矩形,总共ans个点,利用均匀分布生成随机数idx表示选取ans个点中的第idx个(从1开始),那么需要判断第idx个点在哪个矩形上,通过二分查找$preSum[i-1]<idx<=preSum[i]$,即找到第一个不比idx小的矩形(preSum[i]表示前i个矩形的整点数目);
(2)确定好之后,需要判断第idx点为矩形上的第几个点,可以将矩形从下到上,从左到右依次编号,0,…,n-1,n为矩形的整点个数,那么$id_{rect}=(idx-1-preSum[i-1])$为选中的第i个矩形上的id_{rect}个点(-1表示下标从0开始,方便后面模和除法运算);
(3)最终坐标:$x_{res}=rects[i][0]+id_{rect}, mod , (rects[i][2]-rects[i][0]),y_{res}=rects[i][1]+id_{rect} / (rects[i][2]-rects[i][0])$
1 | class Solution { |
622. 设计循环队列
Description
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
你的实现应该支持如下操作:
MyCircularQueue(k): 构造器,设置队列长度为 k 。
Front: 从队首获取元素。如果队列为空,返回 -1 。
Rear: 获取队尾元素。如果队列为空,返回 -1 。
enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。
deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。
isEmpty(): 检查循环队列是否为空。
isFull(): 检查循环队列是否已满。
示例:
1 | MyCircularQueue circularQueue = new MyCircularQueue(3); // 设置长度为 3 |
提示:
所有的值都在 0 至 1000 的范围内;
操作数将在 1 至 1000 的范围内;
请不要使用内置的队列库。
Program
1 | class MyCircularQueue { |
641. 设计循环双端队列
Description
设计实现双端队列。
你的实现需要支持以下操作:
MyCircularDeque(k):构造函数,双端队列的大小为k。
insertFront():将一个元素添加到双端队列头部。 如果操作成功返回 true。
insertLast():将一个元素添加到双端队列尾部。如果操作成功返回 true。
deleteFront():从双端队列头部删除一个元素。 如果操作成功返回 true。
deleteLast():从双端队列尾部删除一个元素。如果操作成功返回 true。
getFront():从双端队列头部获得一个元素。如果双端队列为空,返回 -1。
getRear():获得双端队列的最后一个元素。 如果双端队列为空,返回 -1。
isEmpty():检查双端队列是否为空。
isFull():检查双端队列是否满了。
Example
示例:
MyCircularDeque circularDeque = new MycircularDeque(3); // 设置容量大小为3
circularDeque.insertLast(1); // 返回 true
circularDeque.insertLast(2); // 返回 true
circularDeque.insertFront(3); // 返回 true
circularDeque.insertFront(4); // 已经满了,返回 false
circularDeque.getRear(); // 返回 2
circularDeque.isFull(); // 返回 true
circularDeque.deleteLast(); // 返回 true
circularDeque.insertFront(4); // 返回 true
circularDeque.getFront(); // 返回 4
提示:
所有值的范围为 [1, 1000]
操作次数的范围为 [1, 1000]
请不要使用内置的双端队列库。
Program
1 | class MyCircularDeque { |
703. 数据流中的第K大元素
Description
设计一个找到数据流中第K大元素的类(class)。注意是排序后的第K大元素,不是第K个不同的元素。
你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第K大的元素。
Example
示例:
int k = 3;
int[] arr = [4,5,8,2];
KthLargest kthLargest = new KthLargest(3, arr);
kthLargest.add(3); // returns 4
kthLargest.add(5); // returns 5
kthLargest.add(10); // returns 5
kthLargest.add(9); // returns 8
kthLargest.add(4); // returns 8
说明:
你可以假设 nums 的长度≥ k-1 且k ≥ 1。
Program
1 | class KthLargest { |
707. 设计链表
Description
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
- get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
- addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
- addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
- addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
- deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
Example
示例:
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3
linkedList.get(1); //返回2
linkedList.deleteAtIndex(1); //现在链表是1-> 3
linkedList.get(1); //返回3
提示:
所有val值都在 [1, 1000] 之内。
操作次数将在 [1, 1000] 之内。
请不要使用内置的 LinkedList 库。
Program
1 | class MyLinkedList { |
981. 基于时间的键值存储
Description
创建一个基于时间的键值存储类 TimeMap,它支持下面两个操作:
- set(string key, string value, int timestamp)
存储键 key、值 value,以及给定的时间戳 timestamp。 - get(string key, int timestamp)
返回先前调用 set(key, value, timestamp_prev) 所存储的值,其中 timestamp_prev <= timestamp。
如果有多个这样的值,则返回对应最大的 timestamp_prev 的那个值。
如果没有值,则返回空字符串(””)。
Example
示例 1:
输入:inputs = [“TimeMap”,”set”,”get”,”get”,”set”,”get”,”get”], inputs = [[],[“foo”,”bar”,1],[“foo”,1],[“foo”,3],[“foo”,”bar2”,4],[“foo”,4],[“foo”,5]]
输出:[null,null,”bar”,”bar”,null,”bar2”,”bar2”]
解释:
TimeMap kv;
kv.set(“foo”, “bar”, 1); // 存储键 “foo” 和值 “bar” 以及时间戳 timestamp = 1
kv.get(“foo”, 1); // 输出 “bar”
kv.get(“foo”, 3); // 输出 “bar” 因为在时间戳 3 和时间戳 2 处没有对应 “foo” 的值,所以唯一的值位于时间戳 1 处(即 “bar”)
kv.set(“foo”, “bar2”, 4);
kv.get(“foo”, 4); // 输出 “bar2”
kv.get(“foo”, 5); // 输出 “bar2”
示例 2:
输入:inputs = [“TimeMap”,”set”,”set”,”get”,”get”,”get”,”get”,”get”], inputs = [[],[“love”,”high”,10],[“love”,”low”,20],[“love”,5],[“love”,10],[“love”,15],[“love”,20],[“love”,25]]
输出:[null,null,null,””,”high”,”high”,”low”,”low”]
提示:
所有的键/值字符串都是小写的。
所有的键/值字符串长度都在 [1, 100] 范围内。
所有 TimeMap.set 操作中的时间戳 timestamps 都是严格递增的。
1 <= timestamp <= 10^7
TimeMap.set 和 TimeMap.get 函数在每个测试用例中将(组合)调用总计 120000 次。
Program
哈希+二分
首先key值可以对应多个键值、时间戳,而时间戳timestamps是唯一的,即时间戳对应唯一的(key,value)
所以设置哈希sTov存储键值对应的时间戳,设置哈希tTos存储时间戳timestamps对应的value值
(1)set中只需要分别更新两个哈希表即可;
(2)get中先在sTov查找是否存在键值key,如果不存在,直接返回空字符串;否则,对sTov[key],即vector数组进行二分查找是否存在小于等于timestamps的最大时间戳即可;
时间复杂度:$O(n\log{T})$,其中$n$为get的调用次数,而$T$为timestamp的范围。
1 | class TimeMap { |
1286. 字母组合迭代器
Description
请你设计一个迭代器类,包括以下内容:
一个构造函数,输入参数包括:一个 有序且字符唯一 的字符串 characters(该字符串只包含小写英文字母)和一个数字 combinationLength 。
函数 next() ,按 字典序 返回长度为 combinationLength 的下一个字母组合。
函数 hasNext() ,只有存在长度为 combinationLength 的下一个字母组合时,才返回 True;否则,返回 False。
Example
示例:
CombinationIterator iterator = new CombinationIterator(“abc”, 2); // 创建迭代器 iterator
iterator.next(); // 返回 “ab”
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 “ac”
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 “bc”
iterator.hasNext(); // 返回 false
提示:
1 <= combinationLength <= characters.length <= 15
每组测试数据最多包含 10^4 次函数调用。
题目保证每次调用函数 next 时都存在下一个字母组合。
Program
二进制编码
利用二进制进行全排列选择长度满足要求的组合字符串,然后进行排序。
1 | class CombinationIterator { |
面试题 03.01. 三合一
Description
三合一。描述如何只用一个数组来实现三个栈。
你应该实现push(stackNum, value)、pop(stackNum)、isEmpty(stackNum)、peek(stackNum)方法。stackNum表示栈下标,value表示压入的值。
构造函数会传入一个stackSize参数,代表每个栈的大小。
Example
示例1:
输入:
[“TripleInOne”, “push”, “push”, “pop”, “pop”, “pop”, “isEmpty”]
[[1], [0, 1], [0, 2], [0], [0], [0], [0]]
输出:
[null, null, null, 1, -1, -1, true]
说明:当栈为空时pop, peek返回-1,当栈满时push不压入元素。
示例2:
输入:
[“TripleInOne”, “push”, “push”, “push”, “pop”, “pop”, “pop”, “peek”]
[[2], [0, 1], [0, 2], [0, 3], [0], [0], [0], [0]]
输出:
[null, null, null, null, 2, 1, -1, -1]
Program
1 | class TripleInOne { |
面试题 03.06. 动物收容所
Description
动物收容所。有家动物收容所只收容狗与猫,且严格遵守“先进先出”的原则。在收养该收容所的动物时,收养人只能收养所有动物中“最老”(由其进入收容所的时间长短而定)的动物,或者可以挑选猫或狗(同时必须收养此类动物中“最老”的)。换言之,收养人不能自由挑选想收养的对象。请创建适用于这个系统的数据结构,实现各种操作方法,比如enqueue、dequeueAny、dequeueDog和dequeueCat。允许使用Java内置的LinkedList数据结构。
- enqueue方法有一个animal参数,animal[0]代表动物编号,animal[1]代表动物种类,其中 0 代表猫,1 代表狗。
- dequeue*方法返回一个列表[动物编号, 动物种类],若没有可以收养的动物,则返回[-1,-1]。
Example
示例1:
输入:
[“AnimalShelf”, “enqueue”, “enqueue”, “dequeueCat”, “dequeueDog”, “dequeueAny”]
[[], [[0, 0]], [[1, 0]], [], [], []]
输出:
[null,null,null,[0,0],[-1,-1],[1,0]]
示例2:
输入:
[“AnimalShelf”, “enqueue”, “enqueue”, “enqueue”, “dequeueDog”, “dequeueCat”, “dequeueAny”]
[[], [[0, 0]], [[1, 0]], [[2, 1]], [], [], []]
输出:
[null,null,null,null,[2,1],[0,0],[1,0]]
说明:
收纳所的最大容量为20000
Program
1 | class AnimalShelf { |
面试题 16.25. LRU缓存
Description
设计和构建一个“最近最少使用”缓存,该缓存会删除最近最少使用的项目。缓存应该从键映射到值(允许你插入和检索特定键对应的值),并在初始化时指定最大容量。当缓存被填满时,它应该删除最近最少使用的项目。
它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
Example
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 / );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
*Program**
1 | class LRUCache { |
搜索
常规题
329. 矩阵中的最长递增路径
Description
给定一个整数矩阵,找出最长递增路径的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外(即不允许环绕)。
Example
示例 1:
输入: nums =
[
[9,9,4],
[6,6,8],
[2,1,1]
]
输出: 4
解释: 最长递增路径为 [1, 2, 6, 9]。
示例 2:
输入: nums =
[
[3,4,5],
[3,2,6],
[2,2,1]
]
输出: 4
解释: 最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
Program
记忆化深搜
dfs(i,j)求得当前起始的最大递增长度
时间复杂度:$O(mn)$,朴素深搜时间复杂度$O(V+E)$,$V=mn$,$E≈4mn$
1 | class Solution { |
拓扑排序
可以考虑动规,DP[i][j]=max(DP[x][y])+1,即与i,j相邻的四个方向x,y,但是不好DP,可以先将所有点从大到小排序,然后进行状态转移,但是时间复杂度$O(mn\log{mn})$
这里使用拓扑排序,计算每个点的出度,出度为0的点加入队列进行拓扑排序,然后更新其相邻的节点,广搜的层数就是最终答案。
时间复杂度:$O(mn)$
1 | class Solution { |
入度同理
1 | class Solution { |
851. 喧闹和富有
Description
在一组 N 个人(编号为 0, 1, 2, …, N-1)中,每个人都有不同数目的钱,以及不同程度的安静(quietness)。
为了方便起见,我们将编号为 x 的人简称为 “person x “。
如果能够肯定 person x 比 person y 更有钱的话,我们会说 richer[i] = [x, y] 。注意 richer 可能只是有效观察的一个子集。
另外,如果 person x 的安静程度为 q ,我们会说 quiet[x] = q 。
现在,返回答案 answer ,其中 answer[x] = y 的前提是,在所有拥有的钱不少于 person x 的人中,person y 是最安静的人(也就是安静值 quiet[y] 最小的人)。
Example
示例:
输入:richer = [[1,0],[2,1],[3,1],[3,7],[4,3],[5,3],[6,3]], quiet = [3,2,5,4,6,1,7,0]
输出:[5,5,2,5,4,5,6,7]
解释:
answer[0] = 5,
person 5 比 person 3 有更多的钱,person 3 比 person 1 有更多的钱,person 1 比 person 0 有更多的钱。
唯一较为安静(有较低的安静值 quiet[x])的人是 person 7,
但是目前还不清楚他是否比 person 0 更有钱。
answer[7] = 7,
在所有拥有的钱肯定不少于 person 7 的人中(这可能包括 person 3,4,5,6 以及 7),
最安静(有较低安静值 quiet[x])的人是 person 7。
其他的答案也可以用类似的推理来解释。
提示:
1 <= quiet.length = N <= 500
0 <= quiet[i] < N,所有 quiet[i] 都不相同。
0 <= richer.length <= N * (N-1) / 2
0 <= richer[i][j] < N
richer[i][0] != richer[i][1]
richer[i] 都是不同的。
对 richer 的观察在逻辑上是一致的。
Program
记忆化搜索思路
(1)邻接表记录比u富有的所有编号v(不包括自己);
(2)记忆化搜索记录比u富有的最安静值及其编号;
1 | class Solution { |
拓扑排序
(1)构建邻接表Adj[u]记录所有比u穷的v;
(2)res[u]记录u的所有前导节点(所有祖先节点)的最小安静值编号;
1 | class Solution { |
回溯算法
17. 电话号码的字母组合
Description
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
Example
示例:
输入:”23”
输出:[“ad”, “ae”, “af”, “bd”, “be”, “bf”, “cd”, “ce”, “cf”].
说明:
尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
Program
1 | class Solution { |
22. 括号生成
Description
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
Example
示例:
输入:n = 3
输出:[
“((()))”,
“(()())”,
“(())()”,
“()(())”,
“()()()”
]
Program
回溯
dfs(lb,rb),lb,rb分别表示当前左右括号数目
- 当lb==rb==n时,就得到目标组合;
- 如果lb==rb!=n,那么此时只能增加左括号
- 如果lb>rb,那么可以增加左括号(lb<n时),也可以增加右括号
整个过程lb不会超过n,rb不会超过lb,当然不会超过n了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Solution {
public:
string str;
int nCount;
vector<string> res;
void dfs(int lbrackets, int rbrackets){
if(lbrackets==rbrackets&&lbrackets==nCount){
res.push_back(str);
return;
}
if(lbrackets==rbrackets){
str+='(';
dfs(lbrackets+1, rbrackets);
str.erase(str.length()-1, 1);
}else{
if(lbrackets<nCount){
str+='(';
dfs(lbrackets+1, rbrackets);
str.erase(str.length()-1, 1);
}
str+=')';
dfs(lbrackets, rbrackets+1);
str.erase(str.length()-1, 1);
}
}
vector<string> generateParenthesis(int n) {
nCount=n;
dfs(0, 0);
return res;
}
};37. 解数独
Description
编写一个程序,通过已填充的空格来解决数独问题。
一个数独的解法需遵循如下规则:
- 数字 1-9 在每一行只能出现一次。
- 数字 1-9 在每一列只能出现一次。
- 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。
空白格用 ‘.’ 表示。
一个数独。
答案被标成红色。
Note:
给定的数独序列只包含数字 1-9 和字符 ‘.’ 。
你可以假设给定的数独只有唯一解。
给定数独永远是 9x9 形式的。
Program
回溯
分别用三个数组进行行、列、九宫格标记
时间复杂度:$O((9!)^9)$,一行最多$9!$,总共9个九宫格。
空间复杂度:$O{1}$,确切的9*9级别。
1 | class Solution { |
39. 组合总和
Description
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
所有数字(包括 target)都是正整数。
解集不能包含重复的组合。
Example
示例 1:
输入:candidates = [2,3,6,7], target = 7,
所求解集为:
[
[7],
[2,2,3]
]
示例 2:
输入:candidates = [2,3,5], target = 8,
所求解集为:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
提示:
1 <= candidates.length <= 30
1 <= candidates[i] <= 200
candidate 中的每个元素都是独一无二的。
1 <= target <= 500
Program
深搜
类似于多叉树搜索,这里使用递增排序,否则可以通过画图发现例如[2,3,5],target=7,会出现{2,2,3},{2,3,2},即选择当前元素会出现比之前已选择的元素小,
这种情况会出现重复,所以已经搜索过的不在搜索可以避免了这种问题,即设置start避免重复。
画出图以后,我看了一下,我这张图画出的结果有 44 个 00,对应的路径是 [[2, 2, 3], [2, 3, 2], [3, 2, 2], [7]],而示例中的解集只有 [[7], [2, 2, 3]],很显然,重复的原因是在较深层的结点值考虑了之前考虑过的元素,因此我们需要设置“下一轮搜索的起点”即可。
1 | class Solution { |
40. 组合总和 II
Description
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明:
所有数字(包括目标数)都是正整数。
解集不能包含重复的组合。
Example
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
所求解集为:
[
[1, 7],
[1, 2, 5],
[2, 6],
[1, 1, 6]
]
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
所求解集为:
[
[1,2,2],
[5]
]
Program
回溯+剪枝
在上一题的避免重复的基础上,本题由于存在重复元素,根据上图所示同一层如果存在重复,只取一个即可!
1 | class Solution { |
46. 全排列
Description
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
Example
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]
Program
1 | class Solution { |
47. 全排列 II
Description
给定一个可包含重复数字的序列,返回所有不重复的全排列。
Example
示例:
输入: [1,1,2]
输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
]
Program
思路
首先画出dfs多叉树图,可以发现同一层次如果使用同一元素多次就会产生重复!
1 | class Solution { |
51. N 皇后
Description
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
Example
示例:
输入:4
输出:
1 | [ |
解释: 4 皇后问题存在两个不同的解法。
提示:
皇后彼此不能相互攻击,也就是说:任何两个皇后都不能处于同一条横行、纵行或斜线上。
Program
回溯
(1)首先,对于第k行,我们需要遍历n列位置是否可以放置皇后,这里就需要之前k(从0开始)个皇后的位置queens;
(2)queens[i]表示第i行的皇后的列位置,有了queens就不需要列标记数组了,因为每次判断第k行的皇后位置时,都需要与之前的k个已放置皇后进行比较,列不冲突直接queens[j]==i即表示列冲突,abs(queens[j]-i)==abs(j-k)即表示斜线冲突;
时间复杂度:$O(n!)$
空间复杂度:$O(n)$
1 | class Solution { |
第二版
(1)col[i]记录每一列;
(2)primary_diagonal[i]记录每一个主对角线,我们将左下角作为第一条主对角线,索引为0,那么对于[i,j]来说,其对应的主对角线下标为[j-i+n-1];
(2)secondary_diagonal[i]记录每一个副对角线,我们将左上角作为第一条副对角线,索引为0,那么对于[i,j]来说,其对应的副对角线下标为[i+j];
1 | class Solution { |
52. N皇后 II
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回 n 皇后不同的解决方案的数量。
Example
示例:
输入: 4
输出: 2
解释: 4 皇后问题存在如下两个不同的解法。
1 | [ |
提示:
皇后,是国际象棋中的棋子,意味着国王的妻子。皇后只做一件事,那就是“吃子”。当她遇见可以吃的棋子时,就迅速冲上去吃掉棋子。当然,她横、竖、斜都可走一或 N-1 步,可进可退。(引用自 百度百科 - 皇后 )
Program
1 | class Solution { |
60. 第k个排列
Description
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
“123”
“132”
“213”
“231”
“312”
“321”
给定 n 和 k,返回第 k 个排列。
说明:
- 给定 n 的范围是 [1, 9]。
- 给定 k 的范围是[1, n!]。
Example
示例 1:
输入: n = 3, k = 3
输出: “213”
示例 2:
输入: n = 4, k = 9
输出: “2314”
Program
回溯+剪枝
普通全排列的方法肯定超时,考虑如何剪枝,考虑每一层未选择的数字个数的阶乘cnt,
如果cnt<k,说明该分治不能得到答案,k-=cnt;
如果cnt>=k,说明在本分支内,进入下一层;
只要找到答案就不需要回溯!再次剪枝。
时间复杂度:$O(n^2)$,最差时间复杂度下是查找第n!个排列,第一层比较n-1次,第二层n-2次,…,以此类推。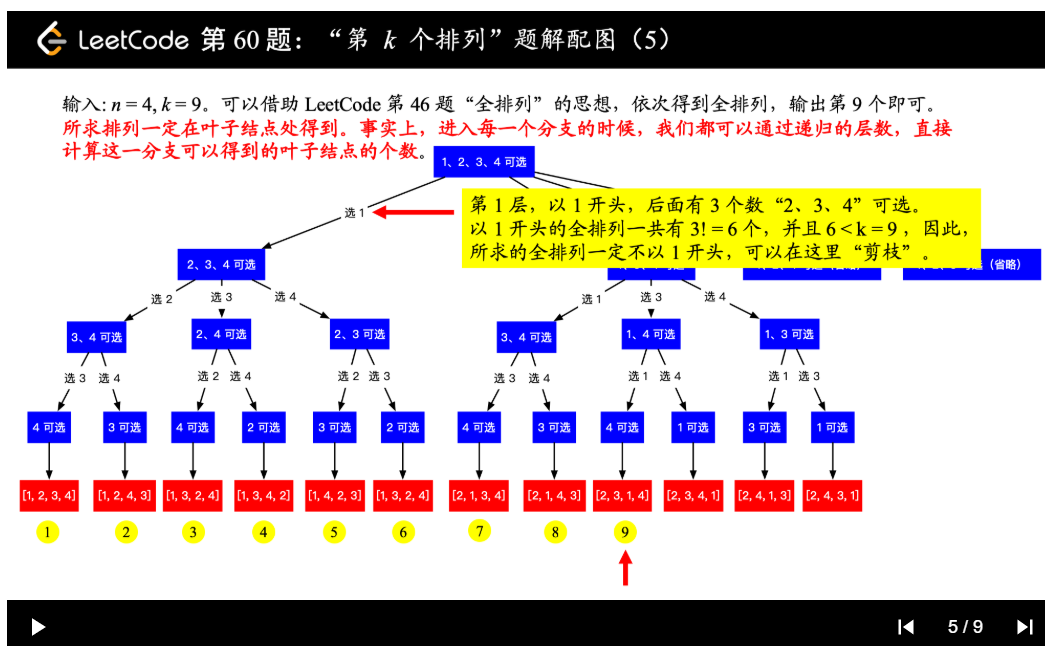
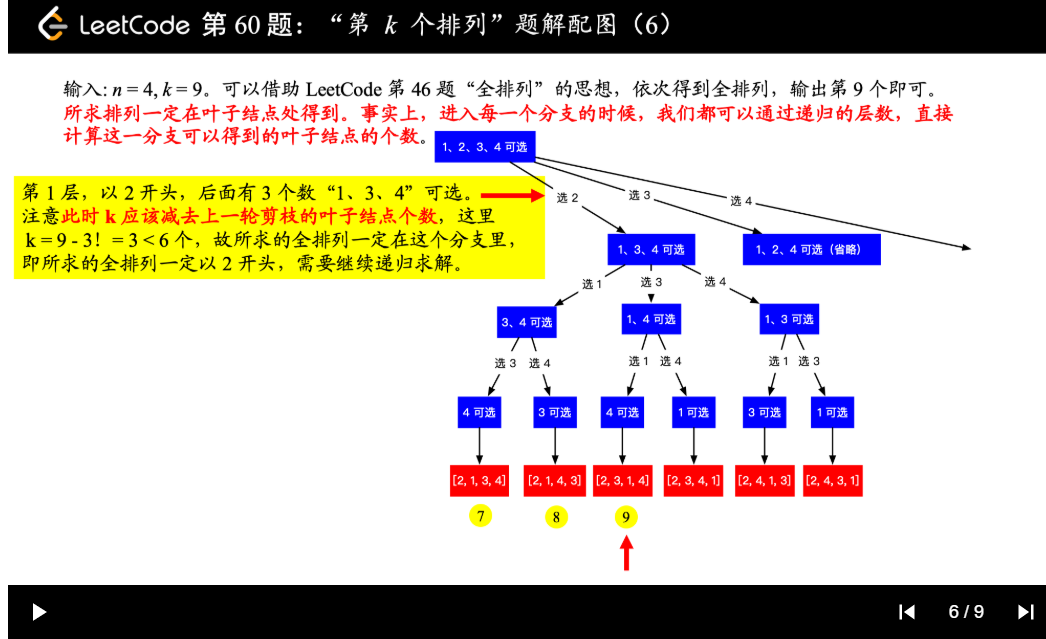
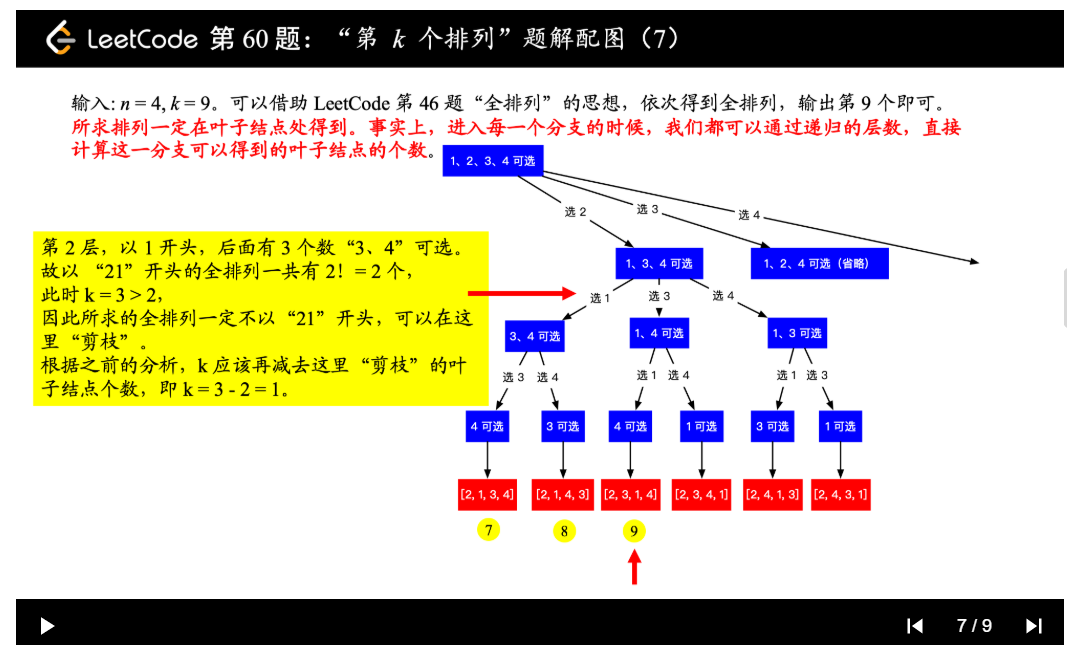
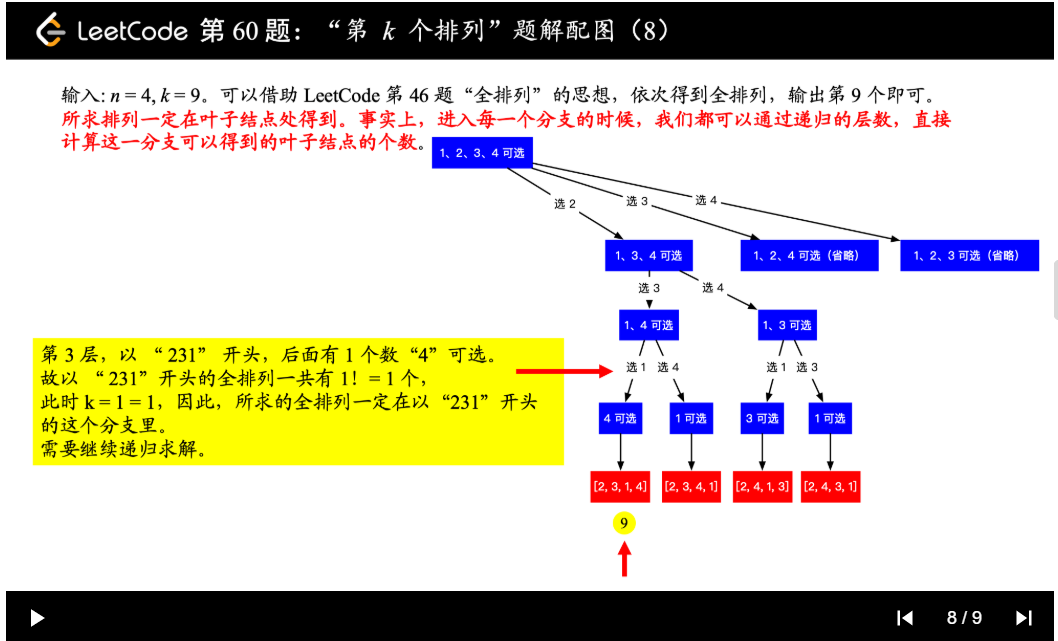
1 | class Solution { |
77. 组合
Description
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
Example
示例:
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
Program
回溯+剪枝
与之前做过的组合题类似,这里也是通过画图,从start开始往后遍历,因为往前遍历会出现组合重复!再者,继续分析图,可以发现,如果当前组合数量加上剩余元素的数量不够k,则没必要继续搜索了,剪枝!
1 | class Solution { |
79. 单词搜索
Description
给定一个二维网格和一个单词,找出该单词是否存在于网格中。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
Example
示例:
board =
[
[‘A’,’B’,’C’,’E’],
[‘S’,’F’,’C’,’S’],
[‘A’,’D’,’E’,’E’]
]
给定 word = “ABCCED”, 返回 true
给定 word = “SEE”, 返回 true
给定 word = “ABCB”, 返回 false
提示:
board 和 word 中只包含大写和小写英文字母。
1 <= board.length <= 200
1 <= board[i].length <= 200
1 <= word.length <= 10^3
Program
1 | class Solution { |
89. 格雷编码
Description
格雷编码是一个二进制数字系统,在该系统中,两个连续的数值仅有一个位数的差异。
给定一个代表编码总位数的非负整数 n,打印其格雷编码序列。即使有多个不同答案,你也只需要返回其中一种。
格雷编码序列必须以 0 开头。
Example
示例 1:
输入: 2
输出: [0,1,3,2]
解释:
00 - 0
01 - 1
11 - 3
10 - 2
对于给定的 n,其格雷编码序列并不唯一。
例如,[0,2,3,1] 也是一个有效的格雷编码序列。
00 - 0
10 - 2
11 - 3
01 - 1
示例 2:
输入: 0
输出: [0]
解释: 我们定义格雷编码序列必须以 0 开头。
给定编码总位数为 n 的格雷编码序列,其长度为 2n。当 n = 0 时,长度为 20 = 1。
因此,当 n = 0 时,其格雷编码序列为 [0]。
Program
递归
1 | class Solution { |
找规律
设G[n]为n阶格雷码序列,则对G[n]倒序后,对每个元素二进制表示前导加1(变成n+1位了)得到R[n],最终结果为G[n+1]=G[n]+Rn,时间复杂度由元素个数决定$O(2^n)$
例如:
n=0, [0]
n=1, [0,1]
n=2, [00,01,11,10]
n=3,[000,001,011,010,110,111,101,100]
…
以此类推!
1 | class Solution { |
90. 子集 II
Description
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
Example
示例:
输入: [1,2,2]
输出:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]
Program
回溯+剪枝
(1)首先,排序剪枝常见套路;
(2)关键在于每一层每个节点都是一个结果,这个很关键!因为每一层的选择包含了前面不选则的结果。
1 | class Solution { |
93. 复原IP地址
Description
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
有效的 IP 地址正好由四个整数(每个整数位于 0 到 255 之间组成),整数之间用 ‘.’ 分隔。
Example
示例:
输入: “25525511135”
输出: [“255.255.11.135”, “255.255.111.35”]
Program
1 | class Solution { |
131. 分割回文串
Description
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
Example
示例:
输入: “aab”
输出:
[
[“aa”,”b”],
[“a”,”a”,”b”]
]
Program
错误思路
将字符串二分,递归算出两部分的可划分的方案合并。
存在重复!,例如“aab”,划分为”a””ab”和”aa”,”b”后都会产生”a,a,b”这样的重复结果!
1 | class Solution { |
回溯+剪枝+动规预处理
因为需要全部划分为回文子串,可以从第一个子串入手,进行选择判断和回溯!还是老套路!
1 | class Solution { |
140. 单词拆分 II
Description
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
分隔时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
Example
示例 1:
输入:
s = “catsanddog”
wordDict = [“cat”, “cats”, “and”, “sand”, “dog”]
输出:
[
“cats and dog”,
“cat sand dog”
]
示例 2:
输入:
s = “pineapplepenapple”
wordDict = [“apple”, “pen”, “applepen”, “pine”, “pineapple”]
输出:
[
“pine apple pen apple”,
“pineapple pen apple”,
“pine applepen apple”
]
解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:
s = “catsandog”
wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出:
[]
Program
DP+回溯
首先计算DP,判断是否可以拆分到底,然后在回溯。
1 | class Solution { |
216. 组合总和 III
Description
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
所有数字都是正整数。
解集不能包含重复的组合。
Example
示例 1:
输入: k = 3, n = 7
输出: [[1,2,4]]
示例 2:
输入: k = 3, n = 9
输出: [[1,2,6], [1,3,5], [2,3,4]]
Program
1 | class Solution { |
491. 递增子序列
Description
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
Example
示例:
输入: [4, 6, 7, 7]
输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
说明:
给定数组的长度不会超过15。
数组中的整数范围是 [-100,100]。
给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
Program
回溯+剪枝
首先画出多叉树图,两个关键点:
(1)为了避免重复,那么同个父亲的孩子层不能存在重复元素,这里通过HashSet记录当前层已遍历的数字进行去重;
(2)由于题目是求递增序列,那么前面访问的元素再次访问,这里通过start索引解决;
1 | class Solution { |
526. 优美的排列
Description
假设有从 1 到 N 的 N 个整数,如果从这 N 个数字中成功构造出一个数组,使得数组的第 i 位 (1 <= i <= N) 满足如下两个条件中的一个,我们就称这个数组为一个优美的排列。条件:
第 i 位的数字能被 i 整除
i 能被第 i 位上的数字整除
现在给定一个整数 N,请问可以构造多少个优美的排列?
Example
示例1:
输入: 2
输出: 2
解释:
第 1 个优美的排列是 [1, 2]:
第 1 个位置(i=1)上的数字是1,1能被 i(i=1)整除
第 2 个位置(i=2)上的数字是2,2能被 i(i=2)整除
第 2 个优美的排列是 [2, 1]:
第 1 个位置(i=1)上的数字是2,2能被 i(i=1)整除
第 2 个位置(i=2)上的数字是1,i(i=2)能被 1 整除
说明:
N 是一个正整数,并且不会超过15。
Program
1 | class Solution { |
状态压缩DP
设DP[i]为排列i的个数,其中i用二进制表示,例如1011表示数1,2,4被使用:
令j为待排列的数字(1…N),那么i中第j-1位必须为0表示未用,状态转移方程:
DP[i|(1<<(j-1))]+=DP[i],当i的第j-1位未使用,且j与s成倍数关系(s为当前待排的第s个数)
1 | class Solution { |
679. 24 点游戏
Description
你有 4 张写有 1 到 9 数字的牌。你需要判断是否能通过 ,/,+,-,(,) 的运算得到 24。
*Example**
示例 1:
输入: [4, 1, 8, 7]
输出: True
解释: (8-4) * (7-1) = 24
示例 2:
输入: [1, 2, 1, 2]
输出: False
注意:
除法运算符 / 表示实数除法,而不是整数除法。例如 4 / (1 - 2/3) = 12 。
每个运算符对两个数进行运算。特别是我们不能用 - 作为一元运算符。例如,[1, 1, 1, 1] 作为输入时,表达式 -1 - 1 - 1 - 1 是不允许的。
你不能将数字连接在一起。例如,输入为 [1, 2, 1, 2] 时,不能写成 12 + 12 。
Program
回溯
每次选择两个数进行四则运算,结果放入数组进行下一次选择,最终只有一个数的时候判断绝对值是否满足$1e-6$精度。
剪枝:乘法和加法满足交换律,可以剪枝。
1 | class Solution { |
797. 所有可能的路径
Description
给一个有 n 个结点的有向无环图,找到所有从 0 到 n-1 的路径并输出(不要求按顺序)
二维数组的第 i 个数组中的单元都表示有向图中 i 号结点所能到达的下一些结点(译者注:有向图是有方向的,即规定了 a→b 你就不能从 b→a )空就是没有下一个结点了。
Example
示例 1:
输入:graph = [[1,2],[3],[3],[]]
输出:[[0,1,3],[0,2,3]]
解释:有两条路径 0 -> 1 -> 3 和 0 -> 2 -> 3
示例 2:
输入:graph = [[4,3,1],[3,2,4],[3],[4],[]]
输出:[[0,4],[0,3,4],[0,1,3,4],[0,1,2,3,4],[0,1,4]]
示例 3:
输入:graph = [[1],[]]
输出:[[0,1]]
示例 4:
输入:graph = [[1,2,3],[2],[3],[]]
输出:[[0,1,2,3],[0,2,3],[0,3]]
示例 5:
输入:graph = [[1,3],[2],[3],[]]
输出:[[0,1,2,3],[0,3]]
提示:
结点的数量会在范围 [2, 15] 内。
你可以把路径以任意顺序输出,但在路径内的结点的顺序必须保证
Program
1 | class Solution { |
980. 不同路径 III
Description
在二维网格 grid 上,有 4 种类型的方格:
1 表示起始方格。且只有一个起始方格。
2 表示结束方格,且只有一个结束方格。
0 表示我们可以走过的空方格。
-1 表示我们无法跨越的障碍。
返回在四个方向(上、下、左、右)上行走时,从起始方格到结束方格的不同路径的数目。
每一个无障碍方格都要通过一次,但是一条路径中不能重复通过同一个方格。
Example
示例 1:
输入:[[1,0,0,0],[0,0,0,0],[0,0,2,-1]]
输出:2
解释:我们有以下两条路径:
- (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2)
- (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2)
示例 2:
输入:[[1,0,0,0],[0,0,0,0],[0,0,0,2]]
输出:4
解释:我们有以下四条路径:
- (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2),(2,3)
- (0,0),(0,1),(1,1),(1,0),(2,0),(2,1),(2,2),(1,2),(0,2),(0,3),(1,3),(2,3)
- (0,0),(1,0),(2,0),(2,1),(2,2),(1,2),(1,1),(0,1),(0,2),(0,3),(1,3),(2,3)
- (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2),(2,3)
示例 3:
输入:[[0,1],[2,0]]
输出:0
解释:
没有一条路能完全穿过每一个空的方格一次。
请注意,起始和结束方格可以位于网格中的任意位置。
提示:
1 <= grid.length * grid[0].length <= 20
Program
1 | class Solution { |
996. 正方形数组的数目
Description
给定一个非负整数数组 A,如果该数组每对相邻元素之和是一个完全平方数,则称这一数组为正方形数组。
返回 A 的正方形排列的数目。两个排列 A1 和 A2 不同的充要条件是存在某个索引 i,使得 A1[i] != A2[i]。
Example
示例 1:
输入:[1,17,8]
输出:2
解释:
[1,8,17] 和 [17,8,1] 都是有效的排列。
示例 2:
输入:[2,2,2]
输出:1
提示:
1 <= A.length <= 12
0 <= A[i] <= 1e9
Program
1 | class Solution { |
1079. 活字印刷
Description
你有一套活字字模 tiles,其中每个字模上都刻有一个字母 tiles[i]。返回你可以印出的非空字母序列的数目。
注意:本题中,每个活字字模只能使用一次。
Example
示例 1:
输入:”AAB”
输出:8
解释:可能的序列为 “A”, “B”, “AA”, “AB”, “BA”, “AAB”, “ABA”, “BAA”。
示例 2:
输入:”AAABBC”
输出:188
提示:
1 <= tiles.length <= 7
tiles 由大写英文字母组成
Program
回溯
首先画出多叉树图,可以发现剪枝项,与之前全排列、组合等类似套路,不同点在于这里字符串的组合允许顺序不同。
所以每次需要裁减子串进行递归,同时需要注意每个节点都是一种情况!!
1 | class Solution { |
进一步优化空间
首先注意到上面每次递归是需要剔除原串中的某个字母,且每层只能访问不同的字母,这样直接可以用ch[26]数组分别表示原串中各个字母的个数,然后进行递归!
1 | class Solution { |
1219. 黄金矿工
Description
你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注。每个单元格中的整数就表示这一单元格中的黄金数量;如果该单元格是空的,那么就是 0。
为了使收益最大化,矿工需要按以下规则来开采黄金:
- 每当矿工进入一个单元,就会收集该单元格中的所有黄金。
- 矿工每次可以从当前位置向上下左右四个方向走。
- 每个单元格只能被开采(进入)一次。
- 不得开采(进入)黄金数目为 0 的单元格。
- 矿工可以从网格中 任意一个 有黄金的单元格出发或者是停止。
Example
示例 1:
输入:grid = [[0,6,0],[5,8,7],[0,9,0]]
输出:24
解释:
[[0,6,0],
[5,8,7],
[0,9,0]]
一种收集最多黄金的路线是:9 -> 8 -> 7。
示例 2:
输入:grid = [[1,0,7],[2,0,6],[3,4,5],[0,3,0],[9,0,20]]
输出:28
解释:
[[1,0,7],
[2,0,6],
[3,4,5],
[0,3,0],
[9,0,20]]
一种收集最多黄金的路线是:1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7。
提示:
1 <= grid.length, grid[i].length <= 15
0 <= grid[i][j] <= 100
最多 25 个单元格中有黄金。
Program
1 | class Solution { |
1415. 长度为 n 的开心字符串中字典序第 k 小的字符串
Description
一个 「开心字符串」定义为:
- 仅包含小写字母 [‘a’, ‘b’, ‘c’].
- 对所有在 1 到 s.length - 1 之间的 i ,满足 s[i] != s[i + 1] (字符串的下标从 1 开始)。
比方说,字符串 “abc”,”ac”,”b” 和 “abcbabcbcb” 都是开心字符串,但是 “aa”,”baa” 和 “ababbc” 都不是开心字符串。
给你两个整数 n 和 k ,你需要将长度为 n 的所有开心字符串按字典序排序。
请你返回排序后的第 k 个开心字符串,如果长度为 n 的开心字符串少于 k 个,那么请你返回 空字符串 。
Example
示例 1:
输入:n = 1, k = 3
输出:”c”
解释:列表 [“a”, “b”, “c”] 包含了所有长度为 1 的开心字符串。按照字典序排序后第三个字符串为 “c” 。
示例 2:
输入:n = 1, k = 4
输出:””
解释:长度为 1 的开心字符串只有 3 个。
示例 3:
输入:n = 3, k = 9
输出:”cab”
解释:长度为 3 的开心字符串总共有 12 个 [“aba”, “abc”, “aca”, “acb”, “bab”, “bac”, “bca”, “bcb”, “cab”, “cac”, “cba”, “cbc”] 。第 9 个字符串为 “cab”
示例 4:
输入:n = 2, k = 7
输出:””
示例 5:
输入:n = 10, k = 100
输出:”abacbabacb”
提示:
1 <= n <= 10
1 <= k <= 100
Program
深搜+剪枝
(1)一个基本想法是深搜,回溯保存结果,但是太慢了,没必要;
(2)画出多叉树图,可以发现如果该分支的子树的叶子节点个数比k小,可以直接跳过,k-=ans;
(3)k>ans时,说明在该子树上找到结果,继续该子树的递归,知道结果字符串长度为n。
时间复杂度:$O(n)$,只与第一层“a,b,c”以及后面子树层高有关,即$O(3+2*(n-1))$
1 | class Solution { |
5520. 拆分字符串使唯一子字符串的数目最大
Description
给你一个字符串 s ,请你拆分该字符串,并返回拆分后唯一子字符串的最大数目。
字符串 s 拆分后可以得到若干 非空子字符串 ,这些子字符串连接后应当能够还原为原字符串。但是拆分出来的每个子字符串都必须是 唯一的 。
注意:子字符串 是字符串中的一个连续字符序列。
Example
示例 1:
输入:s = “ababccc”
输出:5
解释:一种最大拆分方法为 [‘a’, ‘b’, ‘ab’, ‘c’, ‘cc’] 。像 [‘a’, ‘b’, ‘a’, ‘b’, ‘c’, ‘cc’] 这样拆分不满足题目要求,因为其中的 ‘a’ 和 ‘b’ 都出现了不止一次。
示例 2:
输入:s = “aba”
输出:2
解释:一种最大拆分方法为 [‘a’, ‘ba’] 。
示例 3:
输入:s = “aa”
输出:1
解释:无法进一步拆分字符串。
提示:
1 <= s.length <= 16
s 仅包含小写英文字母
Program
1 | class Solution { |
剑指 Offer 38. 字符串的排列
Description
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
Example
示例:
输入:s = “abc”
输出:[“abc”,”acb”,”bac”,”bca”,”cab”,”cba”]
限制:
1 <= s 的长度 <= 8
Program
回溯+剪枝
注意s可能存在重复元素,所以要先排序,然后画出多叉树图,同层不能选择重复元素即可!
时间复杂度:$O(N!)$,排列数!
空间复杂度:$O(N^2)$,栈$O(N)$,而辅助s为$N+N-1+N-2+…+1$为$O(N^2)$。
1 | class Solution { |
面试题 08.04. 幂集
Description
幂集。编写一种方法,返回某集合的所有子集。集合中不包含重复的元素。
说明:解集不能包含重复的子集。
Example
示例:
输入: nums = [1,2,3]
输出:
[
[3],
[1],
[2],
[1,2,3],
[1,3],
[2,3],
[1,2],
[]
]
Program
回溯
多叉树图上每个节点都是一个结果,注意每一层不能重复选择。
时间复杂度:$O(2^n)$
空间复杂度:$O(n)$,数组和递归栈都为$O(n)$
1 | class Solution { |
面试题 08.07. 无重复字符串的排列组合
Description
无重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合,字符串每个字符均不相同。
Example
示例1:
输入:S = “qwe”
输出:[“qwe”, “qew”, “wqe”, “weq”, “ewq”, “eqw”]
示例2:
输入:S = “ab”
输出:[“ab”, “ba”]
提示:
字符都是英文字母。
字符串长度在[1, 9]之间。
Program
1 | class Solution { |
面试题 08.08. 有重复字符串的排列组合
Description
有重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合。
Example
示例1:
输入:S = “qqe”
输出:[“eqq”,”qeq”,”qqe”]
示例2:
输入:S = “ab”
输出:[“ab”, “ba”]
提示:
字符都是英文字母。
字符串长度在[1, 9]之间。
Program
1 | class Solution { |
面试题 08.09. 括号
Description
括号。设计一种算法,打印n对括号的所有合法的(例如,开闭一一对应)组合。
说明:解集不能包含重复的子集。
Example
例如,给出 n = 3,生成结果为:
1 | [ |
Program
1 | class Solution { |
面试题 08.12. 八皇后
Description
设计一种算法,打印 N 皇后在 N × N 棋盘上的各种摆法,其中每个皇后都不同行、不同列,也不在对角线上。这里的“对角线”指的是所有的对角线,不只是平分整个棋盘的那两条对角线。
注意:本题相对原题做了扩展
Example
示例:
输入:4
输出:[[“.Q..”,”…Q”,”Q…”,”..Q.”],[“..Q.”,”Q…”,”…Q”,”.Q..”]]
解释: 4 皇后问题存在如下两个不同的解法。
[
[“.Q..”, // 解法 1
“…Q”,
“Q…”,
“..Q.”],
[“..Q.”, // 解法 2
“Q…”,
“…Q”,
“.Q..”]
]
Program
1 | class Solution { |
其他
1.两数之和
Description
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
Example
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
Program
Hash只记录最后一次nums[i]出现的位置,之后判断即可。
1 | class Solution { |
方法:反转一半数字
思路
映入脑海的第一个想法是将数字转换为字符串,并检查字符串是否为回文。但是,这需要额外的非常量空间来创建问题描述中所不允许的字符串。
第二个想法是将数字本身反转,然后将反转后的数字与原始数字进行比较,如果它们是相同的,那么这个数字就是回文。
但是,如果反转后的数字大于 $\text{int.MAX}int.MAX$,我们将遇到整数溢出问题。
按照第二个想法,为了避免数字反转可能导致的溢出问题,为什么不考虑只反转 \text{int}int 数字的一半?毕竟,如果该数字是回文,其后半部分反转后应该与原始数字的前半部分相同。
例如,输入 1221,我们可以将数字 “1221” 的后半部分从 “21” 反转为 “12”,并将其与前半部分 “12” 进行比较,因为二者相同,我们得知数字 1221 是回文。
让我们看看如何将这个想法转化为一个算法。
算法
首先,我们应该处理一些临界情况。所有负数都不可能是回文,例如:-123 不是回文,因为 - 不等于 3。所以我们可以对所有负数返回 false。
现在,让我们来考虑如何反转后半部分的数字。
对于数字 1221,如果执行 1221 % 10,我们将得到最后一位数字 1,要得到倒数第二位数字,我们可以先通过除以 10 把最后一位数字从 1221 中移除,1221 / 10 = 122,再求出上一步结果除以 10 的余数,122 % 10 = 2,就可以得到倒数第二位数字。如果我们把最后一位数字乘以 10,再加上倒数第二位数字,1 * 10 + 2 = 12,就得到了我们想要的反转后的数字。如果继续这个过程,我们将得到更多位数的反转数字。
现在的问题是,我们如何知道反转数字的位数已经达到原始数字位数的一半?
我们将原始数字除以 10,然后给反转后的数字乘上 10,所以,当原始数字小于反转后的数字时,就意味着我们已经处理了一半位数的数字。
时间复杂度:对于每次迭代,我们会将输入除以10,因此时间复杂度为$O\left(\log_{10}{n}\right)$
空间复杂度:$O\left(1\right)$
1 | class Solution { |
13.罗马数字转整数
Description
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
- I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
- X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
- C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
Example
示例 1:
输入: “III”
输出: 3
示例 2:
输入: “IV”
输出: 4
示例 3:
输入: “IX”
输出: 9
示例 4:
输入: “LVIII”
输出: 58
解释: L = 50, V= 5, III = 3.
示例 5:
输入: “MCMXCIV”
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
Program
代码行数:解析
构建一个字典记录所有罗马数字子串,注意长度为2的子串记录的值是(实际值 - 子串内左边罗马数字代表的数值)
这样一来,遍历整个 ss 的时候判断当前位置和后一个位置的两个字符组成的字符串是否在字典内,如果在就记录值,不在就说明当前位置不存在小数字在前面的情况,直接记录当前位置字符对应值
1 | class Solution { |
14. 最长公共前缀
Description
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 “”。
Example
示例 1:
输入: [“flower”,”flow”,”flight”]
输出: “fl”
示例 2:
输入: [“dog”,”racecar”,”car”]
输出: “”
解释: 输入不存在公共前缀。
说明:
所有输入只包含小写字母 a-z 。
Program
1 | class Solution { |
20. 有效的括号
Description
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
Example
示例 1:
输入: “()”
输出: true
示例 2:
输入: “()[]{}”
输出: true
示例 3:
输入: “(]”
输出: false
示例 4:
输入: “([)]”
输出: false
示例 5:
输入: “{[]}”
输出: true
Program
1 | class Solution { |
21. 合并两个有序链表
Description
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
Example
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
Program
1 | /** |
26. 删除排序数组中的重复项
Description
给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
Example
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
Program
1 | class Solution { |
27. 移除元素
Description
给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
Example
示例 1:
给定 nums = [3,2,2,3], val = 3,
函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,1,2,2,3,0,4,2], val = 2,
函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
注意这五个元素可为任意顺序。
你不需要考虑数组中超出新长度后面的元素。
Program
1 | class Solution { |
28. 实现strStr
Description
现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
Example
示例 1:
输入: haystack = “hello”, needle = “ll”
输出: 2
示例 2:
输入: haystack = “aaaaa”, needle = “bba”
输出: -1
Program
1 | class Solution { |
38. 报数
Description
报数序列是一个整数序列,按照其中的整数的顺序进行报数,得到下一个数。其前五项如下:
1 | 1. 1 |
1 被读作 “one 1” (“一个一”) , 即 11。
11 被读作 “two 1s” (“两个一”), 即 21。
21 被读作 “one 2”, “one 1” (”一个二” , “一个一”) , 即 1211。
给定一个正整数 n(1 ≤ n ≤ 30),输出报数序列的第 n 项。
注意:整数顺序将表示为一个字符串。
Example
示例 1:
输入: 1
输出: “1”
示例 2:
输入: 4
输出: “1211”
Program
1 |
|
48. 旋转图像
Description
给定一个 n × n 的二维矩阵表示一个图像。
将图像顺时针旋转 90 度。
说明:
你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
Example
示例 1:
给定 matrix =
1 | [ |
原地旋转输入矩阵,使其变为:
1 | [ |
示例 2:
给定 matrix =
1 | [ |
原地旋转输入矩阵,使其变为:
1 | [ |
Program
先转置再对换。
1 | class Solution { |
58. 最后一个单词的长度
Description
给定一个仅包含大小写字母和空格 ‘ ‘ 的字符串,返回其最后一个单词的长度。
如果不存在最后一个单词,请返回 0 。
说明:一个单词是指由字母组成,但不包含任何空格的字符串。
Example
示例:
输入: “Hello World”
输出: 5
Program
1 |
|
66. 加一
Description
给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
Example
示例 1:
输入: [1,2,3]
输出: [1,2,4]
解释: 输入数组表示数字 123。
示例 2:
输入: [4,3,2,1]
输出: [4,3,2,2]
解释: 输入数组表示数字 4321。
Program
1 | class Solution { |
83. 删除排序链表中的重复元素
Description
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
Example
示例 1:
输入: 1->1->2
输出: 1->2
示例 2:
输入: 1->1->2->3->3
输出: 1->2->3
Program
1 | /** |
88. 合并两个有序数组
Description
给定两个有序整数数组 nums1 和 nums2,将 nums2 合并到 nums1 中,使得 num1 成为一个有序数组。
说明:
初始化 nums1 和 nums2 的元素数量分别为 m 和 n。
你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
Example
示例:
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
Program
1 | class Solution { |
100. 相同的树
Description
给定两个二叉树,编写一个函数来检验它们是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
Example
示例 1:
1 | 输入: 1 1 |
示例 2:
1 | 输入: 1 1 |
示例 3:
1 | 输入: 1 1 |
Program
1 | /** |
101. 对称二叉树
Description
给定一个二叉树,检查它是否是镜像对称的。
Example
1 | 例如,二叉树 [1,2,2,3,4,4,3] 是对称的。 |
Program
1 | /** |
1 | /** |
104. 二叉树的最大深度
Description
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
Example
示例:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
返回它的最大深度 3 。
Program
1 | /** |
107. 二叉树的层次遍历 II
Description
给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
**Example
例如:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
1 | [ |
Program
1 | /** |
1 | /** |
108. 将有序数组转换为二叉搜索树
Description
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
Example
示例:
给定有序数组: [-10,-3,0,5,9],
一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
1 | 0 |
Program
一开始还想直接上平衡二叉树模板….
1 | /** |
110. 平衡二叉树
Description
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
Example
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
1 | 3 |
返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1 | 1 |
返回 false 。
Program
1 | /** |
111. 二叉树的最小深度
Description
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
Example
示例:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
返回它的最小深度 2.
Program
1 | /** |
112. 路径总和
Description
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
Example
示例:
给定如下二叉树,以及目标和 sum = 22,
1 | 5 |
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
Program
1 | /** |
118. 杨辉三角
Description
给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。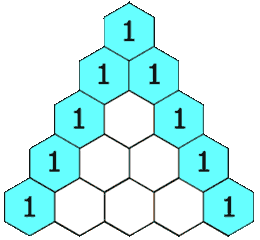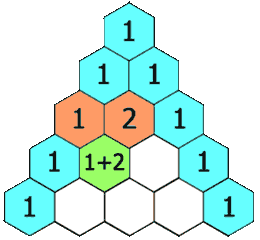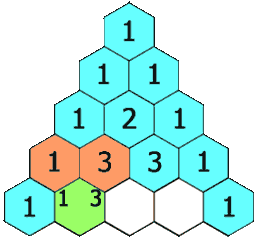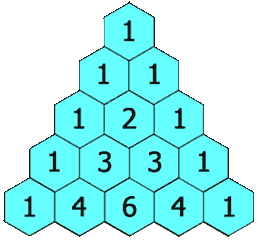
在杨辉三角中,每个数是它左上方和右上方的数的和。
Example
示例:
输入: 5
输出:
1 | [ |
Program
1 | class Solution { |
119. 杨辉三角 II
Description
给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
Example
示例:
输入: 3
输出: [1,3,3,1]
Program
1 | class Solution { |
125. 验证回文串
Description
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
Example
示例 1:
输入: “A man, a plan, a canal: Panama”
输出: true
示例 2:
输入: “race a car”
输出: false
Program
1 | class Solution { |
141. 环形链表
Description
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
Example
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
Program
1 | /** |
155. 最小栈
Description
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
push(x) – 将元素 x 推入栈中。
pop() – 删除栈顶的元素。
top() – 获取栈顶元素。
getMin() – 检索栈中的最小元素。
Example
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); –> 返回 -3.
minStack.pop();
minStack.top(); –> 返回 0.
minStack.getMin(); –> 返回 -2.
Program
1 | class MinStack { |
160. 相交链表
Description
编写一个程序,找到两个单链表相交的起始节点。
如下面的两个链表:
在节点 c1 开始相交。
Example
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
1 | 注意: |
Program
1 | /** |
1 | /** |
167. 两数之和 II - 输入有序数组
Destription
给定一个已按照升序排列 的有序数组,找到两个数使得它们相加之和等于目标数。
函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。
说明:
返回的下标值(index1 和 index2)不是从零开始的。
你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
Example
示例:
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
Program
1 | class Solution { |
169. 多数元素
Description
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
Example
示例 1:
输入: [3,2,3]
输出: 3
示例 2:
输入: [2,2,1,1,1,2,2]
输出: 2
Program
1 | class Solution { |
面试题 17.10. 主要元素
Description
数组中占比超过一半的元素称之为主要元素。给定一个整数数组,找到它的主要元素。若没有,返回-1。
Example
示例 1:
输入:[1,2,5,9,5,9,5,5,5]
输出:5
示例 2:
输入:[3,2]
输出:-1
示例 3:
输入:[2,2,1,1,1,2,2]
输出:2
说明:
你有办法在时间复杂度为 O(N),空间复杂度为 O(1) 内完成吗?
Program
1 | class Solution { |
189. 旋转数组
Description
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
Example
示例 1:
输入: [1,2,3,4,5,6,7] 和 k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右旋转 1 步: [7,1,2,3,4,5,6]
向右旋转 2 步: [6,7,1,2,3,4,5]
向右旋转 3 步: [5,6,7,1,2,3,4]
示例 2:
输入: [-1,-100,3,99] 和 k = 2
输出: [3,99,-1,-100]
解释:
向右旋转 1 步: [99,-1,-100,3]
向右旋转 2 步: [3,99,-1,-100]
Progam
1 | class Solution { |
190. 颠倒二进制位
Description
颠倒给定的 32 位无符号整数的二进制位。
Example
示例 1:
输入: 00000010100101000001111010011100
输出: 00111001011110000010100101000000
解释: 输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596,
因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。
示例 2:
输入:11111111111111111111111111111101
输出:10111111111111111111111111111111
解释:输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293,
因此返回 3221225471 其二进制表示形式为 10101111110010110010011101101001。
Program
1 | class Solution { |
191. 位1的个数
Description
编写一个函数,输入是一个无符号整数,返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
Example
示例 1:
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 ‘1’。
示例 2:
输入:00000000000000000000000010000000
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 ‘1’。
示例 3:
输入:11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 ‘1’。
Program
1 | class Solution { |
计算末尾1的个数即可,$n&(n-1)$会将最后一位置0
1 | class Solution { |
203. 移除链表元素
Description
删除链表中等于给定值 val 的所有节点。
Example
示例:
输入: 1->2->6->3->4->5->6, val = 6
输出: 1->2->3->4->5
Program
1 | /** |
205. 同构字符串
Description
给定两个字符串 s 和 t,判断它们是否是同构的。
如果 s 中的字符可以被替换得到 t ,那么这两个字符串是同构的。
所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
Example
示例 1:
输入: s = “egg”, t = “add”
输出: true
示例 2:
输入: s = “foo”, t = “bar”
输出: false
示例 3:
输入: s = “paper”, t = “title”
输出: true
Program
1.Hash
1 | class Solution { |
2.比较字母首次出现位置
1 | class Solution { |
206. 反转链表
Description
反转一个单链表。
Example
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
Program
1 | /** |
217. 存在重复元素
Description
给定一个整数数组,判断是否存在重复元素。
如果任何值在数组中出现至少两次,函数返回 true。如果数组中每个元素都不相同,则返回 false。
Example
示例 1:
输入: [1,2,3,1]
输出: true
示例 2:
输入: [1,2,3,4]
输出: false
示例 3:
输入: [1,1,1,3,3,4,3,2,4,2]
输出: true
Program
1 | class Solution { |
219. 存在重复元素 II
Description
给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的绝对值最大为 k。
Example
示例 1:
输入: nums = [1,2,3,1], k = 3
输出: true
示例 2:
输入: nums = [1,0,1,1], k = 1
输出: true
示例 3:
输入: nums = [1,2,3,1,2,3], k = 2
输出: false
Progam
1 | class Solution { |
1 | class Solution { |
225. 用队列实现栈
Description
使用队列实现栈的下列操作:
push(x) – 元素 x 入栈
pop() – 移除栈顶元素
top() – 获取栈顶元素
empty() – 返回栈是否为空
注意:
你只能使用队列的基本操作– 也就是 push to back, peek/pop from front, size, 和 is empty 这些操作是合法的。
你所使用的语言也许不支持队列。 你可以使用 list 或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
你可以假设所有操作都是有效的(例如, 对一个空的栈不会调用 pop 或者 top 操作)。
Program
1 | class MyStack { |
226. 翻转二叉树
Description
翻转一棵二叉树。
Example
示例:
输入:
4 /
2 7
/ \ /
1 3 6 9
输出:
4 /
7 2
/ \ /
9 6 3 1
Program
1 | /** |
207. 课程表
Description
现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,判断是否可能完成所有课程的学习?
Example
示例 1:
输入: 2, [[1,0]]
输出: true
解释: 总共有 2 门课程。学习课程 1 之前,你需要完成课程 0。所以这是可能的。
示例 2:
输入: 2, [[1,0],[0,1]]
输出: false
解释: 总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0;并且学习课程 0 之前,你还应先完成课程 1。这是不可能的。
说明:
输入的先决条件是由边缘列表表示的图形,而不是邻接矩阵。详情请参见图的表示法。
你可以假定输入的先决条件中没有重复的边。
Program
1 | class Solution { |
210. 课程表 II
Description
现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,返回你为了学完所有课程所安排的学习顺序。
可能会有多个正确的顺序,你只要返回一种就可以了。如果不可能完成所有课程,返回一个空数组。
Example
示例 1:
输入: 2, [[1,0]]
输出: [0,1]
解释: 总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。
示例 2:
输入: 4, [[1,0],[2,0],[3,1],[3,2]]
输出: [0,1,2,3] or [0,2,1,3]
解释: 总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3] 。
Program
1 | class Solution { |
349. 两个数组的交集
Description
给定两个数组,编写一个函数来计算它们的交集。
Example
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
说明:
输出结果中的每个元素一定是唯一的。
我们可以不考虑输出结果的顺序。
Program
1 | class Solution { |
1 | class Solution { |
130. 被围绕的区域
Description
给定一个二维的矩阵,包含 ‘X’ 和 ‘O’(字母 O)。
找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。
Example
示例:
X X X X
X O O X
X X O X
X O X X
运行你的函数后,矩阵变为:
X X X X
X X X X
X X X X
X O X X
Program
并查集
这里只需合并所有是O的区域,每个位置用father[i]标记,然后多用一个father[nCount]表示与边界相连,所以每个在边界上的O都与其合并,其他O只需要遍历四个方向合并即可。
1 | class Solution { |
深搜
从边界的O开始深搜,标记与边界相连的O为A,最后遍历矩阵,如果没被标记为A的O,那么表示被X围绕,如果被标记则还原为O
时间复杂度$O(n * m)$
1 | class Solution { |
200. 岛屿数量
Description
给定一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
Example
示例 1:
输入:
11110
11010
11000
00000
输出: 1
示例 2:
输入:
11000
11000
00100
00011
输出: 3
Program
1 | class Solution { |
399. 除法求值
Description
给出方程式 $A / B = k$, 其中 $A$ 和 $B$ 均为代表字符串的变量, $k$ 是一个浮点型数字。根据已知方程式求解问题,并返回计算结果。如果结果不存在,则返回 -1.0。
Example
示例 :
1 | 给定 a / b = 2.0, b / c = 3.0 |
1 | 输入为: vector<pair<string, string>> equations, vector<double>& values, vector<pair<string, string>> queries(方程式,方程式结果,问题方程式), 其中 equations.size() == values.size(),即方程式的长度与方程式结果长度相等(程式与结果一一对应),并且结果值均为正数。以上为方程式的描述。 返回vector<double>类型。 |
基于上述例子,输入如下:
equations(方程式) = [ [“a”, “b”], [“b”, “c”] ],
values(方程式结果) = [2.0, 3.0],
queries(问题方程式) = [ [“a”, “c”], [“b”, “a”], [“a”, “e”], [“a”, “a”], [“x”, “x”] ].
输入总是有效的。你可以假设除法运算中不会出现除数为0的情况,且不存在任何矛盾的结果。
Program
- father 记录的是每个节点的父节点是谁。
- val 记录的是每个节点到其父节点的权值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60class Solution {
public:
map<string, int> sToi;
map<int, string> iTos;
vector<int> father;
vector<double> val;
int nCount=0;
void convert(string str){
if(sToi.find(str)==sToi.end()){
sToi[str]=nCount;
iTos[nCount++]=str;
}
// return nCount++:
}
int findFather(int x){
if(x!=father[x]){
int fa=findFather(father[x]);
val[x]=val[x]*val[father[x]];
father[x]=fa;
}
return father[x];
}
void merge(int x, int y, double v){
int fa=findFather(x);
int fb=findFather(y);
if(fa!=fb){
father[fa]=fb;
val[fa]=v*val[y]/val[x];
}
}
double getResult(string s1, string s2){
if(sToi.find(s1)==sToi.end()||sToi.find(s2)==sToi.end()) return -1.0;
int a=sToi[s1];
int b=sToi[s2];
int fa=findFather(a);
int fb=findFather(b);
if(fa!=fb) return -1.0;
return val[a]/val[b];
}
vector<double> calcEquation(vector<vector<string>>& equations, vector<double>& values, vector<vector<string>>& queries) {
for(int i=0;i<equations.size();i++){
convert(equations[i][0]);
convert(equations[i][1]);
}
father.resize(nCount);
val.resize(nCount);
for(int i=0;i<nCount;i++){
father[i]=i;
val[i]=1;
}
for(int i=0;i<equations.size();i++){
merge(sToi[equations[i][0]], sToi[equations[i][1]], values[i]);
}
vector<double> result;
for(int i=0;i<queries.size();i++){
result.push_back(getResult(queries[i][0], queries[i][1]));
}
return result;
}
};547. 朋友圈
Description
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
Example
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
N 在[1,200]的范围内。
对于所有学生,有M[i][i] = 1。
如果有M[i][j] = 1,则有M[j][i] = 1。
Program
1 | class Solution { |
315. 计算右侧小于当前元素的个数
Description
给定一个整数数组 nums,按要求返回一个新数组 counts。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
Example
示例:
输入: [5,2,6,1]
输出: [2,1,1,0]
解释:
5 的右侧有 2 个更小的元素 (2 和 1).
2 的右侧仅有 1 个更小的元素 (1).
6 的右侧有 1 个更小的元素 (1).
1 的右侧有 0 个更小的元素.
Prgoram
1 | class Solution { |
187. 重复的DNA序列
Description
所有 DNA 都由一系列缩写为 A,C,G 和 T 的核苷酸组成,例如:“ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来查找 DNA 分子中所有出现超过一次的 10 个字母长的序列(子串)。
Example
示例:
输入:s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”
输出:[“AAAAACCCCC”, “CCCCCAAAAA”]
Program
A:00
C:01
G:10
T:11
滑动窗口左移两位,最后两位填充上述对应二进制位,或运算后,即新一次的字符串所对应的key
1 | class Solution { |
201. 数字范围按位与
Description
给定范围 [m, n],其中 0 <= m <= n <= 2147483647,返回此范围内所有数字的按位与(包含 m, n 两端点)。
Example
示例 1:
输入: [5,7]
输出: 4
示例 2:
输入: [0,1]
输出: 0
Program
m<n时,会发现
m:SSS0XXXX
n:SSS1XXXX
即m与n前若干位相同,某个高位不同,后面不一定相同,区间与一定是SSS00000的形式,
那么如何求SSS00000就变成了m:SSS0XXXX与上11100000即可,
而m与n异或得到0001XXXX,将其编程00011111的形式取反就是要的11100000的形式了!!!
1 | class Solution { |
260. 只出现一次的数字 III
Description
给定一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。
Example
示例 :
输入: [1,2,1,3,2,5]
输出: [3,5]
注意:
结果输出的顺序并不重要,对于上面的例子, [5, 3] 也是正确答案。
你的算法应该具有线性时间复杂度。你能否仅使用常数空间复杂度来实现?
Program
全部异或得到两个唯一出现一次的数的保留1bitmask,这些位上的1分别来自于两个唯一出现一次的数!
求lowbit后得到diff,而每个与diff与运算后不为0的数,继续异或得到第一个只出现一次的数x,x与bitmask异或得到第二个只出现一次的数。
1 | class Solution { |
318. 最大单词长度乘积
Description
给定一个字符串数组 words,找到 length(word[i]) * length(word[j]) 的最大值,并且这两个单词不含有公共字母。你可以认为每个单词只包含小写字母。如果不存在这样的两个单词,返回 0。
Example
示例 1:
输入: [“abcw”,”baz”,”foo”,”bar”,”xtfn”,”abcdef”]
输出: 16
解释: 这两个单词为 “abcw”, “xtfn”。
示例 2:
输入: [“a”,”ab”,”abc”,”d”,”cd”,”bcd”,”abcd”]
输出: 4
解释: 这两个单词为 “ab”, “cd”。
示例 3:
输入: [“a”,”aa”,”aaa”,”aaaa”]
输出: 0
解释: 不存在这样的两个单词。
Program
1 | class Solution { |
338. 比特位计数
Description
给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
Example
示例 1:
输入: 2
输出: [0,1,1]
示例 2:
输入: 5
输出: [0,1,1,2,1,2]
Program
考虑x与x>>1,差别就在最低位,DP[x]=DP[x>>1]+(x%2)
1 | class Solution { |
342. 4的幂
Description
给定一个整数 (32 位有符号整数),请编写一个函数来判断它是否是 4 的幂次方。
Example
示例 1:
输入: 16
输出: true
示例 2:
输入: 5
输出: false
Program
1 | class Solution { |
371. 两整数之和
Description
不使用运算符 + 和 - ,计算两整数 a 、b 之和。
Example
示例 1:
输入: a = 1, b = 2
输出: 3
示例 2:
输入: a = -2, b = 3
输出: 1
Progam
1 | class Solution { |
389. 找不同
Description
给定两个字符串 s 和 t,它们只包含小写字母。
字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。
请找出在 t 中被添加的字母。
Example
示例:
输入:
s = “abcd”
t = “abcde”
输出:
e
Program
1 | class Solution { |
393. UTF-8 编码验证
Description
UTF-8 中的一个字符可能的长度为 1 到 4 字节,遵循以下的规则:
对于 1 字节的字符,字节的第一位设为0,后面7位为这个符号的unicode码。
对于 n 字节的字符 (n > 1),第一个字节的前 n 位都设为1,第 n+1 位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
这是 UTF-8 编码的工作方式:
Char. number range | UTF-8 octet sequence
(hexadecimal) | (binary)
——————–+———————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
给定一个表示数据的整数数组,返回它是否为有效的 utf-8 编码。
注意:
输入是整数数组。只有每个整数的最低 8 个有效位用来存储数据。这意味着每个整数只表示 1 字节的数据。
Example
示例 1:
data = [197, 130, 1], 表示 8 位的序列: 11000101 10000010 00000001.
返回 true 。
这是有效的 utf-8 编码,为一个2字节字符,跟着一个1字节字符。
示例 2:
data = [235, 140, 4], 表示 8 位的序列: 11101011 10001100 00000100.
返回 false 。
前 3 位都是 1 ,第 4 位为 0 表示它是一个3字节字符。
下一个字节是开头为 10 的延续字节,这是正确的。
但第二个延续字节不以 10 开头,所以是不符合规则的。
Program
1 | class Solution { |
401. 二进制手表
Description
二进制手表顶部有 4 个 LED 代表小时(0-11),底部的 6 个 LED 代表分钟(0-59)。
每个 LED 代表一个 0 或 1,最低位在右侧。
例如,上面的二进制手表读取 “3:25”。
给定一个非负整数 n 代表当前 LED 亮着的数量,返回所有可能的时间。
Example
案例:
输入: n = 1
返回: [“1:00”, “2:00”, “4:00”, “8:00”, “0:01”, “0:02”, “0:04”, “0:08”, “0:16”, “0:32”]
注意事项:
输出的顺序没有要求。
小时不会以零开头,比如 “01:00” 是不允许的,应为 “1:00”。
分钟必须由两位数组成,可能会以零开头,比如 “10:2” 是无效的,应为 “10:02”。
Program
1 | class Solution { |
397. 整数替换
Description
给定一个正整数 n,你可以做如下操作:
- 如果 n 是偶数,则用 n / 2替换 n。
- 如果 n 是奇数,则可以用 n + 1或n - 1替换 n。
n 变为 1 所需的最小替换次数是多少?
Example
示例 1:
输入:
8
输出:
3
解释:
8 -> 4 -> 2 -> 1
示例 2:
输入:
7
输出:
4
解释:
7 -> 8 -> 4 -> 2 -> 1
或
7 -> 6 -> 3 -> 2 -> 1
Program
1 | class Solution { |
405. 数字转换为十六进制数
Description
给定一个整数,编写一个算法将这个数转换为十六进制数。对于负整数,我们通常使用 补码运算 方法。
注意:
十六进制中所有字母(a-f)都必须是小写。
十六进制字符串中不能包含多余的前导零。如果要转化的数为0,那么以单个字符’0’来表示;对于其他情况,十六进制字符串中的第一个字符将不会是0字符。
给定的数确保在32位有符号整数范围内。
不能使用任何由库提供的将数字直接转换或格式化为十六进制的方法。
Example
示例 1:
输入:
26
输出:
“1a”
示例 2:
输入:
-1
输出:
“ffffffff”
Program
1 | class Solution { |
421. 数组中两个数的最大异或值
Description
给定一个非空数组,数组中元素为 a0, a1, a2, … , an-1,其中 0 ≤ ai < 231 。
找到 ai 和aj 最大的异或 (XOR) 运算结果,其中0 ≤ i, j < n 。
你能在O(n)的时间解决这个问题吗?
Example
示例:
输入: [3, 10, 5, 25, 2, 8]
输出: 28
解释: 最大的结果是 5 ^ 25 = 28.
Program
思路
我们需要尽可能保留高位1,根据性质$a XOR b=c, a XOR c=b$,假设每个高位初始为1,与每个数前缀(高位)异或运算,如果异或结果存在前缀则保留1,否则0.
1 | class Solution { |
461. 汉明距离
Description
两个整数之间的汉明距离指的是这两个数字对应二进制位不同的位置的数目。
给出两个整数 x 和 y,计算它们之间的汉明距离。
注意:
0 ≤ x, y < 231.
Example
示例:
输入: x = 1, y = 4
输出: 2
解释:
1 | 1 (0 0 0 1) |
上面的箭头指出了对应二进制位不同的位置。
Program
1 | class Solution { |
476. 数字的补数
Description
给定一个正整数,输出它的补数。补数是对该数的二进制表示取反。
注意:
给定的整数保证在32位带符号整数的范围内。
你可以假定二进制数不包含前导零位。
Example
示例 1:
输入: 5
输出: 2
解释: 5的二进制表示为101(没有前导零位),其补数为010。所以你需要输出2。
示例 2:
输入: 1
输出: 0
解释: 1的二进制表示为1(没有前导零位),其补数为0。所以你需要输出0。
Program
1 | class Solution { |
477. 汉明距离总和
Description
两个整数的 汉明距离 指的是这两个数字的二进制数对应位不同的数量。
计算一个数组中,任意两个数之间汉明距离的总和。
Example
示例:
输入: 4, 14, 2
输出: 6
解释: 在二进制表示中,4表示为0100,14表示为1110,2表示为0010。(这样表示是为了体现后四位之间关系)
所以答案为:
HammingDistance(4, 14) + HammingDistance(4, 2) + HammingDistance(14, 2) = 2 + 2 + 2 = 6.
注意:
数组中元素的范围为从 0到 10^9。
数组的长度不超过 $10^4$。
Program
1 | class Solution { |
693. 交替位二进制数
Description
给定一个正整数,检查他是否为交替位二进制数:换句话说,就是他的二进制数相邻的两个位数永不相等。
Example
示例 1:Example
输入: 5
输出: True
解释:
5的二进制数是: 101
示例 2:
输入: 7
输出: False
解释:
7的二进制数是: 111
示例 3:
输入: 11
输出: False
解释:
11的二进制数是: 1011
示例 4:
输入: 10
输出: True
解释:
10的二进制数是: 1010
Program
1 | class Solution { |
756. 金字塔转换矩阵
Description
现在,我们用一些方块来堆砌一个金字塔。 每个方块用仅包含一个字母的字符串表示。
使用三元组表示金字塔的堆砌规则如下:
对于三元组(A, B, C) ,“C”为顶层方块,方块“A”、“B”分别作为方块“C”下一层的的左、右子块。当且仅当(A, B, C)是被允许的三元组,我们才可以将其堆砌上。
初始时,给定金字塔的基层 bottom,用一个字符串表示。一个允许的三元组列表 allowed,每个三元组用一个长度为 3 的字符串表示。
如果可以由基层一直堆到塔尖就返回 true,否则返回 false。
Example
示例 1:
输入: bottom = “BCD”, allowed = [“BCG”, “CDE”, “GEA”, “FFF”]
输出: true
解析:
可以堆砌成这样的金字塔:
1 | A |
因为符合(‘B’, ‘C’, ‘G’), (‘C’, ‘D’, ‘E’) 和 (‘G’, ‘E’, ‘A’) 三种规则。
示例 2:
输入: bottom = “AABA”, allowed = [“AAA”, “AAB”, “ABA”, “ABB”, “BAC”]
输出: false
解析:
无法一直堆到塔尖。
注意, 允许存在像 (A, B, C) 和 (A, B, D) 这样的三元组,其中 C != D。
注意:
bottom 的长度范围在 [2, 8]。
allowed 的长度范围在[0, 200]。
方块的标记字母范围为{‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’}。
Program
1 | class Solution { |
762. 二进制表示中质数个计算置位
Description
给定两个整数 L 和 R ,找到闭区间 [L, R] 范围内,计算置位位数为质数的整数个数。
(注意,计算置位代表二进制表示中1的个数。例如 21 的二进制表示 10101 有 3 个计算置位。还有,1 不是质数。)
Example
示例 1:
输入: L = 6, R = 10
输出: 4
解释:
6 -> 110 (2 个计算置位,2 是质数)
7 -> 111 (3 个计算置位,3 是质数)
9 -> 1001 (2 个计算置位,2 是质数)
10-> 1010 (2 个计算置位,2 是质数)
示例 2:
输入: L = 10, R = 15
输出: 5
解释:
10 -> 1010 (2 个计算置位, 2 是质数)
11 -> 1011 (3 个计算置位, 3 是质数)
12 -> 1100 (2 个计算置位, 2 是质数)
13 -> 1101 (3 个计算置位, 3 是质数)
14 -> 1110 (3 个计算置位, 3 是质数)
15 -> 1111 (4 个计算置位, 4 不是质数)
注意:
L, R 是 L <= R 且在 [1, 10^6] 中的整数。
R - L 的最大值为 10000。
Program
1 | class Solution { |
784. 字母大小写全排列
Description
给定一个字符串S,通过将字符串S中的每个字母转变大小写,我们可以获得一个新的字符串。返回所有可能得到的字符串集合。
Example
示例:
输入: S = “a1b2”
输出: [“a1b2”, “a1B2”, “A1b2”, “A1B2”]
输入: S = “3z4”
输出: [“3z4”, “3Z4”]
输入: S = “12345”
输出: [“12345”]
注意:
S 的长度不超过12。
S 仅由数字和字母组成。
Program
1 | class Solution { |
1131. 绝对值表达式的最大值
Description
给你两个长度相等的整数数组,返回下面表达式的最大值:
$|arr1[i] - arr1[j]| + |arr2[i] - arr2[j]| + |i - j|$
其中下标 i,j 满足 0 <= i, j < arr1.length。
Example
示例 1:
输入:arr1 = [1,2,3,4], arr2 = [-1,4,5,6]
输出:13
示例 2:
输入:arr1 = [1,-2,-5,0,10], arr2 = [0,-2,-1,-7,-4]
输出:20
Program
分析:
既然暴力解不可行,那么我们就需要思考有没有更好的办法,已知要求 $|arr1[i] - arr1[j]| + |arr2[i] - arr2[j]| + |i - j|$ 的最大值,我们可以先考虑一下子问题的求解:
子问题 1. 求 |arr1[i] - arr1[j]| 的最大值
这就比较简单了,可以直观地看出来答案,一个数组 arr1 里两个元素差的绝对值的最大值,应该等于 max(arr1) - min(arr1)
子问题 2. 求 |arr1[i] - arr1[j]| + |i - j| 的最大值
比上一题复杂了一点,观察并不能得出答案,因此,不妨把表达式的绝对值符号去掉,看看展开后会得到怎样的结果:
1 | abs( arr1[i] - arr1[j]) + abs(i - j) |
因为 i 和 j 是可以互换的,所以式 11 等价于式 44, 式 22 等价于式 33,因此可以得到:
1 | abs( arr1[i] - arr1[j]) + abs(i - j) |
现在不难发现, 原始表达式的值只取决于两个中间表达式:
中间表达式 A = arr1[i] + i
中间表达式 B = arr1[i] - i
所以有:
1 | max(abs( arr1[i] - arr1[j]) + abs(i - j) ) |
因此,不难得到子问题的求解代码如下:
1 | Python |
现在已经知道了子问题如何求解,那么本题也可以采用相同的解法,首先把绝对值符号去掉,展开表达式:
1 | |arr1[i] - arr1[j]| + |arr2[i] - arr2[j]| + |i - j| |
因为存在四组两两等价的展开,所以可以优化为四个表达式:
1 | A = arr1[i] + arr2[i] + i |
Python代码实现:
1 | class Solution(object): |
复杂度分析:
时间复杂度:$O(N)$
空间复杂度:$O(N)$
优化分析:
其实,并没有必要储存所有的 ·A,B,C,D· 表达式的值,
因为我们需要的仅仅是 ·A,B,C,D· 表达式的最大值和最小值,
因此可以用八个变量替代四个数组,将空间优化到 $O(1)$。
1 | class Solution { |
1239. 串联字符串的最大长度
Description
给定一个字符串数组 arr,字符串 s 是将 arr 某一子序列字符串连接所得的字符串,如果 s 中的每一个字符都只出现过一次,那么它就是一个可行解。
请返回所有可行解 s 中最长长度。
Example
示例 1:
输入:arr = [“un”,”iq”,”ue”]
输出:4
解释:所有可能的串联组合是 “”,”un”,”iq”,”ue”,”uniq” 和 “ique”,最大长度为 4。
示例 2:
输入:arr = [“cha”,”r”,”act”,”ers”]
输出:6
解释:可能的解答有 “chaers” 和 “acters”。
示例 3:
输入:arr = [“abcdefghijklmnopqrstuvwxyz”]
输出:26
提示:
1 <= arr.length <= 16
1 <= arr[i].length <= 26
arr[i] 中只含有小写英文字母
Program
1 | class Solution { |
1290. 二进制链表转整数
Description
给你一个单链表的引用结点 head。链表中每个结点的值不是 0 就是 1。已知此链表是一个整数数字的二进制表示形式。
请你返回该链表所表示数字的 十进制值 。
Example
示例 1:
输入:head = [1,0,1]
输出:5
解释:二进制数 (101) 转化为十进制数 (5)
示例 2:
输入:head = [0]
输出:0
示例 3:
输入:head = [1]
输出:1
示例 4:
输入:head = [1,0,0,1,0,0,1,1,1,0,0,0,0,0,0]
输出:18880
示例 5:
输入:head = [0,0]
输出:0
提示:
链表不为空。
链表的结点总数不超过 30。
每个结点的值不是 0 就是 1。
Program
1 | /** |
1297. 子串的最大出现次数
Description
给你一个字符串 s ,请你返回满足以下条件且出现次数最大的 任意 子串的出现次数:
子串中不同字母的数目必须小于等于 maxLetters 。
子串的长度必须大于等于 minSize 且小于等于 maxSize 。
Example
示例 1:
输入:s = “aababcaab”, maxLetters = 2, minSize = 3, maxSize = 4
输出:2
解释:子串 “aab” 在原字符串中出现了 2 次。
它满足所有的要求:2 个不同的字母,长度为 3 (在 minSize 和 maxSize 范围内)。
示例 2:
输入:s = “aaaa”, maxLetters = 1, minSize = 3, maxSize = 3
输出:2
解释:子串 “aaa” 在原字符串中出现了 2 次,且它们有重叠部分。
示例 3:
输入:s = “aabcabcab”, maxLetters = 2, minSize = 2, maxSize = 3
输出:3
示例 4:
输入:s = “abcde”, maxLetters = 2, minSize = 3, maxSize = 3
输出:0
提示:
1 <= s.length <= 10^5
1 <= maxLetters <= 26
1 <= minSize <= maxSize <= min(26, s.length)
s 只包含小写英文字母。
Program
假设字符串 T 在给定的字符串 S 中出现的次数为 k,那么 T 的任意一个子串出现的次数至少也为 k,即 T 的任意一个子串在 S 中出现的次数不会少于 T 本身。这样我们就可以断定,在所有满足条件且出现次数最多的的字符串中,一定有一个的长度恰好为 minSize。
1 | class Solution { |
1310. 子数组异或查询
Description
有一个正整数数组 arr,现给你一个对应的查询数组 queries,其中 queries[i] = [Li, Ri]。
对于每个查询 i,请你计算从 Li 到 Ri 的 XOR 值(即 arr[Li] xor arr[Li+1] xor … xor arr[Ri])作为本次查询的结果。
并返回一个包含给定查询 queries 所有结果的数组。
Example
示例 1:
输入:arr = [1,3,4,8], queries = [[0,1],[1,2],[0,3],[3,3]]
输出:[2,7,14,8]
解释:
数组中元素的二进制表示形式是:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
查询的 XOR 值为:
[0,1] = 1 xor 3 = 2
[1,2] = 3 xor 4 = 7
[0,3] = 1 xor 3 xor 4 xor 8 = 14
[3,3] = 8
示例 2:
输入:arr = [4,8,2,10], queries = [[2,3],[1,3],[0,0],[0,3]]
输出:[8,0,4,4]
提示:
$$1 <= arr.length <= 3 * 10^4 \\
1 <= arr[i] <= 10^9 \\
1 <= queries.length <= 3 * 10^4 \\
queries[i].length == 2 \\
0 <= queries[i][0] <= queries[i][1] < arr.length$$
Program
1 | class Solution { |
1318. 或运算的最小翻转次数
Description
给你三个正整数 a、b 和 c。
你可以对 a 和 b 的二进制表示进行位翻转操作,返回能够使按位或运算 a OR b == c 成立的最小翻转次数。
「位翻转操作」是指将一个数的二进制表示任何单个位上的 1 变成 0 或者 0 变成 1 。
Example
示例 1:
输入:a = 2, b = 6, c = 5
输出:3
解释:翻转后 a = 1 , b = 4 , c = 5 使得 a OR b == c
示例 2:
输入:a = 4, b = 2, c = 7
输出:1
示例 3:
输入:a = 1, b = 2, c = 3
输出:0
提示:
1 <= a <= 10^9
1 <= b <= 10^9
1 <= c <= 10^9
Program
1 | class Solution { |
721. 账户合并
Description
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该帐户的邮箱地址。
现在,我们想合并这些帐户。如果两个帐户都有一些共同的邮件地址,则两个帐户必定属于同一个人。请注意,即使两个帐户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的帐户,但其所有帐户都具有相同的名称。
合并帐户后,按以下格式返回帐户:每个帐户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。accounts 本身可以以任意顺序返回。
Example
例子 1:
1 | Input: |
Explanation:
1 | 第一个和第三个 John 是同一个人,因为他们有共同的电子邮件 "johnsmith@mail.com"。 |
注意:
accounts的长度将在[1,1000]的范围内。
accounts[i]的长度将在[1,10]的范围内。
accounts[i][j]的长度将在[1,30]的范围内。
Program
1 | //超时,注意合并操作,复杂度O(10^6*300*log2(10)) |
1 | class Solution { |
1 | //O(10000) |
947. 移除最多的同行或同列石头
Description
在二维平面上,我们将石头放置在一些整数坐标点上。每个坐标点上最多只能有一块石头。
现在,move 操作将会移除与网格上的某一块石头共享一列或一行的一块石头。
我们最多能执行多少次 move 操作?
Example
示例 1:
输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
输出:5
示例 2:
输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
输出:3
示例 3:
输入:stones = [[0,0]]
输出:0
Program
1 | class Solution { |
959. 由斜杠划分区域
Description
在由 1 x 1 方格组成的 N x N 网格 grid 中,每个 1 x 1 方块由 /、\ 或空格构成。这些字符会将方块划分为一些共边的区域。
(请注意,反斜杠字符是转义的,因此 \ 用 “\“ 表示。)。
返回区域的数目。
Example
示例 1:
输入:
[
“ /“,
“/ “
]
输出:2
解释:2x2 网格如下:
示例 2:
输入:
[
“ /“,
“ “
]
输出:1
解释:2x2 网格如下:
示例 3:
输入:
[
“\/“,
“/\“
]
输出:4
解释:(回想一下,因为 \ 字符是转义的,所以 “\/“ 表示 /,而 “/\“ 表示 /\。)
2x2 网格如下:
示例 4:
输入:
[
“/\“,
“\/“
]
输出:5
解释:(回想一下,因为 \ 字符是转义的,所以 “/\“ 表示 /\,而 “\/“ 表示 /。)
2x2 网格如下:
示例 5:
输入:
[
“//“,
“/ “
]
输出:3
解释:2x2 网格如下:
提示:
1 <= grid.length == grid[0].length <= 30
grid[i][j] 是 ‘/‘、’'、或 ‘ ‘。
Program
1 | /* |
1 | /* |
990. 等式方程的可满足性
Description
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为 4,并采用两种不同的形式之一:”a==b” 或 “a!=b”。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
Example
示例 1:
输入:[“a==b”,”b!=a”]
输出:false
解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。
示例 2:
输出:[“b==a”,”a==b”]
输入:true
解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。
示例 3:
输入:[“a==b”,”b==c”,”a==c”]
输出:true
示例 4:
输入:[“a==b”,”b!=c”,”c==a”]
输出:false
示例 5:
输入:[“c==c”,”b==d”,”x!=z”]
输出:true
提示:
1 <= equations.length <= 500
equations[i].length == 4
equations[i][0] 和 equations[i][3] 是小写字母
equations[i][1] 要么是 ‘=’,要么是 ‘!’
equations[i][2] 是 ‘=’
Program
1 | class Solution { |
1202. 交换字符串中的元素
Description
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。
你可以 任意多次交换 在 pairs 中任意一对索引处的字符。
返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
Example
示例 1:
输入:s = “dcab”, pairs = [[0,3],[1,2]]
输出:”bacd”
解释:
交换 s[0] 和 s[3], s = “bcad”
交换 s[1] 和 s[2], s = “bacd”
示例 2:
输入:s = “dcab”, pairs = [[0,3],[1,2],[0,2]]
输出:”abcd”
解释:
交换 s[0] 和 s[3], s = “bcad”
交换 s[0] 和 s[2], s = “acbd”
交换 s[1] 和 s[2], s = “abcd”
示例 3:
输入:s = “cba”, pairs = [[0,1],[1,2]]
输出:”abc”
解释:
交换 s[0] 和 s[1], s = “bca”
交换 s[1] 和 s[2], s = “bac”
交换 s[0] 和 s[1], s = “abc”
提示:
1 <= s.length <= 10^5
0 <= pairs.length <= 10^5
0 <= pairs[i][0], pairs[i][1] < s.length
s 中只含有小写英文字母
Program
1 | /* |
1319. 连通网络的操作次数
Description
用以太网线缆将 n 台计算机连接成一个网络,计算机的编号从 0 到 n-1。线缆用 connections 表示,其中 connections[i] = [a, b] 连接了计算机 a 和 b。
网络中的任何一台计算机都可以通过网络直接或者间接访问同一个网络中其他任意一台计算机。
给你这个计算机网络的初始布线 connections,你可以拔开任意两台直连计算机之间的线缆,并用它连接一对未直连的计算机。请你计算并返回使所有计算机都连通所需的最少操作次数。如果不可能,则返回 -1 。
Example
示例 1: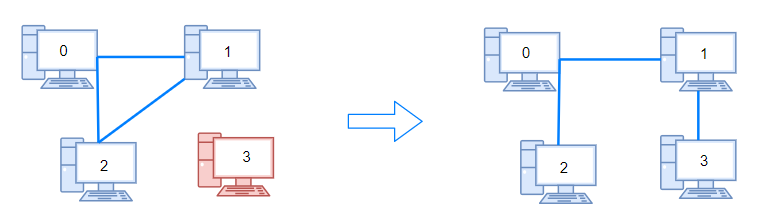
输入:n = 4, connections = [[0,1],[0,2],[1,2]]
输出:1
解释:拔下计算机 1 和 2 之间的线缆,并将它插到计算机 1 和 3 上。
示例 2: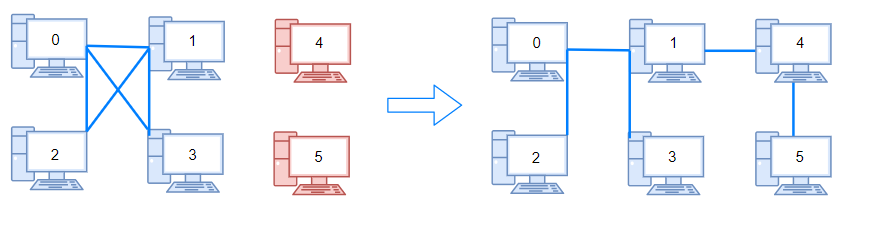
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]]
输出:2
示例 3:
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2]]
输出:-1
解释:线缆数量不足。
示例 4:
输入:n = 5, connections = [[0,1],[0,2],[3,4],[2,3]]
输出:0
提示:
1 | 1 <= n <= 10^5 |
Program
1 | /* |
95. 不同的二叉搜索树 II
Description
给定一个整数 n,生成所有由 1 … n 为节点所组成的二叉搜索树。
Example
示例:
输入: 3
输出:
[
[1,null,3,2],
[3,2,null,1],
[3,1,null,null,2],
[2,1,3],
[1,null,2,null,3]
]
解释:
以上的输出对应以下 5 种不同结构的二叉搜索树:
1 | 1 3 3 2 1 |
Program
递归中,需要遍历所有情况,但是问题在于左右子树遍历时,如果直接想得到一棵树不可能,因为一次遍历只能得到左/右子树的所有情况,所以必须拼接!!
1 | /** |
392. 判断子序列
Description
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
你可以认为 s 和 t 中仅包含英文小写字母。字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=100)。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,”ace”是”abcde”的一个子序列,而”aec”不是)。
Example
示例 1:
s = “abc”, t = “ahbgdc”
返回 true.
示例 2:
s = “axc”, t = “ahbgdc”
返回 false.
Program
1 | class Solution { |
787. K 站中转内最便宜的航班
Description
有 n 个城市通过 m 个航班连接。每个航班都从城市 u 开始,以价格 w 抵达 v。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到从 src 到 dst 最多经过 k 站中转的最便宜的价格。 如果没有这样的路线,则输出 -1。
Example
示例 1:
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
输出: 200
解释:
城市航班图如下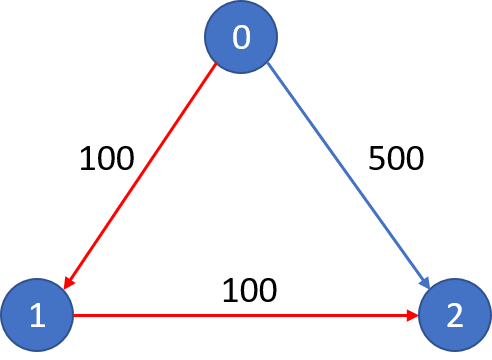
从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。
示例 2:
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 0
输出: 500
解释:
城市航班图如下
.png)
从城市 0 到城市 2 在 0 站中转以内的最便宜价格是 500,如图中蓝色所示。
提示:
n 范围是 [1, 100],城市标签从 0 到 n - 1.
航班数量范围是 [0, n * (n - 1) / 2].
每个航班的格式 (src, dst, price).
每个航班的价格范围是 [1, 10000].
k 范围是 [0, n - 1].
航班没有重复,且不存在环路
Program
最短路径Dijkstra
类似最短路径,所区别在于k与cos当做状态,并且当前节点不能vis标识掉,因为到达当前节点花费少,但步数可能多,到最后不满足。
1 | class Solution { |
②Bellman-Ford变形
Bellman-Ford算法变形,每次直走一步更新(注意不能连续更新),k+1步后就是答案,
例如,[[0,1,1],[0,2,5],[1,2,1],[2,3,1]],n=3,src=0,dst=3,k=1;
从src=0开始,第一步更新只更新从src=0出发的路径,而其他路径不能更新!否则就不是走了k+1步!
1 | class Solution { |
102. 二叉树的层次遍历
Description
给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。
Example
例如:
给定二叉树: [3,9,20,null,null,15,7],
1 | 3 |
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
Program
1 | /** |
1 | /** |
103. 二叉树的锯齿形层次遍历
Description
给定一个二叉树,返回其节点值的锯齿形层次遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
Example
例如:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
返回锯齿形层次遍历如下:
[
[3],
[20,9],
[15,7]
]
Program
1 | /** |
126. 单词接龙 II
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
每次转换只能改变一个字母。
转换后得到的单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回一个空列表。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
Example
示例 1:
输入:
beginWord = “hit”,
endWord = “cog”,
wordList = [“hot”,”dot”,”dog”,”lot”,”log”,”cog”]
输出:
[
[“hit”,”hot”,”dot”,”dog”,”cog”],
[“hit”,”hot”,”lot”,”log”,”cog”]
]
示例 2:
输入:
beginWord = “hit”
endWord = “cog”
wordList = [“hot”,”dot”,”dog”,”lot”,”log”]
输出: []
解释: endWord “cog” 不在字典中,所以不存在符合要求的转换序列。
Program
第一版
数组v记录当前进队列的Node,搞得很麻烦啊…后面可以注意到没必要,每一层访问了节点,后面就不用访问了。
1 | class Solution { |
1 | class Solution { |
优化+剪枝
继续优化,可以看到在进行下一层的搜索时,如果同时搜索到同一个单词,应当避免重复入队列!!!重复计算!没必要!
注意这里的搜索下一层时不立刻加入vis,因为可能上一层的多个结果会搜索到下一层的同一个节点!
1 | class Solution { |
127. 单词接龙
Description
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回 0。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
Example
示例 1:
输入:
beginWord = “hit”,
endWord = “cog”,
wordList = [“hot”,”dot”,”dog”,”lot”,”log”,”cog”]
输出: 5
解释: 一个最短转换序列是 “hit” -> “hot” -> “dot” -> “dog” -> “cog”,
返回它的长度 5。
示例 2:
输入:
beginWord = “hit”
endWord = “cog”
wordList = [“hot”,”dot”,”dog”,”lot”,”log”]
输出: 0
解释: endWord “cog” 不在字典中,所以无法进行转换。
Program
单向广搜(超时)
1 | class Solution { |
双向广搜
1 | class Solution { |
310. 最小高度树
Description
对于一个具有树特征的无向图,我们可选择任何一个节点作为根。图因此可以成为树,在所有可能的树中,具有最小高度的树被称为最小高度树。给出这样的一个图,写出一个函数找到所有的最小高度树并返回他们的根节点。
格式
该图包含 n 个节点,标记为 0 到 n - 1。给定数字 n 和一个无向边 edges 列表(每一个边都是一对标签)。
你可以假设没有重复的边会出现在 edges 中。由于所有的边都是无向边, [0, 1]和 [1, 0] 是相同的,因此不会同时出现在 edges 里。
Example
示例 1:
输入: n = 4, edges = [[1, 0], [1, 2], [1, 3]]
1 | 0 |
输出: [1]
示例 2:
输入: n = 6, edges = [[0, 3], [1, 3], [2, 3], [4, 3], [5, 4]]
1 | 0 1 2 |
输出: [3, 4]
说明:
根据树的定义,树是一个无向图,其中任何两个顶点只通过一条路径连接。 换句话说,一个任何没有简单环路的连通图都是一棵树。
树的高度是指根节点和叶子节点之间最长向下路径上边的数量。
Program
思路
一次性删除度为1的节点,直至最后剩余节点数不超过2。
1 | class Solution { |
914. 卡牌分组
Description
给定一副牌,每张牌上都写着一个整数。
此时,你需要选定一个数字 X,使我们可以将整副牌按下述规则分成 1 组或更多组:
每组都有 X 张牌。
组内所有的牌上都写着相同的整数。
仅当你可选的 X >= 2 时返回 true。
Example
示例 1:
输入:[1,2,3,4,4,3,2,1]
输出:true
解释:可行的分组是 [1,1],[2,2],[3,3],[4,4]
示例 2:
输入:[1,1,1,2,2,2,3,3]
输出:false
解释:没有满足要求的分组。
示例 3:
输入:[1]
输出:false
解释:没有满足要求的分组。
示例 4:
输入:[1,1]
输出:true
解释:可行的分组是 [1,1]
示例 5:
输入:[1,1,2,2,2,2]
输出:true
解释:可行的分组是 [1,1],[2,2],[2,2]
提示:
1 <= deck.length <= 10000
0 <= deck[i] < 10000
Program
1 | class Solution { |
820. 单词的压缩编码
Description
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 [“time”, “me”, “bell”],我们就可以将其表示为 S = “time#bell#” 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 “#” 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
Example
示例:
输入: words = [“time”, “me”, “bell”]
输出: 10
说明: S = “time#bell#” , indexes = [0, 2, 5] 。
提示:
1 <= words.length <= 2000
1 <= words[i].length <= 7
每个单词都是小写字母 。
Program
集合去重,而后删除重复后缀。
1 | class Solution { |
字典树
1 | class Solution { |
417. 太平洋大西洋水流问题
Description
给定一个 m x n 的非负整数矩阵来表示一片大陆上各个单元格的高度。“太平洋”处于大陆的左边界和上边界,而“大西洋”处于大陆的右边界和下边界。
规定水流只能按照上、下、左、右四个方向流动,且只能从高到低或者在同等高度上流动。
请找出那些水流既可以流动到“太平洋”,又能流动到“大西洋”的陆地单元的坐标。
提示:
输出坐标的顺序不重要
m 和 n 都小于150
Example
示例:
给定下面的 5x5 矩阵:
1 | 太平洋 ~ ~ ~ ~ ~ |
返回:
[[0, 4], [1, 3], [1, 4], [2, 2], [3, 0], [3, 1], [4, 0]] (上图中带括号的单元).
Program
从外围开始反向搜索,高或相等的海拔可以流过!还能避免重复计算。
1 | class Solution { |
vis[i][j]值为0,1,2,3,4时,分别表示未计算、太平洋、大西洋、已加入结果集合。
1 | class Solution { |
1162. 地图分析
Description
你现在手里有一份大小为 N x N 的『地图』(网格) grid,上面的每个『区域』(单元格)都用 0 和 1 标记好了。其中 0 代表海洋,1 代表陆地,你知道距离陆地区域最远的海洋区域是是哪一个吗?请返回该海洋区域到离它最近的陆地区域的距离。
我们这里说的距离是『曼哈顿距离』( Manhattan Distance):(x0, y0) 和 (x1, y1) 这两个区域之间的距离是 |x0 - x1| + |y0 - y1| 。
如果我们的地图上只有陆地或者海洋,请返回 -1。
Example
示例 1:
输入:[[1,0,1],[0,0,0],[1,0,1]]
输出:2
解释:
海洋区域 (1, 1) 和所有陆地区域之间的距离都达到最大,最大距离为 2。
示例 2:
输入:[[1,0,0],[0,0,0],[0,0,0]]
输出:4
解释:
海洋区域 (2, 2) 和所有陆地区域之间的距离都达到最大,最大距离为 4。
提示:
1 <= grid.length == grid[0].length <= 100
grid[i][j] 不是 0 就是 1
Program
超时
最暴力的方法,嘿嘿话说O(5000*5000)貌似不超时啊,卡时间哦。。
1 | class Solution { |
DP
考虑优化方法二中的「把陆地区域作为源点集、海洋区域作为目标点集,求最短路」的过程。我们知道对于每个海洋区域 (x, y)(x,y),离它最近的陆地区域到它的路径要么从上方或者左方来,要么从右方或者下方来。考虑做两次动态规划,第一次从左上到右下,第二次从右下到左上,记 f(x, y)f(x,y) 为 (x, y)(x,y) 距离最近的陆地区域的曼哈顿距离,则我们可以推出这样的转移方程:
第一阶段
当(x,y)为海洋,f(x,y)=min(f(x-1,y),f(x,y-1))+1;否则f(x,y)=0
第二阶段
当(x,y)为海洋,f(x,y)=min(f(x+1,y),f(x,y+1))+1;否则f(x,y)=0
我们初始化的时候把陆地的 f 值全部预置为 0,海洋的 f 全部预置为 INF,做完两个阶段的动态规划后,我们在所有的不为零的 f[i][j] 中比一个最大值即可,如果最终比较出的最大值为 INF,就返回 -1。
思考:如果用 f(x, y)f(x,y) 记录左上方的 DP 结果,g(x, y)g(x,y) 记录右下方的DP结果可行吗? 答案是不可行。因为考虑距离点 (x, y)(x,y) 最近的点可能既不来自左上方,也不来自右下方,比如它来自右上方,这个时候,第二阶段我们就需要用到第一阶段的计算结果。
1 | class Solution { |
广搜
$O(n^4)$
1 | class Solution { |
广搜+填充法
由陆地开始广搜,已经计算过的都不用重复计算,因为广搜的性质,一定是最短距离!所以只要所有点都计算完毕就出结果了!
$O(n^2)$
1 | class Solution { |
面试题62. 圆圈中最后剩下的数字
Description
0,1,,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
Example
示例 1:
输入: n = 5, m = 3
输出: 3
示例 2:
输入: n = 10, m = 17
输出: 2
限制:
1 <= n <= 10^5
1 <= m <= 10^6
Program
暴力超时
1 | class Solution { |
数学+迭代
参考: 约瑟夫环
简单来说,例如N=10, M=3,如下:
| N\index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 逆推公式 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 0 | 1 | √ | 3 | 4 | 5 | 6 | 7 | 8 | 9 | f(10,3)=(f(9,3)+3)%10=3 |
| 9 | 7 | 8 | × | 0 | 1 | √ | 3 | 4 | 5 | 6 | f(9,3)=(f(8,3)+3)%9=0 |
| 8 | 4 | 5 | × | 6 | 7 | × | 0 | 1 | √ | 3 | f(8,3)=(f(7,3)+3)%8=6 |
| 7 | 1 | √ | × | 3 | 4 | × | 5 | 6 | × | 0 | f(7,3)=(f(6,3)+3)%7=3 |
| 6 | 5 | × | × | 0 | 1 | × | √ | 3 | × | 4 | f(6,3)=(f(5,3)+3)%6=0 |
| 5 | √ | × | × | 3 | 4 | × | × | 0 | × | 1 | f(5,3)=(f(4,3)+3)%5=3 |
| 4 | × | × | × | 0 | 1 | × | × | √ | × | 3 | f(4,3)=(f(3,3)+3)%4=0 |
| 3 | × | × | × | 1 | √ | × | × | × | × | 0 | f(3,3)=(f(2,3)+3)%3=1 |
| 2 | × | × | × | 1 | × | × | × | × | × | √ | f(2,3)=(f(1,3)+3)%2=1 |
| 1 | × | × | × | √ | × | × | × | × | × | × | f(1,3)=0 |
每次新环从上一轮杀死的下一个元素从0开始计数,所以之后每一轮都是杀死第m个元素
这里逆推:下一轮出局的元素在上一轮的位置,old_index=(new_index+M)%old_N;详见最后一列,从下往上递推!
1 | class Solution { |
513. 找树左下角的值
Description
给定一个二叉树,在树的最后一行找到最左边的值。
Example
示例 1:
输入:
1 | 2 |
输出:
1
示例 2:
输入:
1 | 1 |
输出:
7
注意: 您可以假设树(即给定的根节点)不为 NULL。
Program
1 | /** |
515. 在每个树行中找最大值
Description
您需要在二叉树的每一行中找到最大的值。
Example
示例:
输入:
1 | 1 |
输出: [1, 3, 9]
Program
1 | /** |
529. 扫雷游戏
Description
让我们一起来玩扫雷游戏!
给定一个代表游戏板的二维字符矩阵。 ‘M’ 代表一个未挖出的地雷,’E’ 代表一个未挖出的空方块,’B’ 代表没有相邻(上,下,左,右,和所有4个对角线)地雷的已挖出的空白方块,数字(’1’ 到 ‘8’)表示有多少地雷与这块已挖出的方块相邻,’X’ 则表示一个已挖出的地雷。
现在给出在所有未挖出的方块中(’M’或者’E’)的下一个点击位置(行和列索引),根据以下规则,返回相应位置被点击后对应的面板:
如果一个地雷(’M’)被挖出,游戏就结束了- 把它改为 ‘X’。
如果一个没有相邻地雷的空方块(’E’)被挖出,修改它为(’B’),并且所有和其相邻的方块都应该被递归地揭露。
如果一个至少与一个地雷相邻的空方块(’E’)被挖出,修改它为数字(’1’到’8’),表示相邻地雷的数量。
如果在此次点击中,若无更多方块可被揭露,则返回面板。
Example
示例 1:
输入:
[[‘E’, ‘E’, ‘E’, ‘E’, ‘E’],
[‘E’, ‘E’, ‘M’, ‘E’, ‘E’],
[‘E’, ‘E’, ‘E’, ‘E’, ‘E’],
[‘E’, ‘E’, ‘E’, ‘E’, ‘E’]]
Click : [3,0]
输出:
[[‘B’, ‘1’, ‘E’, ‘1’, ‘B’],
[‘B’, ‘1’, ‘M’, ‘1’, ‘B’],
[‘B’, ‘1’, ‘1’, ‘1’, ‘B’],
[‘B’, ‘B’, ‘B’, ‘B’, ‘B’]]
解释:
示例 2:
输入:
[[‘B’, ‘1’, ‘E’, ‘1’, ‘B’],
[‘B’, ‘1’, ‘M’, ‘1’, ‘B’],
[‘B’, ‘1’, ‘1’, ‘1’, ‘B’],
[‘B’, ‘B’, ‘B’, ‘B’, ‘B’]]
Click : [1,2]
输出:
[[‘B’, ‘1’, ‘E’, ‘1’, ‘B’],
[‘B’, ‘1’, ‘X’, ‘1’, ‘B’],
[‘B’, ‘1’, ‘1’, ‘1’, ‘B’],
[‘B’, ‘B’, ‘B’, ‘B’, ‘B’]]
解释:
注意:
输入矩阵的宽和高的范围为 [1,50]。
点击的位置只能是未被挖出的方块 (‘M’ 或者 ‘E’),这也意味着面板至少包含一个可点击的方块。
输入面板不会是游戏结束的状态(即有地雷已被挖出)。
简单起见,未提及的规则在这个问题中可被忽略。例如,当游戏结束时你不需要挖出所有地雷,考虑所有你可能赢得游戏或标记方块的情况。
Program
广搜
注意如果相邻位置有地雷,没有要求递归揭露!也就是说,这种情况直接停止搜索。
1 | class Solution { |
542. 01 矩阵
Description
给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。
两个相邻元素间的距离为 1 。
Example
示例 1:
输入:
0 0 0
0 1 0
0 0 0
输出:
0 0 0
0 1 0
0 0 0
示例 2:
输入:
0 0 0
0 1 0
1 1 1
输出:
0 0 0
0 1 0
1 2 1
注意:
给定矩阵的元素个数不超过 10000。
给定矩阵中至少有一个元素是 0。
矩阵中的元素只在四个方向上相邻: 上、下、左、右。
Program
1 | class Solution { |
690. 员工的重要性
Description
给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id。
比如,员工1是员工2的领导,员工2是员工3的领导。他们相应的重要度为15, 10, 5。那么员工1的数据结构是[1, 15, [2]],员工2的数据结构是[2, 10, [3]],员工3的数据结构是[3, 5, []]。注意虽然员工3也是员工1的一个下属,但是由于并不是直系下属,因此没有体现在员工1的数据结构中。
现在输入一个公司的所有员工信息,以及单个员工id,返回这个员工和他所有下属的重要度之和。
Example
示例 1:
输入: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1
输出: 11
解释:
员工1自身的重要度是5,他有两个直系下属2和3,而且2和3的重要度均为3。因此员工1的总重要度是 5 + 3 + 3 = 11。
注意:
一个员工最多有一个直系领导,但是可以有多个直系下属
员工数量不超过2000。
Program
1 | /* |
743. 网络延迟时间
Description
有 N 个网络节点,标记为 1 到 N。
给定一个列表 times,表示信号经过有向边的传递时间。 times[i] = (u, v, w),其中 u 是源节点,v 是目标节点, w 是一个信号从源节点传递到目标节点的时间。
现在,我们从某个节点 K 发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1。
Example
示例:
输入:times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2
输出:2
注意:
N 的范围在 [1, 100] 之间。
K 的范围在 [1, N] 之间。
times 的长度在 [1, 6000] 之间。
所有的边 times[i] = (u, v, w) 都有 1 <= u, v <= N 且 0 <= w <= 100。
Program
1 | class Solution { |
752. 打开转盘锁
Description
你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’ 。每个拨轮可以自由旋转:例如把 ‘9’ 变为 ‘0’,’0’ 变为 ‘9’ 。每次旋转都只能旋转一个拨轮的一位数字。
锁的初始数字为 ‘0000’ ,一个代表四个拨轮的数字的字符串。
列表 deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。
字符串 target 代表可以解锁的数字,你需要给出最小的旋转次数,如果无论如何不能解锁,返回 -1。
Example
示例 1:
输入:deadends = [“0201”,”0101”,”0102”,”1212”,”2002”], target = “0202”
输出:6
解释:
可能的移动序列为 “0000” -> “1000” -> “1100” -> “1200” -> “1201” -> “1202” -> “0202”。
注意 “0000” -> “0001” -> “0002” -> “0102” -> “0202” 这样的序列是不能解锁的,
因为当拨动到 “0102” 时这个锁就会被锁定。
示例 2:
输入: deadends = [“8888”], target = “0009”
输出:1
解释:
把最后一位反向旋转一次即可 “0000” -> “0009”。
示例 3:
输入: deadends = [“8887”,”8889”,”8878”,”8898”,”8788”,”8988”,”7888”,”9888”], target = “8888”
输出:-1
解释:
无法旋转到目标数字且不被锁定。
示例 4:
输入: deadends = [“0000”], target = “8888”
输出:-1
提示:
死亡列表 deadends 的长度范围为 [1, 500]。
目标数字 target 不会在 deadends 之中。
每个 deadends 和 target 中的字符串的数字会在 10,000 个可能的情况 ‘0000’ 到 ‘9999’ 中产生。
Program
1 | class Solution { |
429. N叉树的层序遍历
Description
给定一个 N 叉树,返回其节点值的层序遍历。 (即从左到右,逐层遍历)。
Example
例如,给定一个 3叉树 :
返回其层序遍历:
1 | [ |
说明:
树的深度不会超过 1000。
树的节点总数不会超过 5000。
Program
1 | /* |
559. N叉树的最大深度
Description
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
Example
例如,给定一个 3叉树 :
我们应返回其最大深度,3。
说明:
树的深度不会超过 1000。
树的节点总不会超过 5000。
Program
1 | /* |
785. 判断二分图
Description
给定一个无向图graph,当这个图为二分图时返回true。
如果我们能将一个图的节点集合分割成两个独立的子集A和B,并使图中的每一条边的两个节点一个来自A集合,一个来自B集合,我们就将这个图称为二分图。
graph将会以邻接表方式给出,graph[i]表示图中与节点i相连的所有节点。每个节点都是一个在0到graph.length-1之间的整数。这图中没有自环和平行边: graph[i] 中不存在i,并且graph[i]中没有重复的值。
Example
示例 1:
输入: [[1,3], [0,2], [1,3], [0,2]]
输出: true
解释:
无向图如下:
1 | 0----1 |
我们可以将节点分成两组: {0, 2} 和 {1, 3}。
示例 2:
输入: [[1,2,3], [0,2], [0,1,3], [0,2]]
输出: false
解释:
无向图如下:
1 | 0----1 |
我们不能将节点分割成两个独立的子集。
注意:
graph 的长度范围为 [1, 100]。
graph[i] 中的元素的范围为 [0, graph.length - 1]。
graph[i] 不会包含 i 或者有重复的值。
图是无向的: 如果j 在 graph[i]里边, 那么 i 也会在 graph[j]里边。
Program
1 | class Solution { |
863. 二叉树中所有距离为 K 的结点
Description
给定一个二叉树(具有根结点 root), 一个目标结点 target ,和一个整数值 K 。
返回到目标结点 target 距离为 K 的所有结点的值的列表。 答案可以以任何顺序返回。
Example
示例 1:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2
输出:[7,4,1]
解释:
所求结点为与目标结点(值为 5)距离为 2 的结点,
值分别为 7,4,以及 1
注意,输入的 “root” 和 “target” 实际上是树上的结点。
上面的输入仅仅是对这些对象进行了序列化描述。
提示:
给定的树是非空的,且最多有 K 个结点。
树上的每个结点都具有唯一的值 0 <= node.val <= 500 。
目标结点 target 是树上的结点。
0 <= K <= 1000.
Program
1 | /** |
909. 蛇梯棋
Description
在一块 N x N 的棋盘 board 上,从棋盘的左下角开始,每一行交替方向,按从 1 到 NN 的数字给方格编号。例如,对于一块 6 x 6 大小的棋盘,可以编号如下: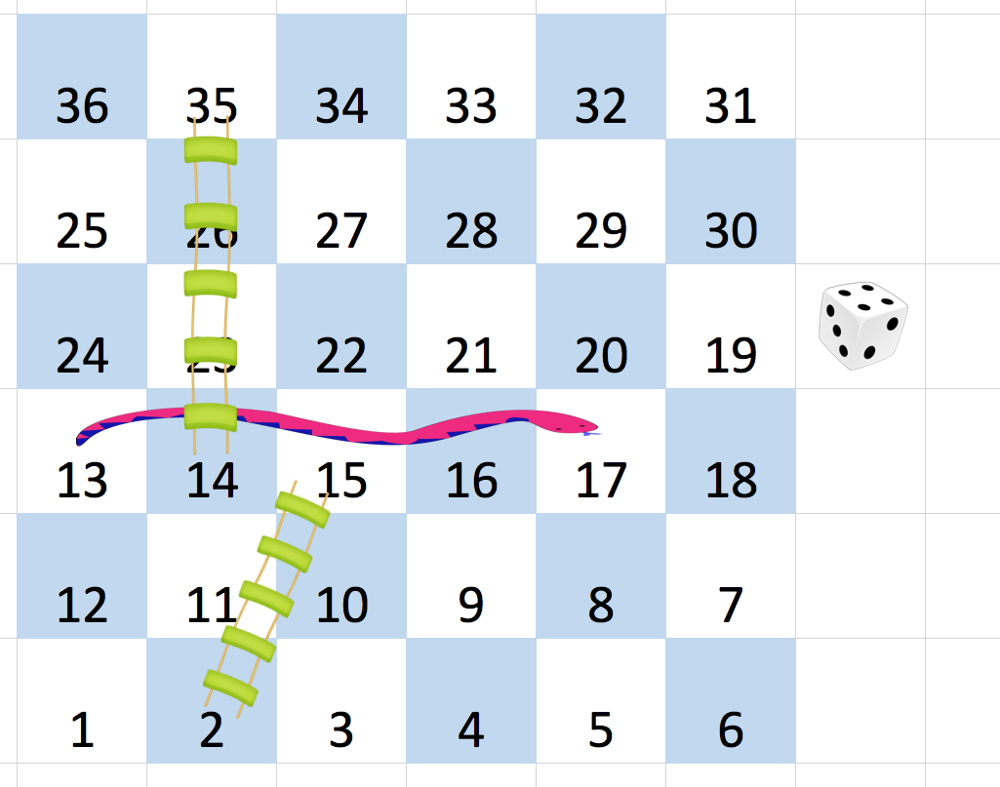
玩家从棋盘上的方格 1 (总是在最后一行、第一列)开始出发。
每一次从方格 x 起始的移动都由以下部分组成:
你选择一个目标方块 S,它的编号是 x+1,x+2,x+3,x+4,x+5,或者 x+6,只要这个数字 <= NN。
如果 S 有一个蛇或梯子,你就移动到那个蛇或梯子的目的地。否则,你会移动到 S。
在 r 行 c 列上的方格里有 “蛇” 或 “梯子”;如果 board[r][c] != -1,那个蛇或梯子的目的地将会是 board[r][c]。
注意,你每次移动最多只能爬过蛇或梯子一次:就算目的地是另一条蛇或梯子的起点,你也不会继续移动。
返回达到方格 NN 所需的最少移动次数,如果不可能,则返回 -1。
*Example**
示例:
输入:
1 | [[-1,-1,-1,-1,-1,-1], |
输出:4
解释:
首先,从方格 1 [第 5 行,第 0 列] 开始。
你决定移动到方格 2,并必须爬过梯子移动到到方格 15。
然后你决定移动到方格 17 [第 3 行,第 5 列],必须爬过蛇到方格 13。
然后你决定移动到方格 14,且必须通过梯子移动到方格 35。
然后你决定移动到方格 36, 游戏结束。
可以证明你需要至少 4 次移动才能到达第 N*N 个方格,所以答案是 4。
提示:
2 <= board.length = board[0].length <= 20
board[i][j] 介于 1 和 NN 之间或者等于 -1。
编号为 1 的方格上没有蛇或梯子。
编号为 NN 的方格上没有蛇或梯子。
Program
坑点就是一条捷径的终点如果又是另一条捷径的起点,那么走了前一条捷径到达该捷径的终点后,不能走该捷径终点作为另一条捷径起点的那条捷径了!
1 | class Solution { |
934. 最短的桥
Description
在给定的二维二进制数组 A 中,存在两座岛。(岛是由四面相连的 1 形成的一个最大组。)
现在,我们可以将 0 变为 1,以使两座岛连接起来,变成一座岛。
返回必须翻转的 0 的最小数目。(可以保证答案至少是 1。)
Example
示例 1:
输入:[[0,1],[1,0]]
输出:1
示例 2:
输入:[[0,1,0],[0,0,0],[0,0,1]]
输出:2
示例 3:
输入:[[1,1,1,1,1],[1,0,0,0,1],[1,0,1,0,1],[1,0,0,0,1],[1,1,1,1,1]]
输出:1
提示:
1 <= A.length = A[0].length <= 100
A[i][j] == 0 或 A[i][j] == 1
Program
先通过DFS标记一个岛,之后将另一个岛的坐标加入队列,最后广搜即可。
1 | class Solution { |
993. 二叉树的堂兄弟节点
Description
在二叉树中,根节点位于深度 0 处,每个深度为 k 的节点的子节点位于深度 k+1 处。
如果二叉树的两个节点深度相同,但父节点不同,则它们是一对堂兄弟节点。
我们给出了具有唯一值的二叉树的根节点 root,以及树中两个不同节点的值 x 和 y。
只有与值 x 和 y 对应的节点是堂兄弟节点时,才返回 true。否则,返回 false。
Example
示例 1:
输入:root = [1,2,3,4], x = 4, y = 3
输出:false
示例 2:
输入:root = [1,2,3,null,4,null,5], x = 5, y = 4
输出:true
示例 3:
输入:root = [1,2,3,null,4], x = 2, y = 3
输出:false
提示:
二叉树的节点数介于 2 到 100 之间。
每个节点的值都是唯一的、范围为 1 到 100 的整数。
Program
1 | /** |
1091. 二进制矩阵中的最短路径
Description
在一个 N × N 的方形网格中,每个单元格有两种状态:空(0)或者阻塞(1)。
一条从左上角到右下角、长度为 k 的畅通路径,由满足下述条件的单元格 C_1, C_2, …, C_k 组成:
相邻单元格 C_i 和 C_{i+1} 在八个方向之一上连通(此时,C_i 和 C_{i+1} 不同且共享边或角)
C_1 位于 (0, 0)(即,值为 grid[0][0])
C_k 位于 (N-1, N-1)(即,值为 grid[N-1][N-1])
如果 C_i 位于 (r, c),则 grid[r][c] 为空(即,grid[r][c] == 0)
返回这条从左上角到右下角的最短畅通路径的长度。如果不存在这样的路径,返回 -1 。
Example
示例 1:
输入:[[0,1],[1,0]]
输出:2
示例 2:
输入:[[0,0,0],[1,1,0],[1,1,0]]
输出:4
提示:
1 <= grid.length == grid[0].length <= 100
grid[i][j] 为 0 或 1
Program
1 | class Solution { |
994. 腐烂的橘子
Description
在给定的网格中,每个单元格可以有以下三个值之一:
值 0 代表空单元格;
值 1 代表新鲜橘子;
值 2 代表腐烂的橘子。
每分钟,任何与腐烂的橘子(在 4 个正方向上)相邻的新鲜橘子都会腐烂。
返回直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1。
Example
示例 1:
输入:[[2,1,1],[1,1,0],[0,1,1]]
输出:4
示例 2:
输入:[[2,1,1],[0,1,1],[1,0,1]]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个正向上。
示例 3:
输入:[[0,2]]
输出:0
解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。
提示:
1 <= grid.length <= 10
1 <= grid[0].length <= 10
grid[i][j] 仅为 0、1 或 2
Program
1 | class Solution { |
面试题 04.03. 特定深度节点链表
Description
给定一棵二叉树,设计一个算法,创建含有某一深度上所有节点的链表(比如,若一棵树的深度为 D,则会创建出 D 个链表)。返回一个包含所有深度的链表的数组。
Example
示例:
输入:[1,2,3,4,5,null,7,8]
1 | 1 |
输出:[[1],[2,3],[4,5,7],[8]]
Program
1 | /** |
建设道路
Description
牛牛国有 nn 个城市,编号为 1…n,第 i 个城市有一个价值$a_i$,牛国的国王牛阔落特别喜欢在牛牛国旅游,并且他不想每次旅游的时候都计算一遍走哪条路最短,于是他决定在任意两个城市之间建立一条双向道路,在第$i$座城市和第$j$座城市之间建立双向道路的代价是 $(a_i-a_j)^2$,牛阔落希望你能算出这项工程的花费。由于答案太大,你只需要输出答案模 $1e9+7$ 的余数
Example
输入描述:
第一行一个整数 n,表示城市的数量。
第二行 n 以空格分隔的整数 a1,a2,…,an,表示第i座城市的价值。
输出描述:
输出一行一个数字,表示工程的花费模 1e9+7的余数
示例1
输入
复制
3
1 2 3
输出
复制
6
说明
城市1到城市2的道路价值是(2 - 1)^ 2 = 1
城市2到城市3的道路价值是(3 - 2)^ 2 = 1
城市1到城市3的道路价值是(3 - 1)^ 2 = 4
总的花费 = 1 + 1 + 4 = 6
备注:
$1≤n≤5e5,1e91≤ai≤1e9$
建议使用scanf读入
Program
1 |
|
1129. 颜色交替的最短路径
Description
在一个有向图中,节点分别标记为 0, 1, …, n-1。这个图中的每条边不是红色就是蓝色,且存在自环或平行边。
red_edges 中的每一个 [i, j] 对表示从节点 i 到节点 j 的红色有向边。类似地,blue_edges 中的每一个 [i, j] 对表示从节点 i 到节点 j 的蓝色有向边。
返回长度为 n 的数组 answer,其中 answer[X] 是从节点 0 到节点 X 的最短路径的长度,且路径上红色边和蓝色边交替出现。如果不存在这样的路径,那么 answer[x] = -1。
Example
示例 1:
输入:n = 3, red_edges = [[0,1],[1,2]], blue_edges = []
输出:[0,1,-1]
示例 2:
输入:n = 3, red_edges = [[0,1]], blue_edges = [[2,1]]
输出:[0,1,-1]
示例 3:
输入:n = 3, red_edges = [[1,0]], blue_edges = [[2,1]]
输出:[0,-1,-1]
示例 4:
输入:n = 3, red_edges = [[0,1]], blue_edges = [[1,2]]
输出:[0,1,2]
示例 5:
输入:n = 3, red_edges = [[0,1],[0,2]], blue_edges = [[1,0]]
输出:[0,1,1]
提示:
1 <= n <= 100
red_edges.length <= 400
blue_edges.length <= 400
red_edges[i].length == blue_edges[i].length == 2
0 <= red_edges[i][j], blue_edges[i][j] < n
Program
1 | class Solution { |
1306. 跳跃游戏 III
Description
这里有一个非负整数数组 arr,你最开始位于该数组的起始下标 start 处。当你位于下标 i 处时,你可以跳到 i + arr[i] 或者 i - arr[i]。
请你判断自己是否能够跳到对应元素值为 0 的 任意 下标处。
注意,不管是什么情况下,你都无法跳到数组之外。
Example
示例 1:
输入:arr = [4,2,3,0,3,1,2], start = 5
输出:true
解释:
到达值为 0 的下标 3 有以下可能方案:
下标 5 -> 下标 4 -> 下标 1 -> 下标 3
下标 5 -> 下标 6 -> 下标 4 -> 下标 1 -> 下标 3
示例 2:
输入:arr = [4,2,3,0,3,1,2], start = 0
输出:true
解释:
到达值为 0 的下标 3 有以下可能方案:
下标 0 -> 下标 4 -> 下标 1 -> 下标 3
示例 3:
输入:arr = [3,0,2,1,2], start = 2
输出:false
解释:无法到达值为 0 的下标 1 处。
提示:
1 | 1 <= arr.length <= 5 * 10^4 |
Program
1 | class Solution { |
1311. 获取你好友已观看的视频
Description
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id 。
给你数组 watchedVideos 和 friends ,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。
Level 1 的视频包含所有你好友观看过的视频,level 2 的视频包含所有你好友的好友观看过的视频,以此类推。一般的,Level 为 k 的视频包含所有从你出发,最短距离为 k 的好友观看过的视频。
给定你的 id 和一个 level 值,请你找出所有指定 level 的视频,并将它们按观看频率升序返回。如果有频率相同的视频,请将它们按字母顺序从小到大排列。
Example
示例 1:
输入:watchedVideos = [[“A”,”B”],[“C”],[“B”,”C”],[“D”]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1
输出:[“B”,”C”]
解释:
你的 id 为 0(绿色),你的朋友包括(黄色):
id 为 1 -> watchedVideos = [“C”]
id 为 2 -> watchedVideos = [“B”,”C”]
你朋友观看过视频的频率为:
B -> 1
C -> 2
示例 2:
输入:watchedVideos = [[“A”,”B”],[“C”],[“B”,”C”],[“D”]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 2
输出:[“D”]
解释:
你的 id 为 0(绿色),你朋友的朋友只有一个人,他的 id 为 3(黄色)。
提示:
1 | n == watchedVideos.length == friends.length |
Program
1 | class Solution { |
面试题32 - I. 从上到下打印二叉树
Description
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
Example
例如:
给定二叉树: [3,9,20,null,null,15,7],
···
3
/
9 20
/
15 7
···
返回:
[3,9,20,15,7]
提示:
节点总数 <= 1000
Program
1 | /** |
面试题32 - II. 从上到下打印二叉树 II
Description
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
Example
例如:
给定二叉树: [3,9,20,null,null,15,7],
1 | 3 |
返回其层次遍历结果:
1 | [ |
提示:
节点总数 <= 1000
Program
1 | /** |
面试题32 - III. 从上到下打印二叉树 III
Description
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
Example
例如:
给定二叉树: [3,9,20,null,null,15,7],
1 | 3 |
返回其层次遍历结果:
1 | [ |
提示:
节点总数 <= 1000
Program
1 | /** |
面试题 16.19. 水域大小
Description
你有一个用于表示一片土地的整数矩阵land,该矩阵中每个点的值代表对应地点的海拔高度。若值为0则表示水域。由垂直、水平或对角连接的水域为池塘。池塘的大小是指相连接的水域的个数。编写一个方法来计算矩阵中所有池塘的大小,返回值需要从小到大排序。
Example
示例:
输入:
1 | [ |
输出: [1,2,4]
提示:
1 | 0 < len(land) <= 1000 |
Program
1 | class Solution { |
面试题 17.22. 单词转换
Description
给定字典中的两个词,长度相等。写一个方法,把一个词转换成另一个词, 但是一次只能改变一个字符。每一步得到的新词都必须能在字典中找到。
编写一个程序,返回一个可能的转换序列。如有多个可能的转换序列,你可以返回任何一个。
Example
示例 1:
输入:
beginWord = “hit”,
endWord = “cog”,
wordList = [“hot”,”dot”,”dog”,”lot”,”log”,”cog”]
输出:
[“hit”,”hot”,”dot”,”lot”,”log”,”cog”]
示例 2:
输入:
beginWord = “hit”
endWord = “cog”
wordList = [“hot”,”dot”,”dog”,”lot”,”log”]
输出: []
解释: endWord “cog” 不在字典中,所以不存在符合要求的转换序列。
Program
1 | class Solution { |
面试题 17.07. 婴儿名字
Description
每年,政府都会公布一万个最常见的婴儿名字和它们出现的频率,也就是同名婴儿的数量。有些名字有多种拼法,例如,John 和 Jon 本质上是相同的名字,但被当成了两个名字公布出来。给定两个列表,一个是名字及对应的频率,另一个是本质相同的名字对。设计一个算法打印出每个真实名字的实际频率。注意,如果 John 和 Jon 是相同的,并且 Jon 和 Johnny 相同,则 John 与 Johnny 也相同,即它们有传递和对称性。
在结果列表中,选择字典序最小的名字作为真实名字。
Example
示例:
输入:names = [“John(15)”,”Jon(12)”,”Chris(13)”,”Kris(4)”,”Christopher(19)”], synonyms = [“(Jon,John)”,”(John,Johnny)”,”(Chris,Kris)”,”(Chris,Christopher)”]
输出:[“John(27)”,”Chris(36)”]
提示:
names.length <= 100000
Program
1 | class Solution { |
1 | class Solution { |
1391. 检查网格中是否存在有效路径
Description
给你一个 m x n 的网格 grid。网格里的每个单元都代表一条街道。grid[i][j] 的街道可以是:
1 表示连接左单元格和右单元格的街道。
2 表示连接上单元格和下单元格的街道。
3 表示连接左单元格和下单元格的街道。
4 表示连接右单元格和下单元格的街道。
5 表示连接左单元格和上单元格的街道。
6 表示连接右单元格和上单元格的街道。
你最开始从左上角的单元格 (0,0) 开始出发,网格中的「有效路径」是指从左上方的单元格 (0,0) 开始、一直到右下方的 (m-1,n-1) 结束的路径。该路径必须只沿着街道走。
注意:你不能变更街道。
如果网格中存在有效的路径,则返回 true,否则返回 false 。
Example
示例 1:
输入:grid = [[2,4,3],[6,5,2]]
输出:true
解释:如图所示,你可以从 (0, 0) 开始,访问网格中的所有单元格并到达 (m - 1, n - 1) 。
示例 2:
输入:grid = [[1,2,1],[1,2,1]]
输出:false
解释:如图所示,单元格 (0, 0) 上的街道没有与任何其他单元格上的街道相连,你只会停在 (0, 0) 处。
示例 3:
输入:grid = [[1,1,2]]
输出:false
解释:你会停在 (0, 1),而且无法到达 (0, 2) 。
示例 4:
输入:grid = [[1,1,1,1,1,1,3]]
输出:true
示例 5:
输入:grid = [[2],[2],[2],[2],[2],[2],[6]]
输出:true
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 300
1 <= grid[i][j] <= 6
Program
1 | class Solution { |
1282. 用户分组
Description
有 n 位用户参加活动,他们的 ID 从 0 到 n - 1,每位用户都 恰好 属于某一用户组。给你一个长度为 n 的数组 groupSizes,其中包含每位用户所处的用户组的大小,请你返回用户分组情况(存在的用户组以及每个组中用户的 ID)。
你可以任何顺序返回解决方案,ID 的顺序也不受限制。此外,题目给出的数据保证至少存在一种解决方案。
Example
示例 1:
输入:groupSizes = [3,3,3,3,3,1,3]
输出:[[5],[0,1,2],[3,4,6]]
解释:
其他可能的解决方案有 [[2,1,6],[5],[0,4,3]] 和 [[5],[0,6,2],[4,3,1]]。
示例 2:
输入:groupSizes = [2,1,3,3,3,2]
输出:[[1],[0,5],[2,3,4]]
提示:
groupSizes.length == n
1 <= n <= 500
1 <= groupSizes[i] <= n
Program
粗分组后细分组
1 | class Solution { |
1029. 两地调度
Description
公司计划面试 2N 人。第 i 人飞往 A 市的费用为 costs[i][0],飞往 B 市的费用为 costs[i][1]。
返回将每个人都飞到某座城市的最低费用,要求每个城市都有 N 人抵达。
Example
示例:
输入:[[10,20],[30,200],[400,50],[30,20]]
输出:110
解释:
第一个人去 A 市,费用为 10。
第二个人去 A 市,费用为 30。
第三个人去 B 市,费用为 50。
第四个人去 B 市,费用为 20。
最低总费用为 10 + 30 + 50 + 20 = 110,每个城市都有一半的人在面试。
提示:
1 <= costs.length <= 100
costs.length 为偶数
1 <= costs[i][0], costs[i][1] <= 1000
Program
$$min_{\lbrace x_i\rbrace}\sum_{i=1}^{2N}x_i c_{i_0} + \sum_{i=1}^{2N}(1-x_i)c_{i_1},\\
\implies min_{\lbrace x_i \rbrace}\sum_{i=1}^{2N}c_{i_1}+\sum_{i=1}^{2N}x_i(c_{i_0}-c_{i_1})\\
s.t. \sum_{i=1}^{2N}x_i = N, x_i \in \lbrace 0,1\rbrace, i=1,2,…,2N.
$$
1 | class Solution { |
1046. 最后一块石头的重量
Description
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
如果 x == y,那么两块石头都会被完全粉碎;
如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
Example
示例:
输入:[2,7,4,1,8,1]
输出:1
解释:
先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1],
再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1],
接着是 2 和 1,得到 1,所以数组转换为 [1,1,1],
最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。
提示:
1 <= stones.length <= 30
1 <= stones[i] <= 1000
Program
1 | class Solution { |
1296. 划分数组为连续数字的集合
Description
给你一个整数数组 nums 和一个正整数 k,请你判断是否可以把这个数组划分成一些由 k 个连续数字组成的集合。
如果可以,请返回 True;否则,返回 False。
Example
示例 1:
输入:nums = [1,2,3,3,4,4,5,6], k = 4
输出:true
解释:数组可以分成 [1,2,3,4] 和 [3,4,5,6]。
示例 2:
输入:nums = [3,2,1,2,3,4,3,4,5,9,10,11], k = 3
输出:true
解释:数组可以分成 [1,2,3] , [2,3,4] , [3,4,5] 和 [9,10,11]。
示例 3:
输入:nums = [3,3,2,2,1,1], k = 3
输出:true
示例 4:
输入:nums = [1,2,3,4], k = 3
输出:false
解释:数组不能分成几个大小为 3 的子数组。
提示:
1 <= nums.length <= 10^5
1 <= nums[i] <= 10^9
1 <= k <= nums.length
Program
1 | class Solution { |
1053. 交换一次的先前排列
Description
给你一个正整数的数组 A(其中的元素不一定完全不同),请你返回可在 一次交换(交换两数字 A[i] 和 A[j] 的位置)后得到的、按字典序排列小于 A 的最大可能排列。
如果无法这么操作,就请返回原数组。
Example
示例 1:
输入:[3,2,1]
输出:[3,1,2]
解释:
交换 2 和 1
示例 2:
输入:[1,1,5]
输出:[1,1,5]
解释:
这已经是最小排列
示例 3:
输入:[1,9,4,6,7]
输出:[1,7,4,6,9]
解释:
交换 9 和 7
示例 4:
输入:[3,1,1,3]
输出:[1,3,1,3]
解释:
交换 1 和 3
提示:
1 <= A.length <= 10000
1 <= A[i] <= 10000
Program
从前往后查找,发现数据变小时记录下来left和right,后续如果有数据变大并且不大于left,更新right即可。示意如下: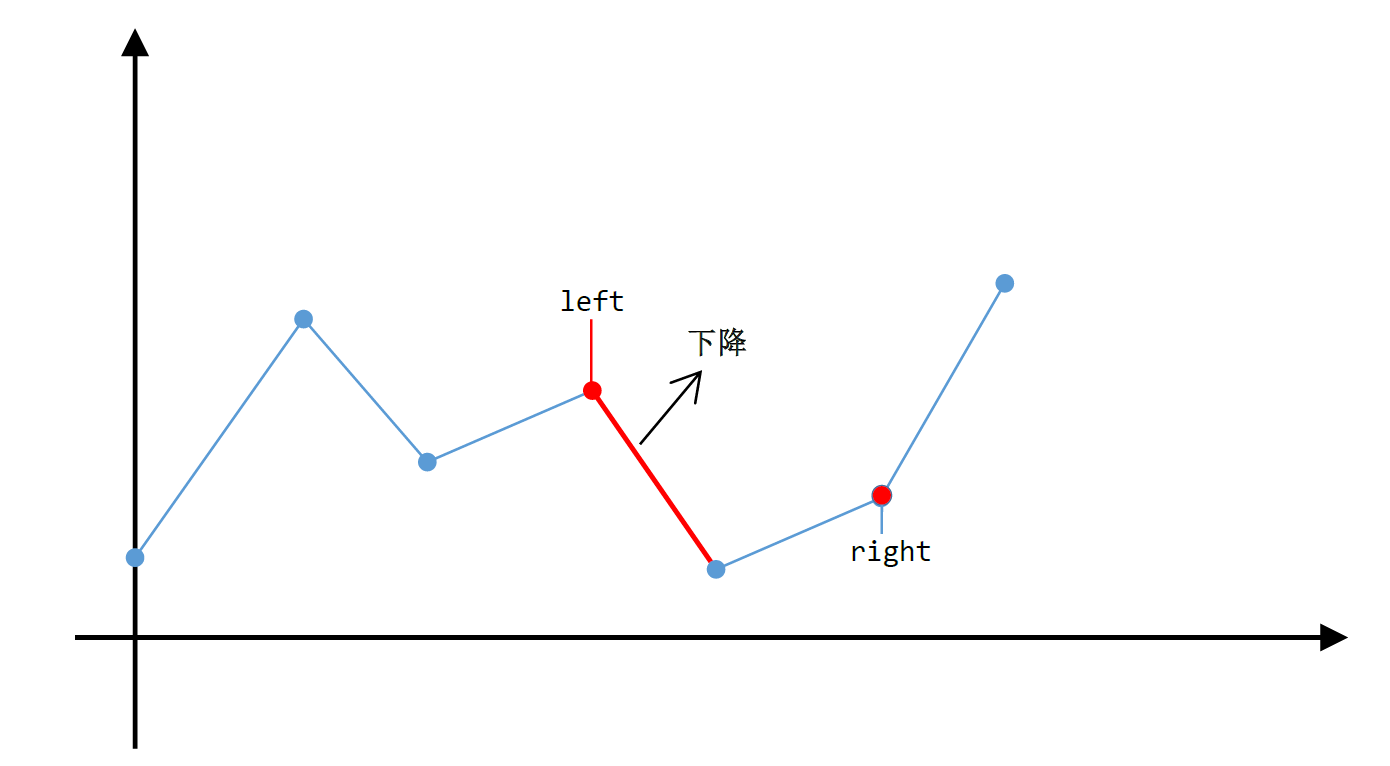
1 | class Solution { |
621. 任务调度器
Description
给定一个用字符数组表示的 CPU 需要执行的任务列表。其中包含使用大写的 A - Z 字母表示的26 种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。CPU 在任何一个单位时间内都可以执行一个任务,或者在待命状态。
然而,两个相同种类的任务之间必须有长度为 n 的冷却时间,因此至少有连续 n 个单位时间内 CPU 在执行不同的任务,或者在待命状态。
你需要计算完成所有任务所需要的最短时间。
Example
示例 :
输入:tasks = [“A”,”A”,”A”,”B”,”B”,”B”], n = 2
输出:8
解释:A -> B -> (待命) -> A -> B -> (待命) -> A -> B.
在本示例中,两个相同类型任务之间必须间隔长度为 n = 2 的冷却时间,而执行一个任务只需要一个单位时间,所以中间出现了(待命)状态。
提示:
任务的总个数为 [1, 10000]。
n 的取值范围为 [0, 100]。
Program
①排序
数量较多的优先执行,否则后面会出现大量待命状态。
考虑到长度为n的冷却时间,故同种任务在n+1个单位时间内只能出现一次。故每n+1单位时间安排任务队列(当然也可以每个单位时间安排满足要求的任务执行,但时间复杂度更高,且实现复杂),需要注意任务都执行完了的最后多余的待命状态。
1 | class Solution { |
②桶排序
建立大小为n+1的桶子,个数为任务数量最多的那个任务,比如下图,等待时间n=2,A任务个数6个,我们建立6个桶子,每个容量为3:
我们可以把一个桶子看作一轮任务
1.先从最简单的情况看起,现在就算没有其他任务,我们完成任务A所需的时间应该是(6-1)*3+1=16,因为最后一个桶子,不存在等待时间。
2.接下来我们添加些其他任务
可以看到C其实并没有对总体时间产生影响,因为它被安排在了其他任务的冷却期间;
而B和A数量相同,这会导致最后一个桶子中,我们需要多执行一次B任务,现在我们需要的时间是‘6-1)3+2=17
*前面两种情况,总结起来:总排队时间 = (桶个数 - 1) * (n + 1) + 最后一桶的任务数**
3.当冷却时间短,任务种类很多时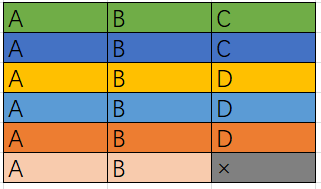
比如上图,我们刚好排满了任务,此时所需时间还是17,如果现在我还要执行两次任务F,该怎么安排呢?
此时我们可以临时扩充某些桶子的大小,插进任务F,对比一下插入前后的任务执行情况:
插入前:ABC | ABC | ABD | ABD | ABD |AB
插入后:ABCF | ABCF | ABD | ABD | ABD |AB
我们在第一个、第二个桶子里插入了任务F,不难发现无论再继续插入多少任务,我们都可以类似处理,而且新插入元素肯定满足冷却要求
继续思考一下,这种情况下其实每个任务之间都不存在空余时间,冷却时间已经被完全填满了。
也就是说,我们执行任务所需的时间,就是任务的数量
1 | 这样剩下就很好处理了,我们只需要算两个数: |
1 | class Solution { |
1090. 受标签影响的最大值
Description
我们有一个项的集合,其中第 i 项的值为 values[i],标签为 labels[i]。
我们从这些项中选出一个子集 S,这样一来:
|S| <= num_wanted
对于任意的标签 L,子集 S 中标签为 L 的项的数目总满足 <= use_limit。
返回子集 S 的最大可能的 和。
Example
示例 1:
输入:values = [5,4,3,2,1], labels = [1,1,2,2,3], num_wanted = 3, use_limit = 1
输出:9
解释:选出的子集是第一项,第三项和第五项。
示例 2:
输入:values = [5,4,3,2,1], labels = [1,3,3,3,2], num_wanted = 3, use_limit = 2
输出:12
解释:选出的子集是第一项,第二项和第三项。
示例 3:
输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 1
输出:16
解释:选出的子集是第一项和第四项。
示例 4:
输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 2
输出:24
解释:选出的子集是第一项,第二项和第四项。
提示:
1 <= values.length == labels.length <= 20000
0 <= values[i], labels[i] <= 20000
1 <= num_wanted, use_limit <= values.length
Program
1 | class Solution { |
1094. 拼车
Description
假设你是一位顺风车司机,车上最初有 capacity 个空座位可以用来载客。由于道路的限制,车 只能 向一个方向行驶(也就是说,不允许掉头或改变方向,你可以将其想象为一个向量)。
这儿有一份乘客行程计划表 trips[][],其中 trips[i] = [num_passengers, start_location, end_location] 包含了第 i 组乘客的行程信息:
必须接送的乘客数量;
乘客的上车地点;
以及乘客的下车地点。
这些给出的地点位置是从你的 初始 出发位置向前行驶到这些地点所需的距离(它们一定在你的行驶方向上)。
请你根据给出的行程计划表和车子的座位数,来判断你的车是否可以顺利完成接送所用乘客的任务(当且仅当你可以在所有给定的行程中接送所有乘客时,返回 true,否则请返回 false)。
Example
示例 1:
输入:trips = [[2,1,5],[3,3,7]], capacity = 4
输出:false
示例 2:
输入:trips = [[2,1,5],[3,3,7]], capacity = 5
输出:true
示例 3:
输入:trips = [[2,1,5],[3,5,7]], capacity = 3
输出:true
示例 4:
输入:trips = [[3,2,7],[3,7,9],[8,3,9]], capacity = 11
输出:true
提示:
你可以假设乘客会自觉遵守 “先下后上” 的良好素质
trips.length <= 1000
trips[i].length == 3
1 <= trips[i][0] <= 100
0 <= trips[i][1] < trips[i][2] <= 1000
1 <= capacity <= 100000
Program
路程长度就1000,
思路就是根据每个开始和结束重新划分trips,然后合并相等的trip。但是题中路径最长就1000,所以开数组就可以了。
1 | class Solution { |
进一步优化,最直接的想法就是模拟每个trip上下车,但是怎么记录车容量的变化是个问题。比如一个trip上车车容减小,瞎扯车容增大,而另一个trip同理,但是两个trip可能有重叠部分,如果按照trip的起始增序排列,遍历trip,就无法做到时序的上下车过程。也就是说模拟的话,需要按时序进行每个上下车过程,但每个trip的上下车时刻不是严格不重叠,有交叉,那么如何通过遍历trips模拟该过程?见代码,只需考虑上下车时刻车容量的变化就能够免去重叠的问题。
1 | class Solution { |
649. Dota2 参议院
Description
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
1.禁止一名参议员的权利:
- 参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
2.宣布胜利:
- 如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
Example
示例 1:
输入: “RD”
输出: “Radiant”
解释: 第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人
示例 2:
输入: “RDD”
输出: “Dire”
解释:
第一轮中,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利
第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止
第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利
因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利
注意:
给定字符串的长度在 [1, 10,000] 之间.
Program
模拟
1 | class Solution { |
贪心
1 | class Solution { |
134. 加油站
Description
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
如果题目有解,该答案即为唯一答案。
输入数组均为非空数组,且长度相同。
输入数组中的元素均为非负数。
Example
示例 1:
输入:
gas = [1,2,3,4,5]
cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
示例 2:
输入:
gas = [2,3,4]
cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
Program
很直观的思路就是gas[i]-cost[i],求和后若大于0则有解,否则无解。
那么如何判断出发点呢?
用res记录从i=0开始的剩余油量,最后如果res大于0则有解,否则无解。
若最后res大于0,这里讨论res折线有小于0的情况(全程大于0全都是解,然而题目说了只有唯一解,那么必出现过程中res小于0的情况),那么从过程中出现的
res最低点到最后res大于0,说明过程中的res最低点对应的下一个索引值开始到最后能够抵消res的最大负值!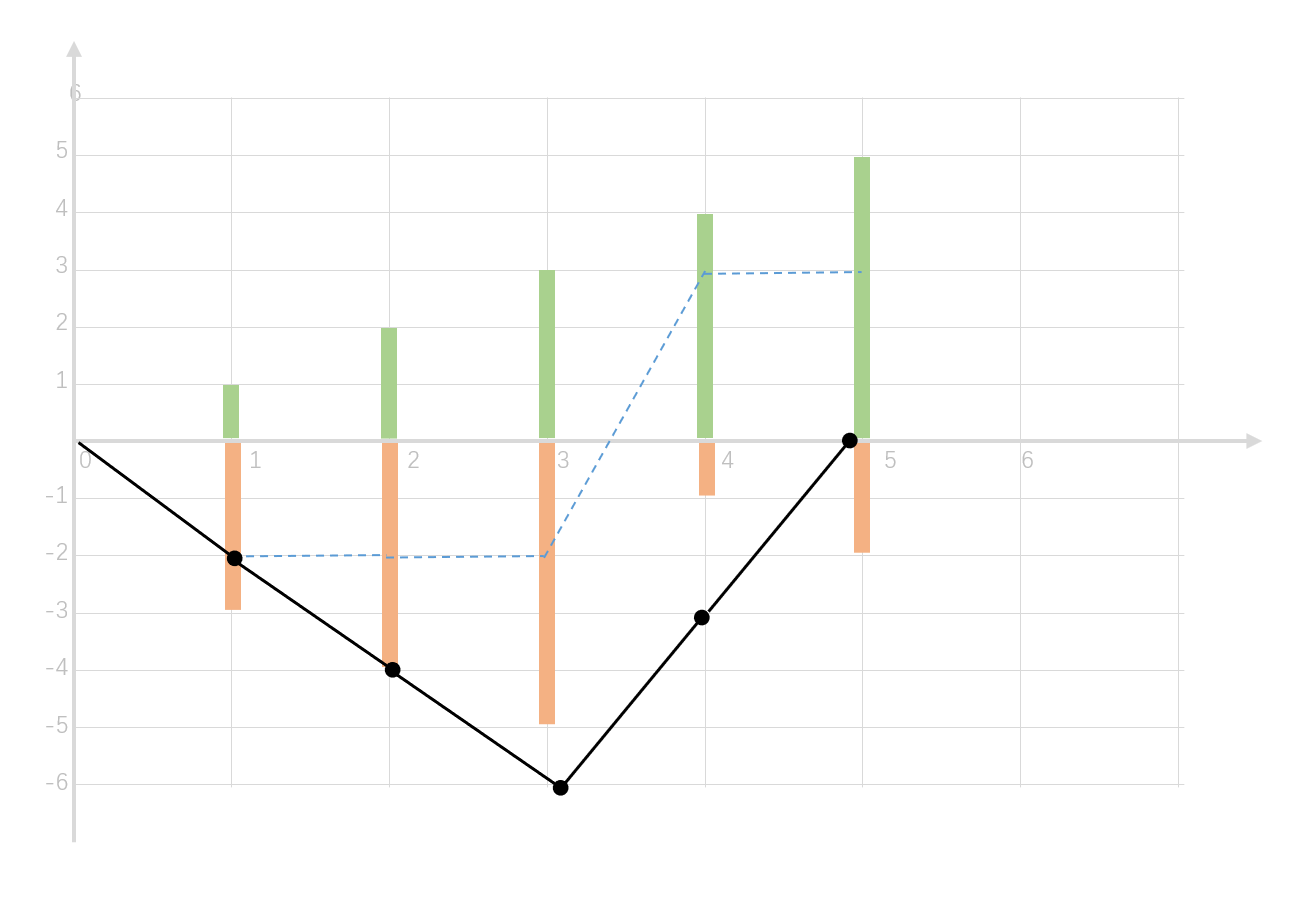
柱状图
绿色:可添加的汽油 gas[i]
橙色:消耗的汽油 cost[i]
折线图:
虚线(蓝色):当前加油站的可用值
实线(黑色):从0开始的总剩余汽油量
1 | class Solution { |
659. 分割数组为连续子序列
Description
输入一个按升序排序的整数数组(可能包含重复数字),你需要将它们分割成几个子序列,其中每个子序列至少包含三个连续整数。返回你是否能做出这样的分割?
Example
示例 1:
输入: [1,2,3,3,4,5]
输出: True
解释:
你可以分割出这样两个连续子序列 :
1, 2, 3
3, 4, 5
示例 2:
输入: [1,2,3,3,4,4,5,5]
输出: True
解释:
你可以分割出这样两个连续子序列 :
1, 2, 3, 4, 5
3, 4, 5
示例 3:
输入: [1,2,3,4,4,5]
输出: False
提示:
输入的数组长度范围为 [1, 10000]
Program
贪心
我们把 3 个或更多的连续数字称作 chain。
我们从左到右考虑每一个数字 x,如果 x 可以被添加到当前的 chain 中,我们将 x 添加到 chain 中,这一定会比创建一个新的 chain 要更好。
为什么呢?如果我们以 x 为起点新创建一个 chain ,这条新创建更短的链是可以接在之前的链上的,这可能会帮助我们避免创建一个从 x 开始的长度为 1 或者 2 的短链。
算法:
我们将每个数字的出现次数统计好,记 tails[x] 是恰好在 x 之前结束的链的数目。
现在我们逐一考虑每个数字,如果有一个链恰好在 x 之前结束,我们将 x 加入此链中。否则,如果我们可以新建立一条链就新建。
1 | class Solution { |
1111. 有效括号的嵌套深度
Description
有效括号字符串 定义:对于每个左括号,都能找到与之对应的右括号,反之亦然。详情参见题末「有效括号字符串」部分。
嵌套深度 depth 定义:即有效括号字符串嵌套的层数,depth(A) 表示有效括号字符串 A 的嵌套深度。详情参见题末「嵌套深度」部分。
给你一个「有效括号字符串」 seq,请你将其分成两个不相交的有效括号字符串,A 和 B,并使这两个字符串的深度最小。
不相交:每个 seq[i] 只能分给 A 和 B 二者中的一个,不能既属于 A 也属于 B 。
A 或 B 中的元素在原字符串中可以不连续。
A.length + B.length = seq.length
深度最小:max(depth(A), depth(B)) 的可能取值最小。
划分方案用一个长度为 seq.length 的答案数组 answer 表示,编码规则如下:
answer[i] = 0,seq[i] 分给 A 。
answer[i] = 1,seq[i] 分给 B 。
如果存在多个满足要求的答案,只需返回其中任意 一个 即可。
Example
示例 1:
输入:seq = “(()())”
输出:[0,1,1,1,1,0]
示例 2:
输入:seq = “()(())()”
输出:[0,0,0,1,1,0,1,1]
解释:本示例答案不唯一。
按此输出 A = “()()”, B = “()()”, max(depth(A), depth(B)) = 1,它们的深度最小。
像 [1,1,1,0,0,1,1,1],也是正确结果,其中 A = “()()()”, B = “()”, max(depth(A), depth(B)) = 1 。
提示:
$1 < seq.size <= 10000$
有效括号字符串:
仅由 “(“ 和 “)” 构成的字符串,对于每个左括号,都能找到与之对应的右括号,反之亦然。
下述几种情况同样属于有效括号字符串:
- 空字符串
- 连接,可以记作 AB(A 与 B 连接),其中 A 和 B 都是有效括号字符串
- 嵌套,可以记作 (A),其中 A 是有效括号字符串
嵌套深度:
类似地,我们可以定义任意有效括号字符串 s 的 嵌套深度 depth(S): - s 为空时,depth(“”) = 0
- s 为 A 与 B 连接时,depth(A + B) = max(depth(A), depth(B)),其中 A 和 B 都是有效括号字符串
- s 为嵌套情况,depth(“(“ + A + “)”) = 1 + depth(A),其中 A 是有效括号字符串
例如:””,”()()”,和 “()(()())” 都是有效括号字符串,嵌套深度分别为 0,1,2,而 “)(“ 和 “(()” 都不是有效括号字符串。
Program
思路:栈 创建一个栈,遍历seq,遇到’(‘入栈,遇到’)’弹出。在这样的规则下,’(‘入栈时栈的深度就对应着当前括号对的嵌套深度深度。将奇数深度的括号分成一组,将偶数深度的括号分成一组,分别用0和1标记即可。
例如:
括号序列 ( ( ) ( ( ) ) ( ) )
下标编号 0 1 2 3 4 5 6 7 8 9
嵌套深度 1 2 2 2 3 3 2 2 2 1
将奇数深度的分一组用0标记,将偶数深度的括号分一组用1标记。
标记结果 0 1 1 1 0 0 1 1 1 0
1 | class Solution { |
1338. 数组大小减半
Description
给你一个整数数组 arr。你可以从中选出一个整数集合,并删除这些整数在数组中的每次出现。
返回 至少 能删除数组中的一半整数的整数集合的最小大小。
Example
示例 1:
输入:arr = [3,3,3,3,5,5,5,2,2,7]
输出:2
解释:选择 {3,7} 使得结果数组为 [5,5,5,2,2]、长度为 5(原数组长度的一半)。
大小为 2 的可行集合有 {3,5},{3,2},{5,2}。
选择 {2,7} 是不可行的,它的结果数组为 [3,3,3,3,5,5,5],新数组长度大于原数组的二分之一。
示例 2:
输入:arr = [7,7,7,7,7,7]
输出:1
解释:我们只能选择集合 {7},结果数组为空。
示例 3:
输入:arr = [1,9]
输出:1
示例 4:
输入:arr = [1000,1000,3,7]
输出:1
示例 5:
输入:arr = [1,2,3,4,5,6,7,8,9,10]
输出:5
提示:
1 <= arr.length <= 10^5
arr.length 为偶数
1 <= arr[i] <= 10^5
Program
1 | class Solution { |
738. 单调递增的数字
Description
给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。)
Example
示例 1:
输入: N = 10
输出: 9
示例 2:
输入: N = 1234
输出: 1234
示例 3:
输入: N = 332
输出: 299
说明: N 是在 [0, 10^9] 范围内的一个整数。
Program
贪心算法,遍历数字每一位,当前位的数字比下一位的数字大,则将该位数字减小1,然后之后位的数字全部变为9。
例如,如果 n=432543654,我们总是可以得到至少 39999999 的答案。
第一个下降点减1,后面全变9,而返回至下降点前一个点继续,因为存在相等连续相邻的数字。
1 | class Solution { |
1353. 最多可以参加的会议数目
Description
给你一个数组 events,其中 events[i] = [startDayi, endDayi] ,表示会议 i 开始于 startDayi ,结束于 endDayi 。
你可以在满足 startDayi <= d <= endDayi 中的任意一天 d 参加会议 i 。注意,一天只能参加一个会议。
请你返回你可以参加的 最大 会议数目。
Example
示例 1:
输入:events = [[1,2],[2,3],[3,4]]
输出:3
解释:你可以参加所有的三个会议。
安排会议的一种方案如上图。
第 1 天参加第一个会议。
第 2 天参加第二个会议。
第 3 天参加第三个会议。
示例 2:
输入:events= [[1,2],[2,3],[3,4],[1,2]]
输出:4
示例 3:
输入:events = [[1,4],[4,4],[2,2],[3,4],[1,1]]
输出:4
示例 4:
输入:events = [[1,100000]]
输出:1
示例 5:
输入:events = [[1,1],[1,2],[1,3],[1,4],[1,5],[1,6],[1,7]]
输出:7
提示:
1 <= events.length <= 10^5
events[i].length == 2
1 <= events[i][0] <= events[i][1] <= 10^5
Program
贪心的思想,对于第 i 天,如果有若干的会议都可以在这一天开,那么我们肯定是让 endDay 小的会议先在这一天开才会使答案最优,因为 endDay 大的会议可选择的空间是比 endDay 小的多的,所以在满足条件的会议需要让 endDay 小的先开。
我们开两个数组和一个 setset:
in[i]:表示在第 i 天开始的会议
out[i]:表示在第 i 天有些会议结束了,注意endDay结束的会议,endDay+1才会被撤出
multiset
1 | class Solution { |
763. 划分字母区间
Description
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一个字母只会出现在其中的一个片段。返回一个表示每个字符串片段的长度的列表。
Example
示例 1:
输入: S = “ababcbacadefegdehijhklij”
输出: [9,7,8]
解释:
划分结果为 “ababcbaca”, “defegde”, “hijhklij”。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 的划分是错误的,因为划分的片段数较少。
注意:
S的长度在[1, 500]之间。
S只包含小写字母’a’到’z’。
Program
策略就是不断地选择从最左边起最小的区间。可以从第一个字母开始分析,假设第一个字母是 ‘a’,那么第一个区间一定包含最后一次出现的 ‘a’。但第一个出现的 ‘a’ 和最后一个出现的 ‘a’ 之间可能还有其他字母,这些字母会让区间变大。举个例子,在 “abccaddbeffe” 字符串中,第一个最小的区间是 “abccaddb”。
通过以上的分析,我们可以得出一个算法:对于遇到的每一个字母,去找这个字母最后一次出现的位置,用来更新当前的最小区间
很容易发现必须记录每个字母的最大区间,而最后需要合并那些区间有重叠的字母来获得最大区间,因为有重叠的两个字母对应的区间可能会更新成更大的区间。
1 | class Solution { |
767. 重构字符串
Description
给定一个字符串S,检查是否能重新排布其中的字母,使得两相邻的字符不同。
若可行,输出任意可行的结果。若不可行,返回空字符串。
Example
示例 1:
输入: S = “aab”
输出: “aba”
示例 2:
输入: S = “aaab”
输出: “”
注意:
S 只包含小写字母并且长度在[1, 500]区间内。
Program
桶排序:
1.根据每种字母出现的次数高低排序,先排次数高的字母
2.优先加入长度短的队列
1 | class Solution { |
技巧
隔位排列。
1 | class Solution { |
1217. 玩筹码
Description
数轴上放置了一些筹码,每个筹码的位置存在数组 chips 当中。
你可以对 任何筹码 执行下面两种操作之一(不限操作次数,0 次也可以):
- 将第 i 个筹码向左或者右移动 2 个单位,代价为 0。
- 将第 i 个筹码向左或者右移动 1 个单位,代价为 1。
最开始的时候,同一位置上也可能放着两个或者更多的筹码。
返回将所有筹码移动到同一位置(任意位置)上所需要的最小代价。
Example
示例 1:
输入:chips = [1,2,3]
输出:1
解释:第二个筹码移动到位置三的代价是 1,第一个筹码移动到位置三的代价是 0,总代价为 1。
示例 2:
输入:chips = [2,2,2,3,3]
输出:2
解释:第四和第五个筹码移动到位置二的代价都是 1,所以最小总代价为 2。
提示:
1 <= chips.length <= 100
1 <= chips[i] <= 10^9
Program
1 | class Solution { |
306. 累加数
Description
累加数是一个字符串,组成它的数字可以形成累加序列。
一个有效的累加序列必须至少包含 3 个数。除了最开始的两个数以外,字符串中的其他数都等于它之前两个数相加的和。
给定一个只包含数字 ‘0’-‘9’ 的字符串,编写一个算法来判断给定输入是否是累加数。
说明: 累加序列里的数不会以 0 开头,所以不会出现 1, 2, 03 或者 1, 02, 3 的情况。
Example
示例 1:
输入: “112358”
输出: true
解释: 累加序列为: 1, 1, 2, 3, 5, 8 。1 + 1 = 2, 1 + 2 = 3, 2 + 3 = 5, 3 + 5 = 8
示例 2:
输入: “199100199”
输出: true
解释: 累加序列为: 1, 99, 100, 199。1 + 99 = 100, 99 + 100 = 199
Program
i,j,k分别表示三个子串的起点,先得到前两个子串str[j-i], str[k-j],求其和的字符串str_sum:
①如果str_sum的长度大于整个字符串或str_sum与str[str_sum.length-k]不符,返回false;
②否则,如果str_sum的长度满足要求且str_sum与str[str_sum.length-k]相符,返回true;
③否则,继续递归dfs(j,k,k+str_sum.leng);
1 | class Solution { |
842. 将数组拆分成斐波那契序列
Description
给定一个数字字符串 S,比如 S = “123456579”,我们可以将它分成斐波那契式的序列 [123, 456, 579]。
形式上,斐波那契式序列是一个非负整数列表 F,且满足:
- 0 <= F[i] <= 2^31 - 1,(也就是说,每个整数都符合 32 位有符号整数类型);
- F.length >= 3;
- 对于所有的0 <= i < F.length - 2,都有 F[i] + F[i+1] = F[i+2] 成立。
- 另外,请注意,将字符串拆分成小块时,每个块的数字一定不要以零开头,除非这个块是数字 0 本身。
返回从 S 拆分出来的所有斐波那契式的序列块,如果不能拆分则返回 []。
示例 1:
输入:”123456579”
输出:[123,456,579]
示例 2:
输入: “11235813”
输出: [1,1,2,3,5,8,13]
示例 3:
输入: “112358130”
输出: []
解释: 这项任务无法完成。
示例 4:
输入:”0123”
输出:[]
解释:每个块的数字不能以零开头,因此 “01”,”2”,”3” 不是有效答案。
示例 5:
输入: “1101111”
输出: [110, 1, 111]
解释: 输出 [11,0,11,11] 也同样被接受。
提示:
1 <= S.length <= 200
字符串 S 中只含有数字。
Program
1 | class Solution { |
1 | class Solution { |
1400. 构造 K 个回文字符串
Description
给你一个字符串 s 和一个整数 k 。请你用 s 字符串中 所有字符 构造 k 个非空 回文串 。
如果你可以用 s 中所有字符构造 k 个回文字符串,那么请你返回 True ,否则返回 False 。
Example
示例 1:
输入:s = “annabelle”, k = 2
输出:true
解释:可以用 s 中所有字符构造 2 个回文字符串。
一些可行的构造方案包括:”anna” + “elble”,”anbna” + “elle”,”anellena” + “b”
示例 2:
输入:s = “leetcode”, k = 3
输出:false
解释:无法用 s 中所有字符构造 3 个回文串。
示例 3:
输入:s = “true”, k = 4
输出:true
解释:唯一可行的方案是让 s 中每个字符单独构成一个字符串。
示例 4:
输入:s = “yzyzyzyzyzyzyzy”, k = 2
输出:true
解释:你只需要将所有的 z 放在一个字符串中,所有的 y 放在另一个字符串中。那么两个字符串都是回文串。
示例 5:
输入:s = “cr”, k = 7
输出:false
解释:我们没有足够的字符去构造 7 个回文串。
提示:
1 <= s.length <= 10^5
s 中所有字符都是小写英文字母。
1 <= k <= 10^5
Program
先安排落单的字母,然后判断成对个数是否满足,特别要判断的是odd+even<k的情况,也有可能成立!
1 | class Solution { |
860. 柠檬水找零
Description
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
Example
示例 1:
输入:[5,5,5,10,20]
输出:true
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
输入:[5,5,10]
输出:true
示例 3:
输入:[10,10]
输出:false
示例 4:
输入:[5,5,10,10,20]
输出:false
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
0 <= bills.length <= 10000
bills[i] 不是 5 就是 10 或是 20
Program
1 | class Solution { |
861. 翻转矩阵后的得分
Description
有一个二维矩阵 A 其中每个元素的值为 0 或 1 。
移动是指选择任一行或列,并转换该行或列中的每一个值:将所有 0 都更改为 1,将所有 1 都更改为 0。
在做出任意次数的移动后,将该矩阵的每一行都按照二进制数来解释,矩阵的得分就是这些数字的总和。
返回尽可能高的分数。
Example
示例:
输入:[[0,0,1,1],[1,0,1,0],[1,1,0,0]]
输出:39
解释:
转换为 [[1,1,1,1],[1,0,0,1],[1,1,1,1]]
0b1111 + 0b1001 + 0b1111 = 15 + 9 + 15 = 39
提示:
1 <= A.length <= 20
1 <= A[0].length <= 20
A[i][j] 是 0 或 1
Program
贪心:高位优先翻转成1
可以发现第一列一定能且一定要全成1,而后每列判断是否需要翻转。
1 | class Solution { |
1414. 和为 K 的最少斐波那契数字数目
Description
给你数字 k ,请你返回和为 k 的斐波那契数字的最少数目,其中,每个斐波那契数字都可以被使用多次。
斐波那契数字定义为:
F1 = 1
F2 = 1
Fn = Fn-1 + Fn-2 , 其中 n > 2 。
数据保证对于给定的 k ,一定能找到可行解。
Example
示例 1:
输入:k = 7
输出:2
解释:斐波那契数字为:1,1,2,3,5,8,13,……
对于 k = 7 ,我们可以得到 2 + 5 = 7 。
示例 2:
输入:k = 10
输出:2
解释:对于 k = 10 ,我们可以得到 2 + 8 = 10 。
示例 3:
输入:k = 19
输出:3
解释:对于 k = 19 ,我们可以得到 1 + 5 + 13 = 19 。
提示:
1 <= k <= 10^9
Program
1 | class Solution { |
870. 优势洗牌
Description
给定两个大小相等的数组 A 和 B,A 相对于 B 的优势可以用满足 A[i] > B[i] 的索引 i 的数目来描述。
返回 A 的任意排列,使其相对于 B 的优势最大化。
Example
示例 1:
输入:A = [2,7,11,15], B = [1,10,4,11]
输出:[2,11,7,15]
示例 2:
输入:A = [12,24,8,32], B = [13,25,32,11]
输出:[24,32,8,12]
提示:
1 <= A.length = B.length <= 10000
0 <= A[i] <= 10^9
0 <= B[i] <= 10^9
Program
贪心的思想就是,两个数组排序,不同的是B数组需要保留原位置,然后A数组尽可能小的数与B尽可能大的数匹配,才能使A中更大的数匹配更多B中的元素。
1 | class Solution { |
1386. 安排电影院座位
Description
如上图所示,电影院的观影厅中有 n 行座位,行编号从 1 到 n ,且每一行内总共有 10 个座位,列编号从 1 到 10 。
给你数组 reservedSeats ,包含所有已经被预约了的座位。比如说,researvedSeats[i]=[3,8] ,它表示第 3 行第 8 个座位被预约了。
请你返回 最多能安排多少个 4 人家庭 。4 人家庭要占据 同一行内连续 的 4 个座位。隔着过道的座位(比方说 [3,3] 和 [3,4])不是连续的座位,但是如果你可以将 4 人家庭拆成过道两边各坐 2 人,这样子是允许的。
Example
示例 1:
输入:n = 3, reservedSeats = [[1,2],[1,3],[1,8],[2,6],[3,1],[3,10]]
输出:4
解释:上图所示是最优的安排方案,总共可以安排 4 个家庭。蓝色的叉表示被预约的座位,橙色的连续座位表示一个 4 人家庭。
示例 2:
输入:n = 2, reservedSeats = [[2,1],[1,8],[2,6]]
输出:2
示例 3:
输入:n = 4, reservedSeats = [[4,3],[1,4],[4,6],[1,7]]
输出:4
提示:
1 | 1 <= n <= 10^9 |
Program
贪心:n的范围决定了不能开数组,因为绝对超时。那么看reservedSeats长度不超过$10^4$,所以按照行号对reservedSeats排序,left,mid,right记录每行三个满足题意的可能位置,每次换行就可以开始计算上一行的满足题意的方案数,注意新行与旧行不相邻,也就是跳行,那么中间的几行全部加2;其次最后一个计算的行需要下一次计算该行方案数,记得补上判断,最后就是剩余行数的问题了。
1 | class Solution { |
1403. 非递增顺序的最小子序列
Description
给你一个数组 nums,请你从中抽取一个子序列,满足该子序列的元素之和 严格 大于未包含在该子序列中的各元素之和。
如果存在多个解决方案,只需返回 长度最小 的子序列。如果仍然有多个解决方案,则返回 元素之和最大 的子序列。
与子数组不同的地方在于,「数组的子序列」不强调元素在原数组中的连续性,也就是说,它可以通过从数组中分离一些(也可能不分离)元素得到。
注意,题目数据保证满足所有约束条件的解决方案是 唯一 的。同时,返回的答案应当按 非递增顺序 排列。
Example
示例 1:
输入:nums = [4,3,10,9,8]
输出:[10,9]
解释:子序列 [10,9] 和 [10,8] 是最小的、满足元素之和大于其他各元素之和的子序列。但是 [10,9] 的元素之和最大。
示例 2:
输入:nums = [4,4,7,6,7]
输出:[7,7,6]
解释:子序列 [7,7] 的和为 14 ,不严格大于剩下的其他元素之和(14 = 4 + 4 + 6)。因此,[7,6,7] 是满足题意的最小子序列。注意,元素按非递增顺序返回。
示例 3:
输入:nums = [6]
输出:[6]
提示:
1 <= nums.length <= 500
1 <= nums[i] <= 100
Program
1 | class Solution { |
874. 模拟行走机器人
Description
机器人在一个无限大小的网格上行走,从点 (0, 0) 处开始出发,面向北方。该机器人可以接收以下三种类型的命令:
-2:向左转 90 度
-1:向右转 90 度
1 <= x <= 9:向前移动 x 个单位长度
在网格上有一些格子被视为障碍物。
第 i 个障碍物位于网格点 (obstacles[i][0], obstacles[i][1])
机器人无法走到障碍物上,它将会停留在障碍物的前一个网格方块上,但仍然可以继续该路线的其余部分。
返回从原点到机器人的最大欧式距离的平方。
Example
示例 1:
输入: commands = [4,-1,3], obstacles = []
输出: 25
解释: 机器人将会到达 (3, 4)
示例 2:
输入: commands = [4,-1,4,-2,4], obstacles = [[2,4]]
输出: 65
解释: 机器人在左转走到 (1, 8) 之前将被困在 (1, 4) 处
提示:
0 <= commands.length <= 10000
0 <= obstacles.length <= 10000
-30000 <= obstacle[i][0] <= 30000
-30000 <= obstacle[i][1] <= 30000
答案保证小于 2 ^ 31
Program
1 | class Solution { |
881. 救生艇
Description
第 i 个人的体重为 people[i],每艘船可以承载的最大重量为 limit。
每艘船最多可同时载两人,但条件是这些人的重量之和最多为 limit。
返回载到每一个人所需的最小船数。(保证每个人都能被船载)。
Example
示例 1:
输入:people = [1,2], limit = 3
输出:1
解释:1 艘船载 (1, 2)
示例 2:
输入:people = [3,2,2,1], limit = 3
输出:3
解释:3 艘船分别载 (1, 2), (2) 和 (3)
示例 3:
输入:people = [3,5,3,4], limit = 5
输出:4
解释:4 艘船分别载 (3), (3), (4), (5)
提示:
1 <= people.length <= 50000
1 <= people[i] <= limit <= 30000
Program
贪心:一般思路,(最)较重的要与尽可能大的组合,然而这样做代码难写,反而换个思路,最轻的要与尽可能大的组合一个道理,那么最重和最小的组合,如果满足题意就一艘船,否则最重的单独一艘船。
1 | class Solution { |
1405. 最长快乐字符串
Description
如果字符串中不含有任何 ‘aaa’,’bbb’ 或 ‘ccc’ 这样的字符串作为子串,那么该字符串就是一个「快乐字符串」。
给你三个整数 a,b ,c,请你返回 任意一个 满足下列全部条件的字符串 s:
s 是一个尽可能长的快乐字符串。
s 中 最多 有a 个字母 ‘a’、b 个字母 ‘b’、c 个字母 ‘c’ 。
s 中只含有 ‘a’、’b’ 、’c’ 三种字母。
如果不存在这样的字符串 s ,请返回一个空字符串 “”。
Example
示例 1:
输入:a = 1, b = 1, c = 7
输出:”ccaccbcc”
解释:”ccbccacc” 也是一种正确答案。
示例 2:
输入:a = 2, b = 2, c = 1
输出:”aabbc”
示例 3:
输入:a = 7, b = 1, c = 0
输出:”aabaa”
解释:这是该测试用例的唯一正确答案。
提示:
0 <= a, b, c <= 100
a + b + c > 0
Program
贪心:一个个字符排列(两个两个排是错的),优先排列次数多的,如果当前次数最多的字符与前两个以排字符相同,则排列次多的字符。
1 | class Solution { |
1221. 分割平衡字符串
Description
在一个「平衡字符串」中,’L’ 和 ‘R’ 字符的数量是相同的。
给出一个平衡字符串 s,请你将它分割成尽可能多的平衡字符串。
返回可以通过分割得到的平衡字符串的最大数量。
Example
示例 1:
输入:s = “RLRRLLRLRL”
输出:4
解释:s 可以分割为 “RL”, “RRLL”, “RL”, “RL”, 每个子字符串中都包含相同数量的 ‘L’ 和 ‘R’。
示例 2:
输入:s = “RLLLLRRRLR”
输出:3
解释:s 可以分割为 “RL”, “LLLRRR”, “LR”, 每个子字符串中都包含相同数量的 ‘L’ 和 ‘R’。
示例 3:
输入:s = “LLLLRRRR”
输出:1
解释:s 只能保持原样 “LLLLRRRR”.
提示:
1 <= s.length <= 1000
s[i] = ‘L’ 或 ‘R’
分割得到的每个字符串都必须是平衡字符串。
Program
1 | class Solution { |
402. 移掉K位数字
Description
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小。
注意:
num 的长度小于 10002 且 ≥ k。
num 不会包含任何前导零。
Example
示例 1 :
输入: num = “1432219”, k = 3
输出: “1219”
解释: 移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219。
示例 2 :
输入: num = “10200”, k = 1
输出: “200”
解释: 移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入: num = “10”, k = 2
输出: “0”
解释: 从原数字移除所有的数字,剩余为空就是0。
Program
贪心:移出k个数字,也就是保存resCount=n-k个数字,使其最小。那么每次选择结果字符串的第i个数字的时候,从除了末尾resCount-1个数字外,选择当前最小的数字作为结果的第i个数字即可。
例如:
1432219, k=3
①保留后n-k-1=3位,从下标0开始,1432中选择最小的数字1,原字符串下标0;
②保留后n-k-2=2位,从下标0+1开始,即4322中选择最小的数字2,原字符串下标3;
③保留后n-k-3=1位,从下标3+1开始,即21中选择最小的数字1,原字符串下标5;
④保留后n-k-4=0位,从下标5+1开始,即9中选择最小的数字9,原字符串下标6,结束,res字符串长度满足要求n-k。
时间复杂度:$O((k+1)(n-k))$,当k=(n-1)/2时,时间复杂度最高,约$2.5×10^7$
1 | class Solution { |
算法:
上述的规则使得我们通过一个接一个的删除数字,逐步的接近最优解。
这个问题可以用贪心算法来解决。上述规则阐明了我们如何接近最终答案的基本逻辑。一旦我们从序列中删除一个数字,剩下的数字就形成了一个新的问题,我们可以继续使用这个规则。
我们会注意到,在某些情况下,规则对任意数字都不适用,即单调递增序列。在这种情况下,我们只需要删除末尾的数字来获得最小数。
我们可以利用栈来实现上述算法,存储当前迭代数字之前的数字。
- 对于每个数字,如果该数字小于栈顶部,即该数字的左邻居,则弹出堆栈,即删除左邻居。否则,我们把数字推到栈上。
- 我们重复上述步骤(1),直到任何条件不再适用,例如堆栈为空(不再保留数字)。或者我们已经删除了 k 位数字。
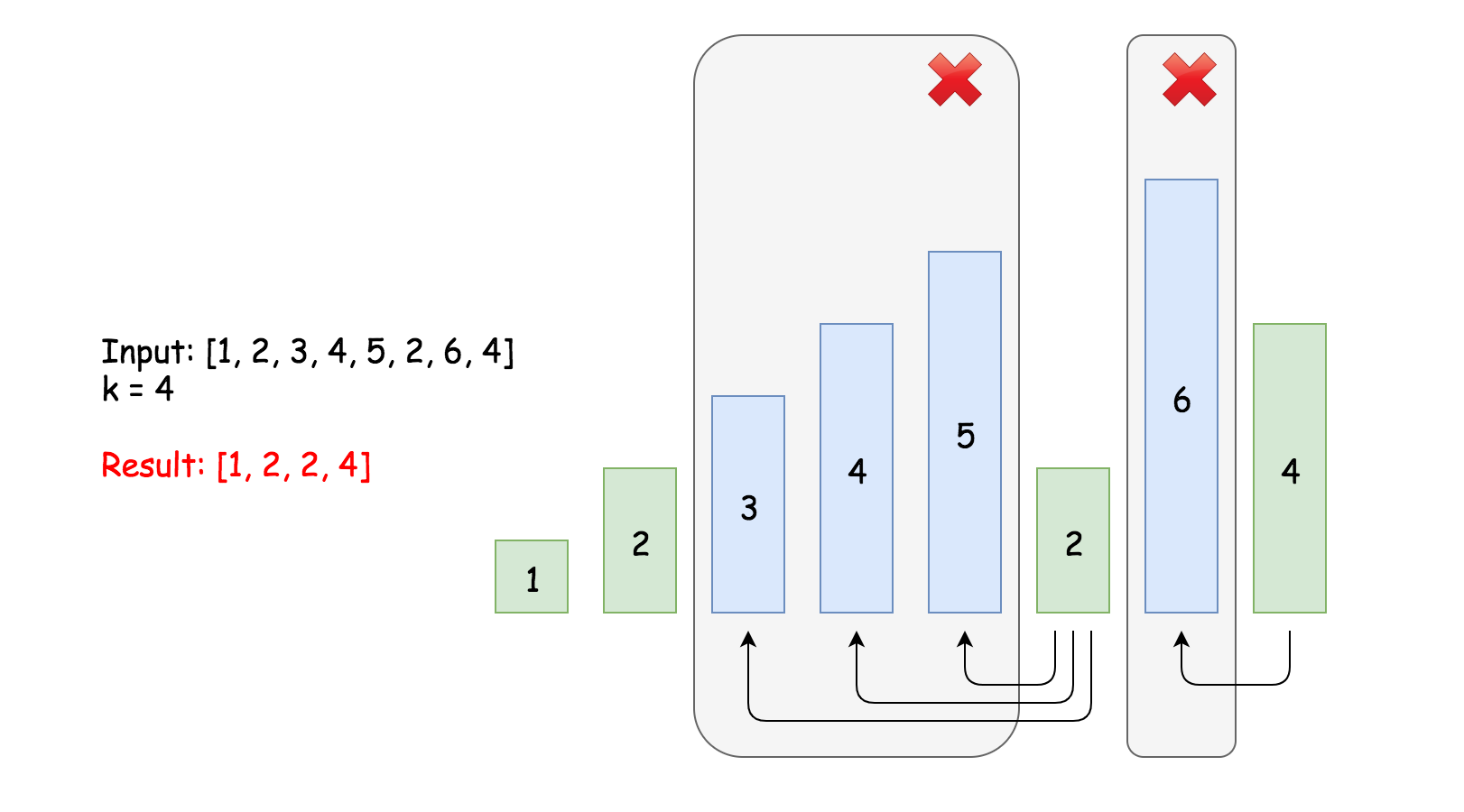
我们在上图中演示了该算法的工作原理。给定输入序列 [1,2,3,4,5,2,6,4] 和 k=4,规则在 5 触发。删除数字 5 后,规则将在数字 4 处再次触发,直到数字 3。然后,在数字 6 处,规则也被触发。
1 | class Solution { |
406. 根据身高重建队列
Description
假设有打乱顺序的一群人站成一个队列。 每个人由一个整数对(h, k)表示,其中h是这个人的身高,k是排在这个人前面且身高大于或等于h的人数。 编写一个算法来重建这个队列。
注意:
总人数少于1100人。
Example
示例
输入:
[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]
输出:
[[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]]
Program
贪心:优先安排高的而非矮的,因为要满足无后效性,即安排较高的,之前已排列的都是身高大于等于当前的,确定了插入位置,对其后面的不产生影响。可以试试优先安排矮的,会发现每次插入教高的时候,插入位置后面如果还有比当前更矮的就得重新计算,即先前排列相对位置。其次,频繁插入用链表更合适,数组需要移动元素不方便。
1 | class Solution { |
1 | class Solution { |
910. 最小差值 II
Description
给定一个整数数组 A,对于每个整数 A[i],我们可以选择 x = -K 或是 x = K,并将 x 加到 A[i] 中。
在此过程之后,我们得到一些数组 B。
返回 B 的最大值和 B 的最小值之间可能存在的最小差值。
Example
示例 1:
输入:A = [1], K = 0
输出:0
解释:B = [1]
示例 2:
输入:A = [0,10], K = 2
输出:6
解释:B = [2,8]
示例 3:
输入:A = [1,3,6], K = 3
输出:3
解释:B = [4,6,3]
提示:
1 <= A.length <= 10000
0 <= A[i] <= 10000
0 <= K <= 10000
Program
当我们选择在 i 这一点“切一刀”的时候,也就是 A[0] ~ A[i] 的元素都上移,A[i + 1] ~ A[A.length - 1] 的元素都下移。
此时 B 点的值是 A[i] + K,D 点的值是 A[A.length - 1] - K。
新数组的最大值要么是 B 点要么是 D 点,也就是说新数组的最大值是 $Max(A[i] + K, A[A.length - 1] - K)$。
同样道理,此时 A 点的值是 A[0] + K,C 点的值是 A[i + 1] - K。
新数组的最小值要么是 A 点要么是 C 点,也就是说新数组的最小值是 $Min(A[0] + K, A[i + 1] - K)$。
因此,题目需要的“新数组的最大值和最小值的差值”,就是 $Max(A[i] + K, A[A.length - 1] - K) - Min(A[0] + K, A[i + 1] - K)$。
K 的值是题目给出的固定值,因此如果我们想让上面这个算式的结果尽可能小的话,就要靠改变 i 的值,也就是思考究竟要在哪里“切这一刀”。因此我们挨个遍历一下所有可能的 i 的值,然后取上面算式的最小值即可。
1 | class Solution { |
921. 使括号有效的最少添加
Description
给定一个由’(‘ 和 ‘)’括号组成的字符串 S,我们需要添加最少的括号( ‘(‘ 或是 ‘)’,可以在任何位置),以使得到的括号字符串有效。
从形式上讲,只有满足下面几点之一,括号字符串才是有效的:它是一个空字符串,或者它可以被写成 AB (A 与 B 连接), 其中 A 和 B 都是有效字符串,或者
它可以被写作 (A),其中 A 是有效字符串。给定一个括号字符串,返回为使结果字符串有效而必须添加的最少括号数。
Example
示例 1:
输入:”())”
输出:1
示例 2:
输入:”(((“
输出:3
示例 3:
输入:”()”
输出:0
示例 4:
输入:”()))((“
输出:4
提示:
S.length <= 1000
S 只包含 ‘(‘ 和 ‘)’ 字符。
Program
1 | class Solution { |
435. 无重叠区间
Description
给定个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意:
- 可以认为区间的终点总是大于它的起点。
- 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
Example
示例 1:
输入: [ [1,2], [2,3], [3,4], [1,3] ]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
Program
正确的思路其实很简单,可以分为以下三步:
- 从区间集合 intvs 中选择一个区间 x,这个 x 是在当前所有区间中结束最早的(end 最小)。
- 把所有与 x 区间相交的区间从区间集合 intvs 中删除。
- 重复步骤 1 和 2,直到 intvs 为空为止。之前选出的那些 x 就是最大不相交子集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if(intervals.size()==0) return 0;
sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){
return a[1]<b[1];
});
vector<int> pre=intervals[0];
int ans=1;
for(int i=1;i<intervals.size();i++){
vector<int> cur=intervals[i];
if(cur[0]>=pre[1]){
ans++;
pre=cur;
}
}
return intervals.size()-ans;
}
};452. 用最少数量的箭引爆气球
Description
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以y坐标并不重要,因此只要知道开始和结束的x坐标就足够了。开始坐标总是小于结束坐标。平面内最多存在104个气球。
一支弓箭可以沿着x轴从不同点完全垂直地射出。在坐标x处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
Example
输入:
[[10,16], [2,8], [1,6], [7,12]]
输出:
2
解释:
对于该样例,我们可以在x = 6(射爆[2,8],[1,6]两个气球)和 x = 11(射爆另外两个气球)。
Program
贪心:无重叠区间个数!!
1 | class Solution { |
1433. 检查一个字符串是否可以打破另一个字符串
Description
给你两个字符串 s1 和 s2 ,它们长度相等,请你检查是否存在一个 s1 的排列可以打破 s2 的一个排列,或者是否存在一个 s2 的排列可以打破 s1 的一个排列。
字符串 x 可以打破字符串 y (两者长度都为 n )需满足对于所有 i(在 0 到 n - 1 之间)都有 x[i] >= y[i](字典序意义下的顺序)。
Example
示例 1:
输入:s1 = “abc”, s2 = “xya”
输出:true
解释:”ayx” 是 s2=”xya” 的一个排列,”abc” 是字符串 s1=”abc” 的一个排列,且 “ayx” 可以打破 “abc” 。
示例 2:
输入:s1 = “abe”, s2 = “acd”
输出:false
解释:s1=”abe” 的所有排列包括:”abe”,”aeb”,”bae”,”bea”,”eab” 和 “eba” ,s2=”acd” 的所有排列包括:”acd”,”adc”,”cad”,”cda”,”dac” 和 “dca”。然而没有任何 s1 的排列可以打破 s2 的排列。也没有 s2 的排列能打破 s1 的排列。
示例 3:
输入:s1 = “leetcodee”, s2 = “interview”
输出:true
提示:
s1.length == n
s2.length == n
1 <= n <= 10^5
所有字符串都只包含小写英文字母。
Program
1 | class Solution { |
cnt数组合理的情况应该是这样的(不考虑0):
①–++
②++–
③-+-+
④+-+-
不可能的是:+–+/-++-,即sum在整个过程中不能变号!
1 | class Solution { |
1 | class Solution { |
944. 删列造序
Description
给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
你需要选出一组要删掉的列 D,对 A 执行删除操作,使 A 中剩余的每一列都是 非降序 排列的,然后请你返回 D.length 的最小可能值。
删除 操作的定义是:选出一组要删掉的列,删去 A 中对应列中的所有字符,形式上,第 n 列为 [A[0][n], A[1][n], …, A[A.length-1][n]])。
比如,有 A = [“abcdef”, “uvwxyz”],
要删掉的列为 {0, 2, 3},删除后 A 为[“bef”, “vyz”], A 的列分别为[“b”,”v”], [“e”,”y”], [“f”,”z”]。
Example
示例 1:
输入:[“cba”, “daf”, “ghi”]
输出:1
解释:
当选择 D = {1},删除后 A 的列为:[“c”,”d”,”g”] 和 [“a”,”f”,”i”],均为非降序排列。
若选择 D = {},那么 A 的列 [“b”,”a”,”h”] 就不是非降序排列了。
示例 2:
输入:[“a”, “b”]
输出:0
解释:D = {}
示例 3:
输入:[“zyx”, “wvu”, “tsr”]
输出:3
解释:D = {0, 1, 2}
提示:
1 <= A.length <= 100
1 <= A[i].length <= 1000
Program
1 | class Solution { |
1247. 交换字符使得字符串相同
Description
有两个长度相同的字符串 s1 和 s2,且它们其中 只含有 字符 “x” 和 “y”,你需要通过「交换字符」的方式使这两个字符串相同。
每次「交换字符」的时候,你都可以在两个字符串中各选一个字符进行交换。
交换只能发生在两个不同的字符串之间,绝对不能发生在同一个字符串内部。也就是说,我们可以交换 s1[i] 和 s2[j],但不能交换 s1[i] 和 s1[j]。
最后,请你返回使 s1 和 s2 相同的最小交换次数,如果没有方法能够使得这两个字符串相同,则返回 -1 。
Example
示例 1:
输入:s1 = “xx”, s2 = “yy”
输出:1
解释:
交换 s1[0] 和 s2[1],得到 s1 = “yx”,s2 = “yx”。
示例 2:
输入:s1 = “xy”, s2 = “yx”
输出:2
解释:
交换 s1[0] 和 s2[0],得到 s1 = “yy”,s2 = “xx” 。
交换 s1[0] 和 s2[1],得到 s1 = “xy”,s2 = “xy” 。
注意,你不能交换 s1[0] 和 s1[1] 使得 s1 变成 “yx”,因为我们只能交换属于两个不同字符串的字符。
示例 3:
输入:s1 = “xx”, s2 = “xy”
输出:-1
示例 4:
输入:s1 = “xxyyxyxyxx”, s2 = “xyyxyxxxyx”
输出:4
提示:
1 <= s1.length, s2.length <= 1000
s1, s2 只包含 ‘x’ 或 ‘y’。
Program
解题思路
1.拿到这个题第一念头是把字符串扫一遍,把差异项识别出来;稍微纸上画画就不难发现下面的规律:
- ‘xx’与’yy’、’yy’与’xx’,他们之间仅需要1步即可完成满足题面的交换
- ‘xy’与’yx’、’yx’与’xy’,他们之间需要2步即可完成满足题面的交换
2.假设我们把1中两种情况分开记录,当遇到s1[i] = ‘x’,s2[i] = ‘y’,我们记录到xyCnt中;当遇到s1[i] = ‘y’,s2[i] = ‘x’,我们记录到yxCnt中,那么我们只需要统计xyCnt和yxCnt的个数即可完成计算。
3.具体计算的规则:
- 如果xyCnt+yxCnt是个奇数,那肯定是要返回-1的,因为肯定最右有两个字符是无法通过对调匹配的;
- 排除上面的条件后,xyCnt+yxCnt肯定是个偶数,那么又分两种情况,即“奇数+奇数”和“偶数+偶数”;
- 基于上面的分析,可以发现每2个xyCnt或yxCnt对应一次移动,1个xyCnt与1个yxCnt对应两次移动,详见代码中注释下面那段代码;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
int minimumSwap(string s1, string s2) {
int xyCnt=0, yxCnt=0;
int ans=0;
for(int i=0;i<s1.length();i++){
if(s1[i]=='x'&&s2[i]=='y') xyCnt++;
if(s1[i]=='y'&&s2[i]=='x') yxCnt++;
}
if((xyCnt+yxCnt)%2!=0) return -1;
ans+=xyCnt/2;
ans+=yxCnt/2;
xyCnt%=2;
yxCnt%=2;
if(xyCnt!=0) ans+=2;
return ans;
}
};948. 令牌放置
Description
你的初始能量为 P,初始分数为 0,只有一包令牌。
令牌的值为 token[i],每个令牌最多只能使用一次,可能的两种使用方法如下:
如果你至少有 token[i] 点能量,可以将令牌置为正面朝上,失去 token[i] 点能量,并得到 1 分。
如果我们至少有 1 分,可以将令牌置为反面朝上,获得 token[i] 点能量,并失去 1 分。
在使用任意数量的令牌后,返回我们可以得到的最大分数。
Example
示例 1:
输入:tokens = [100], P = 50
输出:0
示例 2:
输入:tokens = [100,200], P = 150
输出:1
示例 3:
输入:tokens = [100,200,300,400], P = 200
输出:2
提示:
tokens.length <= 1000
0 <= tokens[i] < 10000
0 <= P < 10000
Program
贪心:从小到大尽可能获取分数,否则从大到小尽可能获取能量!
1 | class Solution { |
455. 分发饼干
Description
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i ,都有一个胃口值 gi ,这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j ,都有一个尺寸 sj 。如果 sj >= gi ,我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
注意:
你可以假设胃口值为正。
一个小朋友最多只能拥有一块饼干。
Example
示例 1:
输入: [1,2,3], [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: [1,2], [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
Program
1 | class Solution { |
955. 删列造序 II
Description
给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
选取一个删除索引序列,对于 A 中的每个字符串,删除对应每个索引处的字符。
比如,有 A = [“abcdef”, “uvwxyz”],删除索引序列 {0, 2, 3},删除后 A 为[“bef”, “vyz”]。
假设,我们选择了一组删除索引 D,那么在执行删除操作之后,最终得到的数组的元素是按 字典序(A[0] <= A[1] <= A[2] … <= A[A.length - 1])排列的,然后请你返回 D.length 的最小可能值。
Example
示例 1:
输入:[“ca”,”bb”,”ac”]
输出:1
解释:
删除第一列后,A = [“a”, “b”, “c”]。
现在 A 中元素是按字典排列的 (即,A[0] <= A[1] <= A[2])。
我们至少需要进行 1 次删除,因为最初 A 不是按字典序排列的,所以答案是 1。
示例 2:
输入:[“xc”,”yb”,”za”]
输出:0
解释:
A 的列已经是按字典序排列了,所以我们不需要删除任何东西。
注意 A 的行不需要按字典序排列。
也就是说,A[0][0] <= A[0][1] <= … 不一定成立。
示例 3:
输入:[“zyx”,”wvu”,”tsr”]
输出:3
解释:
我们必须删掉每一列。
提示:
1 <= A.length <= 100
1 <= A[i].length <= 100
Program
贪心:很容易分析出,两个相邻子串靠前一个字符如果满足要求,那么有两种情况:
- ①两字符相等,则必须继续比较两字符串后面的字符是否满足要求;
- ②前一个字符串的字符比后一个严格小,则不用继续比较后面的字符了!
问题在于如何代码表示这种情况。
开一个表示各行字符串是否继续比较的数组,先按列判断每行是否升序,如果升序,再确定哪些行可以不用再比较后面的字符。
例如:
abx
agz
bgc
bfc
①比较第一列,满足升序,再确定哪些行不用再次比对后续字符,可以发现第二行和第三行不用继续比对了!记录vis[2]=false即可
②比较第二列,不满足升序,继续下一列比较;
③比较第三列,满足升序,现需要继续比较12,34行,确定不用再次对比行,发现第12行不用继续比对了!记录vis[1]=false即可
当所有行不用比较或所有列对比完了结束。
1 | class Solution { |
984. 不含 AAA 或 BBB 的字符串
Description
给定两个整数 A 和 B,返回任意字符串 S,要求满足:
- S 的长度为 A + B,且正好包含 A 个 ‘a’ 字母与 B 个 ‘b’ 字母;
- 子串 ‘aaa’ 没有出现在 S 中;
- 子串 ‘bbb’ 没有出现在 S 中。
Example
示例 1:
输入:A = 1, B = 2
输出:”abb”
解释:”abb”, “bab” 和 “bba” 都是正确答案。
示例 2:
输入:A = 4, B = 1
输出:”aabaa”
提示:
0 <= A <= 100
0 <= B <= 100
对于给定的 A 和 B,保证存在满足要求的 S。
Program
1 | class Solution { |
991. 坏了的计算器
Description
在显示着数字的坏计算器上,我们可以执行以下两种操作:
- 双倍(Double):将显示屏上的数字乘 2;
- 递减(Decrement):将显示屏上的数字减 1 。
最初,计算器显示数字 X。
返回显示数字 Y 所需的最小操作数。
Example
示例 1:
输入:X = 2, Y = 3
输出:2
解释:先进行双倍运算,然后再进行递减运算 {2 -> 4 -> 3}.
示例 2:
输入:X = 5, Y = 8
输出:2
解释:先递减,再双倍 {5 -> 4 -> 8}.
示例 3:
输入:X = 3, Y = 10
输出:3
解释:先双倍,然后递减,再双倍 {3 -> 6 -> 5 -> 10}.
示例 4:
输入:X = 1024, Y = 1
输出:1023
解释:执行递减运算 1023 次
提示:
1 <= X <= 10^9
1 <= Y <= 10^9
Program
思路
除了对 X 执行乘 2 或 减 1 操作之外,我们也可以对 Y 执行除 2(当 Y 是偶数时)或者加 1 操作。
这样做的动机是我们可以总是贪心地执行除 2 操作:
- 当 Y 是偶数,如果先执行 2 次加法操作,再执行 1 次除法操作,我们可以通过先执行 1 次除法操作,再执行 1 次加法操作以使用更少的操作次数得到相同的结果 [(Y+2) / 2 vs Y/2 + 1]。
- 当 Y 是奇数,如果先执行 3 次加法操作,再执行 1 次除法操作,我们可以将其替代为顺次执行加法、除法、加法操作以使用更少的操作次数得到相同的结果 [(Y+3) / 2 vs (Y+1) / 2 + 1]。
算法
当 Y 大于 X 时,如果它是奇数,我们执行加法操作,否则执行除法操作。之后,我们需要执行 X - Y 次加法操作以得到 X。
1 | class Solution { |
1276. 不浪费原料的汉堡制作方案
Description
圣诞活动预热开始啦,汉堡店推出了全新的汉堡套餐。为了避免浪费原料,请你帮他们制定合适的制作计划。
给你两个整数 tomatoSlices 和 cheeseSlices,分别表示番茄片和奶酪片的数目。不同汉堡的原料搭配如下:
- 巨无霸汉堡:4 片番茄和 1 片奶酪
- 小皇堡:2 片番茄和 1 片奶酪
请你以 [total_jumbo, total_small]([巨无霸汉堡总数,小皇堡总数])的格式返回恰当的制作方案,使得剩下的番茄片 tomatoSlices 和奶酪片 cheeseSlices 的数量都是 0。
如果无法使剩下的番茄片 tomatoSlices 和奶酪片 cheeseSlices 的数量为 0,就请返回 []。
Example
示例 1:
输入:tomatoSlices = 16, cheeseSlices = 7
输出:[1,6]
解释:制作 1 个巨无霸汉堡和 6 个小皇堡需要 41 + 26 = 16 片番茄和 1 + 6 = 7 片奶酪。不会剩下原料。
示例 2:
输入:tomatoSlices = 17, cheeseSlices = 4
输出:[]
解释:只制作小皇堡和巨无霸汉堡无法用光全部原料。
示例 3:
输入:tomatoSlices = 4, cheeseSlices = 17
输出:[]
解释:制作 1 个巨无霸汉堡会剩下 16 片奶酪,制作 2 个小皇堡会剩下 15 片奶酪。
示例 4:
输入:tomatoSlices = 0, cheeseSlices = 0
输出:[0,0]
示例 5:
输入:tomatoSlices = 2, cheeseSlices = 1
输出:[0,1]
提示:
0 <= tomatoSlices <= 10^7
0 <= cheeseSlices <= 10^7
Program
1 | class Solution { |
1253. 重构 2 行二进制矩阵
Description
给你一个 2 行 n 列的二进制数组:
- 矩阵是一个二进制矩阵,这意味着矩阵中的每个元素不是 0 就是 1。
- 第 0 行的元素之和为 upper。
- 第 1 行的元素之和为 lower。
- 第 i 列(从 0 开始编号)的元素之和为 colsum[i],colsum 是一个长度为 n 的整数数组。
你需要利用 upper,lower 和 colsum 来重构这个矩阵,并以二维整数数组的形式返回它。
如果有多个不同的答案,那么任意一个都可以通过本题。
如果不存在符合要求的答案,就请返回一个空的二维数组。
Example
示例 1:
输入:upper = 2, lower = 1, colsum = [1,1,1]
输出:[[1,1,0],[0,0,1]]
解释:[[1,0,1],[0,1,0]] 和 [[0,1,1],[1,0,0]] 也是正确答案。
示例 2:
输入:upper = 2, lower = 3, colsum = [2,2,1,1]
输出:[]
示例 3:
输入:upper = 5, lower = 5, colsum = [2,1,2,0,1,0,1,2,0,1]
输出:[[1,1,1,0,1,0,0,1,0,0],[1,0,1,0,0,0,1,1,0,1]]
提示:
1 <= colsum.length <= 10^5
0 <= upper, lower <= colsum.length
0 <= colsum[i] <= 2
Program
先安排colsum[i]=2的位置,而后安排colsum[i]=1的位置。
1 | class Solution { |
1005. K 次取反后最大化的数组和
Description
给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。)
以这种方式修改数组后,返回数组可能的最大和。
Example
示例 1:
输入:A = [4,2,3], K = 1
输出:5
解释:选择索引 (1,) ,然后 A 变为 [4,-2,3]。
示例 2:
输入:A = [3,-1,0,2], K = 3
输出:6
解释:选择索引 (1, 2, 2) ,然后 A 变为 [3,1,0,2]。
示例 3:
输入:A = [2,-3,-1,5,-4], K = 2
输出:13
解释:选择索引 (1, 4) ,然后 A 变为 [2,3,-1,5,4]。
提示:
1 <= A.length <= 10000
1 <= K <= 10000
-100 <= A[i] <= 100
Program
设负数个数为nF,零个数为nZ:
①nF==0,选择最小值操作K-nF次;
②nF<K,且nZ=0,选择最小的nF个负数进行操作,选择绝对值最小的数进行剩余K-nF次操作;
③nF<K,且nZ>0,选择最小的nF个负数进行操作,对0进行K-nF操作,数组全正数;
③nF=K,选择最小的nF个负数进行操作,数组全正数;
④nF>K,选择最小的nF个负数进行操作。
综上:只需要对数组从小到大排序,对前min(nF,K)进行操作,判断数组中零的个数,以及记录绝对值最小的位置。
判断K-nF大小,若K-nF>0且nZ!=0就要对绝对值最小的值进行剩余K-nF次操作。
1 | class Solution { |
537. 复数乘法
Description
给定两个表示复数的字符串。
返回表示它们乘积的字符串。注意,根据定义 i2 = -1 。
Example
示例 1:
输入: “1+1i”, “1+1i”
输出: “0+2i”
解释: (1 + i) * (1 + i) = 1 + i2 + 2 * i = 2i ,你需要将它转换为 0+2i 的形式。
示例 2:
输入: “1+-1i”, “1+-1i”
输出: “0+-2i”
解释: (1 - i) * (1 - i) = 1 + i2 - 2 * i = -2i ,你需要将它转换为 0+-2i 的形式。
注意:
输入字符串不包含额外的空格。
输入字符串将以 a+bi 的形式给出,其中整数 a 和 b 的范围均在 [-100, 100] 之间。输出也应当符合这种形式。
Program
1 | class Solution { |
1 | class Solution { |
1154. 一年中的第几天
Description
给你一个按 YYYY-MM-DD 格式表示日期的字符串 date,请你计算并返回该日期是当年的第几天。
通常情况下,我们认为 1 月 1 日是每年的第 1 天,1 月 2 日是每年的第 2 天,依此类推。每个月的天数与现行公元纪年法(格里高利历)一致。
Example
示例 1:
输入:date = “2019-01-09”
输出:9
示例 2:
输入:date = “2019-02-10”
输出:41
示例 3:
输入:date = “2003-03-01”
输出:60
示例 4:
输入:date = “2004-03-01”
输出:61
提示:
date.length == 10
date[4] == date[7] == ‘-‘,其他的 date[i] 都是数字。
date 表示的范围从 1900 年 1 月 1 日至 2019 年 12 月 31 日。
Program
1 | class Solution { |
976. 三角形的最大周长
Description
给定由一些正数(代表长度)组成的数组 A,返回由其中三个长度组成的、面积不为零的三角形的最大周长。
如果不能形成任何面积不为零的三角形,返回 0。
Example
示例 1:
输入:[2,1,2]
输出:5
示例 2:
输入:[1,2,1]
输出:0
示例 3:
输入:[3,2,3,4]
输出:10
示例 4:
输入:[3,6,2,3]
输出:8
提示:
3 <= A.length <= 10000
1 <= A[i] <= 10^6
Program
三角形中,较短的两条边之和必须大于第三条边。
1 | class Solution { |
400. 第N个数字
Description
在无限的整数序列 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …中找到第 n 个数字。
注意:
n 是正数且在32位整数范围内 ($n < 2^{31}$)。
Example
示例 1:
输入:
3
输出:
3
示例 2:
输入:
11
输出:
0
说明:
第11个数字在序列 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, … 里是0,它是10的一部分。
Program
$[0, 9]$ 这个区间,长度为9,每个数字只有1位,共有 $9 * 1$ 个数字
$[10, 99]$ 这个区间,长度为90,每个数字只有2位,共有 $90 * 2$ 个数字
$[100, 999]$ 这个区间,长度为900,每个数字只有3位,共有 $900 * 3$ 个数字
因此本题可以先得到数字所在的区间,然后再根据n和bit的关系找到具体的数字,最后在这个数字中找特定的那一位。
1 | class Solution { |
面试题67. 把字符串转换成整数
Description
写一个函数 StrToInt,实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0。
说明:
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 $[−2^{31}, 2^{31} − 1]$。如果数值超过这个范围,请返回 INT_MAX ($2^{31} − 1$) 或 INT_MIN ($−2^{31}$) 。
Example
示例 1:
输入: “42”
输出: 42
示例 2:
输入: “ -42”
输出: -42
解释: 第一个非空白字符为 ‘-‘, 它是一个负号。
我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。
示例 3:
输入: “4193 with words”
输出: 4193
解释: 转换截止于数字 ‘3’ ,因为它的下一个字符不为数字。
示例 4:
输入: “words and 987”
输出: 0
解释: 第一个非空字符是 ‘w’, 但它不是数字或正、负号。
因此无法执行有效的转换。
示例 5:
输入: “-91283472332”
输出: -2147483648
解释: 数字 “-91283472332” 超过 32 位有符号整数范围。
因此返回 INT_MIN ($−2^{31}$) 。
Program
1 | class Solution { |
面试题 16.05. 阶乘尾数
Description
设计一个算法,算出 n 阶乘有多少个尾随零。
Example
示例 1:
输入: 3
输出: 0
解释: 3! = 6, 尾数中没有零。
示例 2:
输入: 5
输出: 1
解释: 5! = 120, 尾数中有 1 个零.
说明: 你算法的时间复杂度应为 $O(log n)$ 。
Program
1、最初想到先把阶乘计算出来,再对结果进行处理,从而得到0的个数,但当计算完阶乘后,发现0的个数并不好获取。
2、之后考虑到,哪些数相乘会有零出现,也就是哪些数相乘会是10或10的倍数。也就得到2x5、4x5、6x5……会是10或10的倍数,也就是5和一个偶数相乘会得到10或10的倍数。
3、在数的阶乘中,偶数的个数明显多于5的个数,所以只要计算出阶乘中每个数的因数中5的个数,即可得到0的个数
4、所以只要计算在阶乘中是5的倍数的个数(包含一个5)、25的倍数的个数(包含两个5)、125的倍数的个数(包含3个5)…
1 | class Solution { |
面试题17. 打印从1到最大的n位数
Description
输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。
Example
示例 1:
输入: n = 1
输出: [1,2,3,4,5,6,7,8,9]
说明:
用返回一个整数列表来代替打印
n 为正整数
Program
1 | class Solution { |
593. 有效的正方形
Description
给定二维空间中四点的坐标,返回四点是否可以构造一个正方形。
一个点的坐标(x,y)由一个有两个整数的整数数组表示。
Example
示例:
输入: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1]
输出: True
注意:
所有输入整数都在 [-10000,10000] 范围内。
一个有效的正方形有四个等长的正长和四个等角(90度角)。
输入点没有顺序。
Program
有效的正方形,四条边相等,两条对角线长度也相等。计算这六个的长度,如果长度出现第三个不同值就说明不是正方形!当然也注意重点的情况!
1 | class Solution { |
553. 最优除法
Description
给定一组正整数,相邻的整数之间将会进行浮点除法操作。例如, [2,3,4] -> 2 / 3 / 4 。
但是,你可以在任意位置添加任意数目的括号,来改变算数的优先级。你需要找出怎么添加括号,才能得到最大的结果,并且返回相应的字符串格式的表达式。你的表达式不应该含有冗余的括号。
Example
示例:
输入: [1000,100,10,2]
输出: “1000/(100/10/2)”
解释:
1000/(100/10/2) = 1000/((100/10)/2) = 200
但是,以下加粗的括号 “1000/((100/10)/2)” 是冗余的,
因为他们并不影响操作的优先级,所以你需要返回 “1000/(100/10/2)”。
其他用例:
1000/(100/10)/2 = 50
1000/(100/(10/2)) = 50
1000/100/10/2 = 0.5
1000/100/(10/2) = 2
说明:
输入数组的长度在 [1, 10] 之间。
数组中每个元素的大小都在 [2, 1000] 之间。
每个测试用例只有一个最优除法解。
Program
分子不能变了,那么希望分母越小越好,当然是除了第一个外都整体做分子更好啦!
1 | class Solution { |
1362. 最接近的因数
Description
给你一个整数 num,请你找出同时满足下面全部要求的两个整数:
两数乘积等于 num + 1 或 num + 2
以绝对差进行度量,两数大小最接近
你可以按任意顺序返回这两个整数。
Example
示例 1:
输入:num = 8
输出:[3,3]
解释:对于 num + 1 = 9,最接近的两个因数是 3 & 3;对于 num + 2 = 10, 最接近的两个因数是 2 & 5,因此返回 3 & 3 。
示例 2:
输入:num = 123
输出:[5,25]
示例 3:
输入:num = 999
输出:[40,25]
提示:
1 <= num <= 10^9
Program
$[1,\sqrt{n}],[\sqrt{n}, n]$从$\sqrt{n}$开始搜索,一旦找到即是最小差的数!
注意:从$\sqrt{n}$到$1$开始搜索更好,因为$\frac{num}{\sqrt{n}}$不一定小于等于$\sqrt{n}$,例如1,2,3,如果从$\sqrt{n}$到$n$搜索,就会出问题。相反,从$\sqrt{n}$到$1$开始搜索,$\frac{num}{\sqrt{n}}$一定大于等于$\sqrt{n}$。
1 | class Solution { |
775. 全局倒置与局部倒置
Description
数组 A 是 [0, 1, …, N - 1] 的一种排列,N 是数组 A 的长度。全局倒置指的是 i,j 满足 $0 <= i < j < N$ 并且 A[i] > A[j] ,局部倒置指的是 i 满足 $0 <= i < N$ 并且 A[i] > A[i+1] 。
当数组 A 中全局倒置的数量等于局部倒置的数量时,返回 true 。
Example
示例 1:
输入: A = [1,0,2]
输出: true
解释: 有 1 个全局倒置,和 1 个局部倒置。
示例 2:
输入: A = [1,2,0]
输出: false
解释: 有 2 个全局倒置,和 1 个局部倒置。
注意:
A 是 [0, 1, …, A.length - 1] 的一种排列
A 的长度在 [1, 5000]之间
这个问题的时间限制已经减少了。
Program
①逆序对个数
全局倒置就是逆序对个数,用树状数组来求即可。
时间复杂度$O(n\log{n})$
1 | class Solution { |
②分析
全局倒置一定是局部倒置,反之不是。所以当数组中的数大于自身的索引+1或者小于自身的所以-1时就会出现2个以上的全局倒置,就不可能和局部倒置相等了
1 | class Solution { |
892. 三维形体的表面积
Description
在 N * N 的网格上,我们放置一些 1 * 1 * 1 的立方体。
每个值 v = grid[i][j] 表示 v 个正方体叠放在对应单元格 (i, j) 上。
请你返回最终形体的表面积。
Example
示例 1:
输入:[[2]]
输出:10
示例 2:
输入:[[1,2],[3,4]]
输出:34
示例 3:
输入:[[1,0],[0,2]]
输出:16
示例 4:
输入:[[1,1,1],[1,0,1],[1,1,1]]
输出:32
示例 5:
输入:[[2,2,2],[2,1,2],[2,2,2]]
输出:46
提示:
1 <= N <= 50
0 <= grid[i][j] <= 50
Program
思路:遍历每个位置的方块数,可以算出该柱体的表面积上下底+4*方块数,当然要减去重叠区面积,假设当前为(i,j)位置,则(i-1,j)和(i,j-1)已知,减去重叠区面积即可,那么(i+1,j)和(i,j+1)怎么办?其实也是已知的对应位置数量的,但是如果有重叠减一次就可以了,如果这两个位置都减去了重叠面积,那么后面计算的时候回重复减!所以只需要减(i-1,j)和(i,j-1)即可。
1 | class Solution { |
1317. 将整数转换为两个无零整数的和
Description
「无零整数」是十进制表示中 不含任何 0 的正整数。
给你一个整数 n,请你返回一个 由两个整数组成的列表 [A, B],满足:
- A 和 B 都是无零整数
- A + B = n
题目数据保证至少有一个有效的解决方案。
如果存在多个有效解决方案,你可以返回其中任意一个。
Example
示例 1:
输入:n = 2
输出:[1,1]
解释:A = 1, B = 1. A + B = n 并且 A 和 B 的十进制表示形式都不包含任何 0 。
示例 2:
输入:n = 11
输出:[2,9]
示例 3:
输入:n = 10000
输出:[1,9999]
示例 4:
输入:n = 69
输出:[1,68]
示例 5:
输入:n = 1010
输出:[11,999]
提示:
2 <= n <= 10^4
Program
1 | class Solution { |
面试题49. 丑数
Description
我们把只包含因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。
Example
示例:
输入: n = 10
输出: 12
解释: 1, 2, 3, 4, 5, 6, 8, 9, 10, 12 是前 10 个丑数。
说明:
1 是丑数。
n 不超过1690。
Program
动态规划
已知DP[1]…DP[i-1],求DP[i],前i-1个丑数是严格递增的,那么DP[i]为前i-1个丑数分别乘以2,3,5后得到的最小值!当然需要记录已存的值!
然而很遗憾超时了!!
1 | class Solution { |
进一步分析,很多重复计算!
比如已有1,2,3,4,5,计算下一个丑数的时候,需要都从1,2,3,4,5都乘2,3,5求最小值吗?
1×2,2×2,
1×3,
1×5
都已经在序列里了!重复计算了,当序列越来越长,重复计算将会更多。我们需要不重复且所得尽可能小的数!
对于因子2而言,就需要从3开始计算,
对于因子3而言,就需要从2开始计算,
对于因子5而言,就需要从2开始计算,
得到下一个丑数6
3×2==6,所以下一次对于因子2,将从4开始计算
2×3==6,所以下一次对于因子3,将从3开始计算,
2×5!=6,所以下一次对于因子5,还是从2开始计算。
采用三个索引p2,p3,p5
记录DP[p2]×2,DP[p3]×3,DP[p5]×5中最小的值minValue,其中DP[px] * x==minValue的索引自增!
1 | class Solution { |
869. 重新排序得到 2 的幂
Description
给定正整数 N ,我们按任何顺序(包括原始顺序)将数字重新排序,注意其前导数字不能为零。
如果我们可以通过上述方式得到 2 的幂,返回 true;否则,返回 false。
Example
示例 1:
输入:1
输出:true
示例 2:
输入:10
输出:false
示例 3:
输入:16
输出:true
示例 4:
输入:24
输出:false
示例 5:
输入:46
输出:true
提示:
1 <= N <= 10^9
Program
如果排列组合的话复杂度太高肯定超时,反过来如果枚举int范围的2的幂次,只有31个数,只需要比较十进制0~9每个数字的个数是否完全一样即可。
进一步来说,这31个数只有其十进制数的位数与N的位数相等才有可能满足!
1 | class Solution { |
1009. 十进制整数的反码
Description
每个非负整数 N 都有其二进制表示。例如, 5 可以被表示为二进制 “101”,11 可以用二进制 “1011” 表示,依此类推。注意,除 N = 0 外,任何二进制表示中都不含前导零。
二进制的反码表示是将每个 1 改为 0 且每个 0 变为 1。例如,二进制数 “101” 的二进制反码为 “010”。
给你一个十进制数 N,请你返回其二进制表示的反码所对应的十进制整数。
Example
示例 1:
输入:5
输出:2
解释:5 的二进制表示为 “101”,其二进制反码为 “010”,也就是十进制中的 2 。
示例 2:
输入:7
输出:0
解释:7 的二进制表示为 “111”,其二进制反码为 “000”,也就是十进制中的 0 。
示例 3:
输入:10
输出:5
解释:10 的二进制表示为 “1010”,其二进制反码为 “0101”,也就是十进制中的 5 。
提示:
0 <= N < 10^9
Program
1 | class Solution { |
1 | class Solution { |
1237. 找出给定方程的正整数解
Description
给出一个函数 f(x, y) 和一个目标结果 z,请你计算方程 f(x,y) == z 所有可能的正整数 数对 x 和 y。
给定函数是严格单调的,也就是说:
- f(x, y) < f(x + 1, y)
- f(x, y) < f(x, y + 1)
函数接口定义如下:如果你想自定义测试,你可以输入整数 function_id 和一个目标结果 z 作为输入,其中 function_id 表示一个隐藏函数列表中的一个函数编号,题目只会告诉你列表中的 2 个函数。1
2
3
4
5interface CustomFunction {
public:
// Returns positive integer f(x, y) for any given positive integer x and y.
int f(int x, int y);
};
你可以将满足条件的 结果数对 按任意顺序返回。
Example
示例 1:
输入:function_id = 1, z = 5
输出:[[1,4],[2,3],[3,2],[4,1]]
解释:function_id = 1 表示 f(x, y) = x + y
示例 2:
输入:function_id = 2, z = 5
输出:[[1,5],[5,1]]
解释:function_id = 2 表示 f(x, y) = x * y
提示:
1 <= function_id <= 9
1 <= z <= 100
题目保证 f(x, y) == z 的解处于 1 <= x, y <= 1000 的范围内。
在 1 <= x, y <= 1000 的前提下,题目保证 f(x, y) 是一个 32 位有符号整数。
Program
暴力
1 | /* |
伪双指针法
最后发现和两层循环没啥区别!每组xy都被考虑。。。
1 | /* |
双指针法
根据严格单调的特性:
令x=1,y=1000,
若f(x,y)<z,则计算f(x+1,,y)
若f(x,y)>z,则计算f(x,y-1)
若f(x,y)==z,则计算f(x+1,y-1)
时间复杂度:$O(m+n)$
确实巧妙,想了下这个算法的关键是找到合适的遍历起点,这个点肯定具有某种特殊性,这个二维矩阵,四个角就是四个特殊点,但他们的特点不同,左上和右下分别是矩阵的最小和最大值,左下和右上具有两面性,如果是所在行最大值那么就是所在列的最小值,反过来也一样。左上和右下与目标值比较不相等时,下一步既可以遍历行也可以遍历列是不确定的,而左下和右上是可以确定的,因为自身值的特点可以排除一个方向的路径,只有一个遍历路径。
1 | /* |
面试题20. 表示数值的字符串
Description
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串”+100”、”5e2”、”-123”、”3.1416”、”0123”都表示数值,但”12e”、”1a3.14”、”1.2.3”、”+-5”、”-1E-16”及”12e+5.4”都不是。
Program
如图,首先画图整个合法可能的数值字符串的最长状态(最长的那条直线轴),注意3和8:
(1)3为数字后有小数点
(2)8为小数点后前没有数字
(3)两种情况需要注意,因为3是合法的,8是不合法的!所以不能舍去8,直接连到3!
各个数字的状态:
0. 开始的空格
- 幂符号前的正负号
- 小数点前的数字
- 数字后的小数点或小数
- 数字后的e
- e后的正负号
- e后的数字
- 结尾的空格
- 数字前的小数点
详细说明请参考讲解1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Solution {
public:
vector<map<char,int>> states;
set<int> legalStates;
void init(){
states.resize(9);
states[0][' ']=0; states[0]['d']=2;states[0]['s']=1;states[0]['.']=8;
states[1]['.']=8;states[1]['d']=2;
states[2]['d']=2;states[2]['.']=3;states[2]['e']=4;states[2][' ']=7;
states[3]['d']=3;states[3]['e']=4;states[3][' ']=7;
states[4]['s']=5;states[4]['d']=6;
states[5]['d']=6;
states[6]['d']=6;states[6][' ']=7;
states[7][' ']=7;
states[8]['d']=3;
legalStates.insert(2);
legalStates.insert(3);
legalStates.insert(6);
legalStates.insert(7);
}
bool isNumber(string s) {
init();
int p=0; //当前状态
for(char ch:s){
if(ch>='0'&&ch<='9') ch='d';
else if(ch=='+'||ch=='-') ch='s';
// else ch=ch; //空格、dot、e以及其他非法字符
if(states[p].find(ch)==states[p].end()) return false; //出现非法字符
p = states[p][ch];
}
return (legalStates.find(p)!=legalStates.end());
}
};
908. 最小差值 I
Description
给你一个整数数组 A,对于每个整数 A[i],我们可以选择处于区间 [-K, K] 中的任意数 x ,将 x 与 A[i] 相加,结果存入 A[i] 。
在此过程之后,我们得到一些数组 B。
返回 B 的最大值和 B 的最小值之间可能存在的最小差值。
Example
示例 1:
输入:A = [1], K = 0
输出:0
解释:B = [1]
示例 2:
输入:A = [0,10], K = 2
输出:6
解释:B = [2,8]
示例 3:
输入:A = [1,3,6], K = 3
输出:0
解释:B = [3,3,3] 或 B = [4,4,4]
提示:
1 <= A.length <= 10000
0 <= A[i] <= 10000
0 <= K <= 10000
Program
思路:将数组排序,记最大值与最小值之间的差D,
如果D/2<=K,那么可以使得数组元素全相等!最小差值为0。因为任意选择[-K,K]区间的数进行加法,既然最大值/最小值都能够减/加上特定的数(这个数一定小于等于K)使二者相等,那么其他元素可以选择$[0,|K|]$中的数进行
如果D/2>K,则最小差值为D-2K。
所以answer=max(0,D-2K);
1 | class Solution { |
1447. 最简分数
Description
给你一个整数 n ,请你返回所有 0 到 1 之间(不包括 0 和 1)满足分母小于等于 n 的 最简 分数 。分数可以以 任意 顺序返回。
Example
1 | 示例 1: |
Program
1 | class Solution { |
868. 二进制间距
Description
给定一个正整数 N,找到并返回 N 的二进制表示中两个连续的 1 之间的最长距离。
如果没有两个连续的 1,返回 0 。
Example
示例 1:
输入:22
输出:2
解释:
22 的二进制是 0b10110 。
在 22 的二进制表示中,有三个 1,组成两对连续的 1 。
第一对连续的 1 中,两个 1 之间的距离为 2 。
第二对连续的 1 中,两个 1 之间的距离为 1 。
答案取两个距离之中最大的,也就是 2 。
示例 2:
输入:5
输出:2
解释:
5 的二进制是 0b101 。
示例 3:
输入:6
输出:1
解释:
6 的二进制是 0b110 。
示例 4:
输入:8
输出:0
解释:
8 的二进制是 0b1000 。
在 8 的二进制表示中没有连续的 1,所以返回 0 。
提示:
1 <= N <= 10^9
Program
两个连续1,是指二进制从低位到高位两个相邻1的距离!题目描述的恶心人。
1 | class Solution { |
598. 范围求和 II
Description
给定一个初始元素全部为 0,大小为 m * n 的矩阵 M 以及在 M 上的一系列更新操作。
操作用二维数组表示,其中的每个操作用一个含有两个正整数 a 和 b 的数组表示,含义是将所有符合 $0 <= i < a$ 以及 $0 <= j < b$ 的元素 M[i][j] 的值都增加 1。
在执行给定的一系列操作后,你需要返回矩阵中含有最大整数的元素个数。
Example
示例 1:
输入:
m = 3, n = 3
operations = [[2,2],[3,3]]
输出: 4
解释:
初始状态, M =
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
执行完操作 [2,2] 后, M =
[[1, 1, 0],
[1, 1, 0],
[0, 0, 0]]
执行完操作 [3,3] 后, M =
[[2, 2, 1],
[2, 2, 1],
[1, 1, 1]]
M 中最大的整数是 2, 而且 M 中有4个值为2的元素。因此返回 4。
注意:
m 和 n 的范围是 [1,40000]。
a 的范围是 [1,m],b 的范围是 [1,n]。
操作数目不超过 10000。
Program
二维树状数组
根据数据范围,二维树状数组和还是会超时
1 | class Solution { |
短板效应
其实题意转化一下,就是:求重叠部分的面积。阴影部分面积取决于宽度最小的和长度最小的
1 | class Solution { |
1037. 有效的回旋镖
Description
回旋镖定义为一组三个点,这些点各不相同且不在一条直线上。
给出平面上三个点组成的列表,判断这些点是否可以构成回旋镖。
Example
示例 1:
输入:[[1,1],[2,3],[3,2]]
输出:true
示例 2:
输入:[[1,1],[2,2],[3,3]]
输出:false
提示:
points.length == 3
points[i].length == 2
0 <= points[i][j] <= 100
Program
1 | class Solution { |
1 | class Solution { |
1017. 负二进制转换
Description
给出数字 N,返回由若干 “0” 和 “1”组成的字符串,该字符串为 N 的负二进制(base -2)表示。
除非字符串就是 “0”,否则返回的字符串中不能含有前导零。
Example
示例 1:
输入:2
输出:”110”
解释:(-2) ^ 2 + (-2) ^ 1 = 2
示例 2:
输入:3
输出:”111”
解释:(-2) ^ 2 + (-2) ^ 1 + (-2) ^ 0 = 3
示例 3:
输入:4
输出:”100”
解释:(-2) ^ 2 = 4
提示:
0 <= N <= 10^9
Program
一般基数为正数的方法,但需要特殊处理。
1 | class Solution { |
54. 螺旋矩阵
Description
给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
Example
示例 1:
输入:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
输出: [1,2,3,6,9,8,7,4,5]
示例 2:
输入:
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12]
]
输出: [1,2,3,4,8,12,11,10,9,5,6,7]
Program
1 | class Solution { |
885. 螺旋矩阵 III
Description
在 R 行 C 列的矩阵上,我们从 (r0, c0) 面朝东面开始
这里,网格的西北角位于第一行第一列,网格的东南角位于最后一行最后一列。
现在,我们以顺时针按螺旋状行走,访问此网格中的每个位置。
每当我们移动到网格的边界之外时,我们会继续在网格之外行走(但稍后可能会返回到网格边界)。
最终,我们到过网格的所有 R * C 个空间。
按照访问顺序返回表示网格位置的坐标列表。
Example
示例 1:
输入:R = 1, C = 4, r0 = 0, c0 = 0
输出:[[0,0],[0,1],[0,2],[0,3]]
示例 2:
输入:R = 5, C = 6, r0 = 1, c0 = 4
输出:[[1,4],[1,5],[2,5],[2,4],[2,3],[1,3],[0,3],[0,4],[0,5],[3,5],[3,4],[3,3],[3,2],[2,2],[1,2],[0,2],[4,5],[4,4],[4,3],[4,2],[4,1],[3,1],[2,1],[1,1],[0,1],[4,0],[3,0],[2,0],[1,0],[0,0]]
提示:
1 <= R <= 100
1 <= C <= 100
0 <= r0 < R
0 <= c0 < C
Program
1 | class Solution { |
1 | class Solution { |
789. 逃脱阻碍者
Description
你在进行一个简化版的吃豆人游戏。你从 (0, 0) 点开始出发,你的目的地是 (target[0], target[1]) 。地图上有一些阻碍者,第 i 个阻碍者从 (ghosts[i][0], ghosts[i][1]) 出发。
每一回合,你和阻碍者们可以同时向东,西,南,北四个方向移动,每次可以移动到距离原位置1个单位的新位置。
如果你可以在任何阻碍者抓住你之前到达目的地(阻碍者可以采取任意行动方式),则被视为逃脱成功。如果你和阻碍者同时到达了一个位置(包括目的地)都不算是逃脱成功。
当且仅当你有可能成功逃脱时,输出 True。
Example
示例 1:
输入:
ghosts = [[1, 0], [0, 3]]
target = [0, 1]
输出:true
解释:
你可以直接一步到达目的地(0,1),在(1, 0)或者(0, 3)位置的阻碍者都不可能抓住你。
示例 2:
输入:
ghosts = [[1, 0]]
target = [2, 0]
输出:false
解释:
你需要走到位于(2, 0)的目的地,但是在(1, 0)的阻碍者位于你和目的地之间。
示例 3:
输入:
ghosts = [[2, 0]]
target = [1, 0]
输出:false
解释:
阻碍者可以和你同时达到目的地。
说明:
所有的点的坐标值的绝对值 <= 10000。
阻碍者的数量不会超过 100。
Program
思路
看玩家与阻碍者谁先到目标点即可,题目可以四个方向走,也就是可以不走,只要阻碍者先到目标点守株待兔就行了。
1 | class Solution { |
843. 猜猜这个单词
Description
这个问题是 LeetCode 平台新增的交互式问题 。
我们给出了一个由一些独特的单词组成的单词列表,每个单词都是 6 个字母长,并且这个列表中的一个单词将被选作秘密。
你可以调用 master.guess(word) 来猜单词。你所猜的单词应当是存在于原列表并且由 6 个小写字母组成的类型字符串。
此函数将会返回一个整型数字,表示你的猜测与秘密单词的准确匹配(值和位置同时匹配)的数目。此外,如果你的猜测不在给定的单词列表中,它将返回 -1。
对于每个测试用例,你有 10 次机会来猜出这个单词。当所有调用都结束时,如果您对 master.guess 的调用不超过 10 次,并且至少有一次猜到秘密,那么您将通过该测试用例。
除了下面示例给出的测试用例外,还会有 5 个额外的测试用例,每个单词列表中将会有 100 个单词。这些测试用例中的每个单词的字母都是从 ‘a’ 到 ‘z’ 中随机选取的,并且保证给定单词列表中的每个单词都是唯一的。
Example
示例 1:
输入: secret = “acckzz”, wordlist = [“acckzz”,”ccbazz”,”eiowzz”,”abcczz”]
解释:
master.guess(“aaaaaa”) 返回 -1, 因为 “aaaaaa” 不在 wordlist 中.
master.guess(“acckzz”) 返回 6, 因为 “acckzz” 就是秘密,6个字母完全匹配。
master.guess(“ccbazz”) 返回 3, 因为 “ccbazz” 有 3 个匹配项。
master.guess(“eiowzz”) 返回 2, 因为 “eiowzz” 有 2 个匹配项。
master.guess(“abcczz”) 返回 4, 因为 “abcczz” 有 4 个匹配项。
我们调用了 5 次master.guess,其中一次猜到了秘密,所以我们通过了这个测试用例。
提示:任何试图绕过评判的解决方案都将导致比赛资格被取消。
Program
启发式极小化极大算法
显然,可行单词列表中的单词越少越好。如果数据随机,那么我们可以认定这个情况是普遍的。
现在,利用极小化极大算法猜测可行的单词列表。如果我们开始有 NN 个单词,我们通过迭代去选择可行单词。
算法
存储 H[i][j] 为 wordlist[i] 和 wordlist[j] 单词匹配数。每次猜测要求之前没有猜过,按照上面的说法实现极小化极大算法,每次选择猜测的单词是当前可行单词中的一个。
1 | /** |
913. 猫和老鼠
Description
两个玩家分别扮演猫(Cat)和老鼠(Mouse)在无向图上进行游戏,他们轮流行动。
该图按下述规则给出:graph[a] 是所有结点 b 的列表,使得 ab 是图的一条边。
老鼠从结点 1 开始并率先出发,猫从结点 2 开始且随后出发,在结点 0 处有一个洞。
在每个玩家的回合中,他们必须沿着与他们所在位置相吻合的图的一条边移动。例如,如果老鼠位于结点 1,那么它只能移动到 graph[1] 中的(任何)结点去。
此外,猫无法移动到洞(结点 0)里。
然后,游戏在出现以下三种情形之一时结束:
如果猫和老鼠占据相同的结点,猫获胜。
如果老鼠躲入洞里,老鼠获胜。
如果某一位置重复出现(即,玩家们的位置和移动顺序都与上一个回合相同),游戏平局。
给定 graph,并假设两个玩家都以最佳状态参与游戏,如果老鼠获胜,则返回 1;如果猫获胜,则返回 2;如果平局,则返回 0。
Example
示例:
输入:[[2,5],[3],[0,4,5],[1,4,5],[2,3],[0,2,3]]
输出:0
解释:
1 | 4---3---1 |
提示:
3 <= graph.length <= 200
保证 graph[1] 非空。
保证 graph[2] 包含非零元素。
Program
1 | using VI = vector<int>; |
面试题 16.07. 最大数值
Description
编写一个方法,找出两个数字a和b中最大的那一个。不得使用if-else或其他比较运算符。
Example
示例:
输入: a = 1, b = 2
输出: 2
Program
$[(a+b)+abs(a-b)]/2=max(a, b);$
$[(a+b)-abs(a-b)]/2=min(a, b);$
1 | class Solution { |
535. TinyURL 的加密与解密
Description
TinyURL是一种URL简化服务, 比如:当你输入一个URL https://leetcode.com/problems/design-tinyurl 时,它将返回一个简化的URL http://tinyurl.com/4e9iAk.
要求:设计一个 TinyURL 的加密 encode 和解密 decode 的方法。你的加密和解密算法如何设计和运作是没有限制的,你只需要保证一个URL可以被加密成一个TinyURL,并且这个TinyURL可以用解密方法恢复成原本的URL。
Program
原封不动
1 | class Solution { |
1 | class Solution { |
372. 超级次方
Description
你的任务是计算 a^b 对 1337 取模,a 是一个正整数,b 是一个非常大的正整数且会以数组形式给出。
Example
示例 1:
输入: a = 2, b = [3]
输出: 8
示例 2:
输入: a = 2, b = [1,0]
输出: 1024
Program
超时
1 | class Solution { |
快速幂
(1)$a^{[1,0,2,4]}=a^4 * (a^{1,0,2})^10$,所以递归求解;
(2)问题转化到$a^k$,二分:
- k为偶数,$a^k=a^{k/2} * a^{k/2}$;
- k为奇数,$a^k=a * a^{k-1}$;
- k为0,1;
(3)$(a * a)%MOD$可能溢出,可以转化为$((a%MOD) * (a%MOD))%MOD$;
证明:$a=Ak+c,b=Bk+d$
$(a * b)%k = (ABk^2+Adk+Bck+cd)%k=(cd)%k$
$((a%k) * (b%k))%k=(cd)%k$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
const int MOD=1337;
int mypow(int a, int k){
if(k==0) return 1;
// a%=MOD;
if(k%2==0){
int ans=mypow(a, k/2);
return ((ans%MOD) * (ans%MOD))%MOD;
}else{
int ans=mypow(a, k-1);
return ((ans)%MOD * (a%MOD))%MOD;
}
}
int superPow(int a, vector<int>& b) {
if(a==1||b.empty()) return 1;
int last=b.back();
b.pop_back();
int num1=mypow(a, last);
int num2=mypow(superPow(a, b), 10);
return ((num1%MOD) * (num2%MOD)) % MOD;
}
};1006. 笨阶乘
Description
通常,正整数 n 的阶乘是所有小于或等于 n 的正整数的乘积。例如,factorial(10) = 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1。
相反,我们设计了一个笨阶乘 clumsy:在整数的递减序列中,我们以一个固定顺序的操作符序列来依次替换原有的乘法操作符:乘法( * ),除法(/),加法(+)和减法(-)。
例如,clumsy(10) = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1。然而,这些运算仍然使用通常的算术运算顺序:我们在任何加、减步骤之前执行所有的乘法和除法步骤,并且按从左到右处理乘法和除法步骤。
另外,我们使用的除法是地板除法(floor division),所以 10 * 9 / 8 等于 11。这保证结果是一个整数。
实现上面定义的笨函数:给定一个整数 N,它返回 N 的笨阶乘。
Example
示例 1:
输入:4
输出:7
解释:7 = 4 * 3 / 2 + 1
示例 2:
输入:10
输出:12
解释:12 = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1
提示:
1 <= N <= 10000
-2^31 <= answer <= 2^31 - 1 (答案保证符合 32 位整数。)
Program
1 | class Solution { |
478. 在圆内随机生成点
Description
给定圆的半径和圆心的 x、y 坐标,写一个在圆中产生均匀随机点的函数 randPoint 。
说明:
输入值和输出值都将是浮点数。
圆的半径和圆心的 x、y 坐标将作为参数传递给类的构造函数。
圆周上的点也认为是在圆中。
randPoint 返回一个包含随机点的x坐标和y坐标的大小为2的数组。
Example
示例 1:
输入:
[“Solution”,”randPoint”,”randPoint”,”randPoint”]
[[1,0,0],[],[],[]]
输出: [null,[-0.72939,-0.65505],[-0.78502,-0.28626],[-0.83119,-0.19803]]
示例 2:
输入:
[“Solution”,”randPoint”,”randPoint”,”randPoint”]
[[10,5,-7.5],[],[],[]]
输出: [null,[11.52438,-8.33273],[2.46992,-16.21705],[11.13430,-12.42337]]
输入语法说明:
输入是两个列表:调用成员函数名和调用的参数。Solution 的构造函数有三个参数,圆的半径、圆心的 x 坐标、圆心的 y 坐标。randPoint 没有参数。输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
Program
思路
考虑在圆心为原点的半径为题给r的圆上随机产生点,答案即平移后的结果。
圆:$x^2+y^2\leq r^2$
即$x^2+y^2= random() * r^2$,其中random()产生[0,1]的随机数
转成极坐标:
$\rho^2=random() * r^2,即\rho=\sqrt{random()} * r$
角度也是随机的:$\theta=random() * 2 \pi$
平移后坐标:$x=\rho * \cos\theta + x_{center}, y=\rho * \sin\theta + y_{center}.$
1 | class Solution { |
645. 错误的集合
Description
集合 S 包含从1到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复。
给定一个数组 nums 代表了集合 S 发生错误后的结果。你的任务是首先寻找到重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
Example
示例 1:
输入: nums = [1,2,2,4]
输出: [2,3]
注意:
给定数组的长度范围是 [2, 10000]。
给定的数组是无序的。
Program
1 | class Solution { |
592. 分数加减运算
Description
给定一个表示分数加减运算表达式的字符串,你需要返回一个字符串形式的计算结果。 这个结果应该是不可约分的分数,即最简分数。 如果最终结果是一个整数,例如 2,你需要将它转换成分数形式,其分母为 1。所以在上述例子中, 2 应该被转换为 2/1。
Example
示例 1:
输入:”-1/2+1/2”
输出: “0/1”
示例 2:
输入:”-1/2+1/2+1/3”
输出: “1/3”
示例 3:
输入:”1/3-1/2”
输出: “-1/6”
示例 4:
输入:”5/3+1/3”
输出: “2/1”
说明:
输入和输出字符串只包含 ‘0’ 到 ‘9’ 的数字,以及 ‘/‘, ‘+’ 和 ‘-‘。
输入和输出分数格式均为 ±分子/分母。如果输入的第一个分数或者输出的分数是正数,则 ‘+’ 会被省略掉。
输入只包含合法的最简分数,每个分数的分子与分母的范围是 [1,10]。 如果分母是1,意味着这个分数实际上是一个整数。
输入的分数个数范围是 [1,10]。
最终结果的分子与分母保证是 32 位整数范围内的有效整数。
Program
1 | class Solution { |
剑指 Offer 59 - I. 滑动窗口的最大值
Description
给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
Example
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
1 | 滑动窗口的位置 最大值 |
提示:
你可以假设 k 总是有效的,在输入数组不为空的情况下,1 ≤ k ≤ 输入数组的大小。
Program
保持双端队列首位为最大值,队列降序排列!
一个窗口中,较小的数在前面可以剔除,因为后续窗口移动过程中,一定不会是它为窗口最大值。
1 | class Solution { |
1390. 四因数
Description
给你一个整数数组 nums,请你返回该数组中恰有四个因数的这些整数的各因数之和。
如果数组中不存在满足题意的整数,则返回 0 。
Example
示例:
输入:nums = [21,4,7]
输出:32
解释:
21 有 4 个因数:1, 3, 7, 21
4 有 3 个因数:1, 2, 4
7 有 2 个因数:1, 7
答案仅为 21 的所有因数的和。
提示:
1 <= nums.length <= 10^4
1 <= nums[i] <= 10^5
Program
暴力
时间复杂度:$O(n * \sqrt{n})$
1 | class Solution { |
预处理

时间还没第一种块。
1 | class Solution { |
838. 推多米诺
Description
一行中有 N 张多米诺骨牌,我们将每张多米诺骨牌垂直竖立。
在开始时,我们同时把一些多米诺骨牌向左或向右推。
每过一秒,倒向左边的多米诺骨牌会推动其左侧相邻的多米诺骨牌。
同样地,倒向右边的多米诺骨牌也会推动竖立在其右侧的相邻多米诺骨牌。
如果同时有多米诺骨牌落在一张垂直竖立的多米诺骨牌的两边,由于受力平衡, 该骨牌仍然保持不变。
就这个问题而言,我们会认为正在下降的多米诺骨牌不会对其它正在下降或已经下降的多米诺骨牌施加额外的力。
给定表示初始状态的字符串 “S” 。如果第 i 张多米诺骨牌被推向左边,则 S[i] = ‘L’;如果第 i 张多米诺骨牌被推向右边,则 S[i] = ‘R’;如果第 i 张多米诺骨牌没有被推动,则 S[i] = ‘.’。
返回表示最终状态的字符串。
Example
示例 1:
输入:”.L.R…LR..L..”
输出:”LL.RR.LLRRLL..”
示例 2:
输入:”RR.L”
输出:”RR.L”
说明:第一张多米诺骨牌没有给第二张施加额外的力。
提示:
0 <= N <= 10^5
表示多米诺骨牌状态的字符串只含有 ‘L’,’R’; 以及 ‘.’;
Program
两个新串l_str,r_str分别仅记录左推和右推后的结果,则结果字符串res为:
(1)l_str[i]==r_str[i],即初试R或L的位置或者无作用力的’.’;
(2)l_str[i]==L&&r_str[i]==R,表示受两边R和L的作用,得到整个区间,res在该区间左半部分为R,右半部分为L,中间(奇数)为’.’;
(3)l_str[i]==’L’&&r_str[i]==’.’,res[i]=L;
(4)l_str[i]==’.’&&r_str[i]==’R’,res[i]=R;
1 | class Solution { |
面试题 17.09. 第 k 个数
Description
有些数的素因子只有 3,5,7,请设计一个算法找出第 k 个数。注意,不是必须有这些素因子,而是必须不包含其他的素因子。例如,前几个数按顺序应该是 1,3,5,7,9,15,21。
Example
示例 1:
输入: k = 5
输出: 9
Program
思路:
每次希望产生较小的数作为第i个数,且要求没有重复计算,很自然采用三指针。
1 | class Solution { |
1015. 可被 K 整除的最小整数
Description
给定正整数 K,你需要找出可以被 K 整除的、仅包含数字 1 的最小正整数 N。
返回 N 的长度。如果不存在这样的 N,就返回 -1。
Example
示例 1:
输入:1
输出:1
解释:最小的答案是 N = 1,其长度为 1。
示例 2:
输入:2
输出:-1
解释:不存在可被 2 整除的正整数 N 。
示例 3:
输入:3
输出:3
解释:最小的答案是 N = 111,其长度为 3。
提示:
1 <= K <= 10^5
Program
正常思路为:
1 | while(x%K!=0){ |
由于容易溢出,所以得想想办法:
$x_i=ak+b$
$x_{i+1}*10+1=10ak+b+1$
即$x_i \mod k=b$,
$x_{i+1} \mod k=(b+1) \mod k=(x_i \mod k+1) \mod k$
所以求$x_{i+1}$时,我们只需要$x_i$的一部分$b$来组成$x_{i+1}$可以避免溢出,因为$0<k<10^5$,所以不会溢出。
另外注意$k=2或k=5$一定不会有答案,因为这两个数作为因子,所得的数个位一定不会为1!
1 | class Solution { |
1175. 质数排列
Description
请你帮忙给从 1 到 n 的数设计排列方案,使得所有的「质数」都应该被放在「质数索引」(索引从 1 开始)上;你需要返回可能的方案总数。
让我们一起来回顾一下「质数」:质数一定是大于 1 的,并且不能用两个小于它的正整数的乘积来表示。
由于答案可能会很大,所以请你返回答案 模 mod 10^9 + 7 之后的结果即可。
Example
示例 1:
输入:n = 5
输出:12
解释:举个例子,[1,2,5,4,3] 是一个有效的排列,但 [5,2,3,4,1] 不是,因为在第二种情况里质数 5 被错误地放在索引为 1 的位置上。
示例 2:
输入:n = 100
输出:682289015
提示:
1 <= n <= 100
Program
欧拉筛选/阶乘/排列组合
首先计算[1,n]内质数个数k,则结果为:
$k! * (n-k)!$
而如何求质数个数呢?
欧拉筛选:时间复杂度$O(n)$
总的时间复杂度:$O(n)$
1 | class Solution { |
640. 求解方程
Description
求解一个给定的方程,将x以字符串”x=#value”的形式返回。该方程仅包含’+’,’ - ‘操作,变量 x 和其对应系数。
如果方程没有解,请返回“No solution”。
如果方程有无限解,则返回“Infinite solutions”。
如果方程中只有一个解,要保证返回值 x 是一个整数。
Example
示例 1:
输入: “x+5-3+x=6+x-2”
输出: “x=2”
示例 2:
输入: “x=x”
输出: “Infinite solutions”
示例 3:
输入: “2x=x”
输出: “x=0”
示例 4:
输入: “2x+3x-6x=x+2”
输出: “x=-1”
示例 5:
输入: “x=x+2”
输出: “No solution”
Program
1 | class Solution { |
970. 强整数
Description
给定两个正整数 x 和 y,如果某一整数等于 x^i + y^j,其中整数 i >= 0 且 j >= 0,那么我们认为该整数是一个强整数。
返回值小于或等于 bound 的所有强整数组成的列表。
你可以按任何顺序返回答案。在你的回答中,每个值最多出现一次。
Example
示例 1:
输入:x = 2, y = 3, bound = 10
输出:[2,3,4,5,7,9,10]
解释:
2 = 2^0 + 3^0
3 = 2^1 + 3^0
4 = 2^0 + 3^1
5 = 2^1 + 3^1
7 = 2^2 + 3^1
9 = 2^3 + 3^0
10 = 2^0 + 3^2
示例 2:
输入:x = 3, y = 5, bound = 15
输出:[2,4,6,8,10,14]
提示:
1 <= x <= 100
1 <= y <= 100
0 <= bound <= 10^6
Program
思路
注意特判x,y为1的情况,因为1的任何次方都为1.
最坏时间复杂度:$O((\log_{2}{n})^2)$,其中n为bound的范围
1 | class Solution { |
面试题 01.05. 一次编辑
Description
字符串有三种编辑操作:插入一个字符、删除一个字符或者替换一个字符。 给定两个字符串,编写一个函数判定它们是否只需要一次(或者零次)编辑。
Example
示例 1:
输入:
first = “pale”
second = “ple”
输出: True
示例 2:
输入:
first = “pales”
second = “pal”
输出: False
Program
思路
双指针,p1,p2分别表示长串和短串的指针
(1)两字符串相等,满足题意
(2)两字符串长度相差大于等于2,不满足题意
(3)两字符串长度相差1:
①first[p1]==second[p2],俩指针自增1;
②否则,如果俩字符串长度相等,则替换操作,isOpt=true,俩指针自增1;
③否则,即俩子串长度不等,则添加操作(删除与添加等价),isOpt=true, p1自增,p2不变;(如果采用删除而不是添加也一样,p1自增,p2不变)
④在整个过程中如果有isOpt==true,则说明已经编辑了一次,如果还需要编辑,则不满足题意,直接返回false.
1 | class Solution { |
441. 排列硬币
Description
你总共有 n 枚硬币,你需要将它们摆成一个阶梯形状,第 k 行就必须正好有 k 枚硬币。
给定一个数字 n,找出可形成完整阶梯行的总行数。
n 是一个非负整数,并且在32位有符号整型的范围内。
Example
示例 1:
n = 5
硬币可排列成以下几行:
1 | ¤ |
因为第三行不完整,所以返回2.
示例 2:
n = 8
硬币可排列成以下几行:
1 | ¤ |
因为第四行不完整,所以返回3.
Program
1 | class Solution { |
1 | class Solution { |
215. 数组中的第K个最大元素
Description
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
Example
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
。
Program
库函数
1 | class Solution { |
快排
1 | class Solution { |
堆排序
1 | class Solution { |
剑指 Offer 09. 用两个栈实现队列
Description
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
Example
示例 1:
输入:
[“CQueue”,”appendTail”,”deleteHead”,”deleteHead”]
[[],[3],[],[]]
输出:[null,null,3,-1]
示例 2:
输入:
[“CQueue”,”deleteHead”,”appendTail”,”appendTail”,”deleteHead”,”deleteHead”]
[[],[],[5],[2],[],[]]
输出:[null,-1,null,null,5,2]
提示:
1 <= values <= 10000
最多会对 appendTail、deleteHead 进行 10000 次调用
Program
1 | class CQueue { |
350. 两个数组的交集 II
Description
给定两个数组,编写一个函数来计算它们的交集。
Example
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2]
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9]
说明:
输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。
我们可以不考虑输出结果的顺序。
进阶:
如果给定的数组已经排好序呢?你将如何优化你的算法?
如果 nums1 的大小比 nums2 小很多,哪种方法更优?
如果 nums2 的元素存储在磁盘上,磁盘内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
Program
排序
排序后,双指针,更小的右移,相同的加入结果集。
时间复杂度:$O(n\log{n}+m\log{m})$
1 | class Solution { |
哈希表
哈希表记录短的数组。
时间复杂度:$O(m+n)$
1 | class Solution { |
1337. 方阵中战斗力最弱的 K 行
Description
给你一个大小为 m * n 的方阵 mat,方阵由若干军人和平民组成,分别用 1 和 0 表示。
请你返回方阵中战斗力最弱的 k 行的索引,按从最弱到最强排序。
如果第 i 行的军人数量少于第 j 行,或者两行军人数量相同但 i 小于 j,那么我们认为第 i 行的战斗力比第 j 行弱。
军人 总是 排在一行中的靠前位置,也就是说 1 总是出现在 0 之前。
Example
示例 1:
输入:mat =
[[1,1,0,0,0],
[1,1,1,1,0],
[1,0,0,0,0],
[1,1,0,0,0],
[1,1,1,1,1]],
k = 3
输出:[2,0,3]
解释:
每行中的军人数目:
行 0 -> 2
行 1 -> 4
行 2 -> 1
行 3 -> 2
行 4 -> 5
从最弱到最强对这些行排序后得到 [2,0,3,1,4]
示例 2:
输入:mat =
[[1,0,0,0],
[1,1,1,1],
[1,0,0,0],
[1,0,0,0]],
k = 2
输出:[0,2]
解释:
每行中的军人数目:
行 0 -> 1
行 1 -> 4
行 2 -> 1
行 3 -> 1
从最弱到最强对这些行排序后得到 [0,2,3,1]
提示:
m == mat.length
n == mat[i].length
2 <= n, m <= 100
1 <= k <= m
matrix[i][j] 不是 0 就是 1
Program
1 | class Solution { |
415. 字符串相加
Description
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和。
注意:
num1 和num2 的长度都小于 5100.
num1 和num2 都只包含数字 0-9.
num1 和num2 都不包含任何前导零。
你不能使用任何內建 BigInteger 库, 也不能直接将输入的字符串转换为整数形式。
Program
1 | class Solution { |
1291. 顺次数
Description
我们定义「顺次数」为:每一位上的数字都比前一位上的数字大 1 的整数。
请你返回由 [low, high] 范围内所有顺次数组成的 有序 列表(从小到大排序)。
Example
示例 1:
输出:low = 100, high = 300
输出:[123,234]
示例 2:
输出:low = 1000, high = 13000
输出:[1234,2345,3456,4567,5678,6789,12345]
提示:
10 <= low <= high <= 10^9
Program
1 | class Solution { |
1 | class Solution { |
867. 转置矩阵
Description
给定一个矩阵 A, 返回 A 的转置矩阵。
矩阵的转置是指将矩阵的主对角线翻转,交换矩阵的行索引与列索引。
Example
示例 1:
输入:[[1,2,3],[4,5,6],[7,8,9]]
输出:[[1,4,7],[2,5,8],[3,6,9]]
示例 2:
输入:[[1,2,3],[4,5,6]]
输出:[[1,4],[2,5],[3,6]]
提示:
1 <= A.length <= 1000
1 <= A[0].length <= 1000
Program
1 | class Solution { |
347. 前 K 个高频元素
Description
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
Example
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
你可以按任意顺序返回答案。
Program
1 | class Solution { |
1705. 吃苹果的最大数目
Description
有一棵特殊的苹果树,一连 n 天,每天都可以长出若干个苹果。在第 i 天,树上会长出 apples[i] 个苹果,这些苹果将会在 days[i] 天后(也就是说,第 i + days[i] 天时)腐烂,变得无法食用。也可能有那么几天,树上不会长出新的苹果,此时用 apples[i] == 0 且 days[i] == 0 表示。
你打算每天 最多 吃一个苹果来保证营养均衡。注意,你可以在这 n 天之后继续吃苹果。
给你两个长度为 n 的整数数组 days 和 apples ,返回你可以吃掉的苹果的最大数目。
Example
示例 1:
输入:apples = [1,2,3,5,2], days = [3,2,1,4,2]
输出:7
解释:你可以吃掉 7 个苹果:
- 第一天,你吃掉第一天长出来的苹果。
- 第二天,你吃掉一个第二天长出来的苹果。
- 第三天,你吃掉一个第二天长出来的苹果。过了这一天,第三天长出来的苹果就已经腐烂了。
- 第四天到第七天,你吃的都是第四天长出来的苹果。
示例 2:
输入:apples = [3,0,0,0,0,2], days = [3,0,0,0,0,2]
输出:5
解释:你可以吃掉 5 个苹果:
- 第一天到第三天,你吃的都是第一天长出来的苹果。
- 第四天和第五天不吃苹果。
- 第六天和第七天,你吃的都是第六天长出来的苹果。
提示:
apples.length == n
days.length == n
1 <= n <= 2 * 10^4
0 <= apples[i], days[i] <= 2 * 10^4
只有在 apples[i] = 0 时,days[i] = 0 才成立
Program
思路
优先吃更早腐烂过期的苹果
1 | class Solution { |
1706. 球会落何处
Description
用一个大小为 m x n 的二维网格 grid 表示一个箱子。你有 n 颗球。箱子的顶部和底部都是开着的。
箱子中的每个单元格都有一个对角线挡板,跨过单元格的两个角,可以将球导向左侧或者右侧。
将球导向右侧的挡板跨过左上角和右下角,在网格中用 1 表示。
将球导向左侧的挡板跨过右上角和左下角,在网格中用 -1 表示。
在箱子每一列的顶端各放一颗球。每颗球都可能卡在箱子里或从底部掉出来。如果球恰好卡在两块挡板之间的 “V” 形图案,或者被一块挡导向到箱子的任意一侧边上,就会卡住。
返回一个大小为 n 的数组 answer ,其中 answer[i] 是球放在顶部的第 i 列后从底部掉出来的那一列对应的下标,如果球卡在盒子里,则返回 -1 。
Example
示例 1:
输入:grid = [[1,1,1,-1,-1],[1,1,1,-1,-1],[-1,-1,-1,1,1],[1,1,1,1,-1],[-1,-1,-1,-1,-1]]
输出:[1,-1,-1,-1,-1]
解释:示例如图:
b0 球开始放在第 0 列上,最终从箱子底部第 1 列掉出。
b1 球开始放在第 1 列上,会卡在第 2、3 列和第 1 行之间的 “V” 形里。
b2 球开始放在第 2 列上,会卡在第 2、3 列和第 0 行之间的 “V” 形里。
b3 球开始放在第 3 列上,会卡在第 2、3 列和第 0 行之间的 “V” 形里。
b4 球开始放在第 4 列上,会卡在第 2、3 列和第 1 行之间的 “V” 形里。
示例 2:
输入:grid = [[-1]]
输出:[-1]
解释:球被卡在箱子左侧边上。
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 100
grid[i][j] 为 1 或 -1
Program
思路
广搜,状态节点:
i,j球的位置,diag网格(i,j)的挡板方向,pos球在网格(i,j)的上/下(1/0,上表示与上边相连,下表示与下边相连);
1 | class Solution { |

